Week 2: Elevate your Spark Game - Exploring Higher Level APIs! 📈
 Mehul Kansal
Mehul Kansal
Introduction
Hey there, data enthusiasts! This week, we will explore the power of Spark's higher level APIs - Dataframes and Spark SQL. Let's begin using Spark like a pro and unveil the enhanced data processing capabilities of this dynamic duo.
Task 1: Understanding Dataframes and Spark SQL
In the last week's blog, we learnt that RDDs consist of raw data distributed across partitions, but without any structure associated to it. Since a structure (metadata) is provided to the spark engine in case of higher level APIs, it has more context to handle the data effectively, hence resulting in higher level APIs being more performant. Unlike RDDs, in Apache Spark we have:
Dataframes: These exist in the form of RDDs with some metadata associated to them, the data being stored in memory and the metadata in a temporary metadata catalog. Dataframes are not persistent and are only available in a particular session.
Spark SQL / Spark Table: These exist in the form of data files that are stored on the disk and their associated metadata is stored in a metastore (database). Spark tables are persistent across different sessions.
Task 2: Working of Dataframes
Dataframes work in the following three steps:
Load the file containing data, thus creating a dataframe
Apply any transformations required
Write the resulting dataframe back to storage
Spark Session acts as an entry point to the spark cluster in case of higher level APIs like dataframes. It is analogous to Spark Context which serves as an entry point for lower level RDDs.
We call a read attribute on the spark session that we have created, in order to get a spark dataframe reader.
In addition, we provide configurations specifying the way in which we want to read the format of the file.

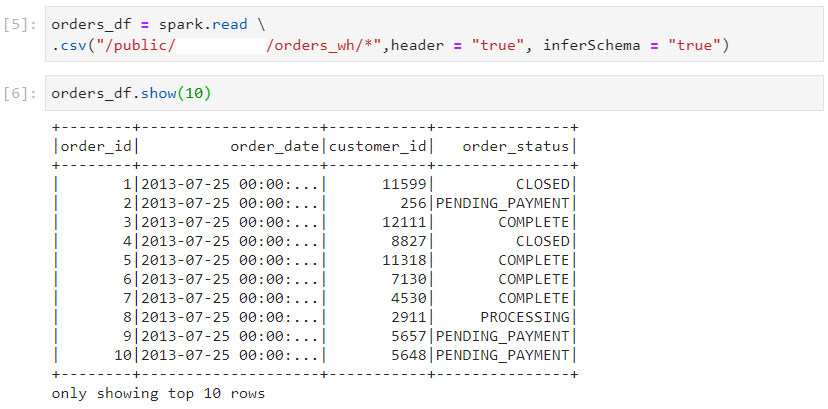
- Since we have used inferSchema attribute, the dataframe takes additional execution time to infer the schema, which may not certainly be correct. For these reasons, it is a good practice to avoid inferSchema configuration.
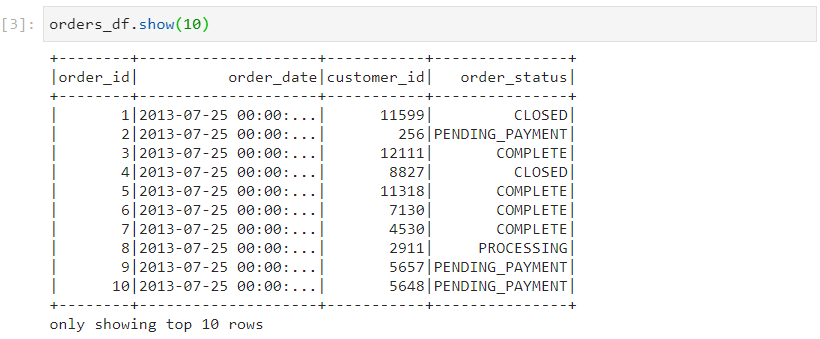
- Here, the data type for order_date column is inferred as a string. But, we want it to be a timestamp.

- For achieving the desired data type for order_date, we add a new column named order_date_new, with the help of withColumn transformation.
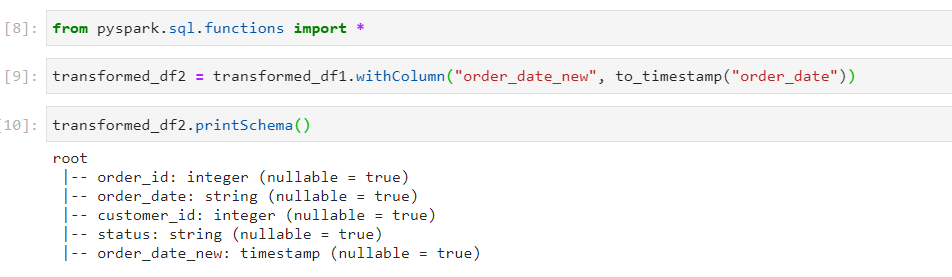
Task 3: Understanding Dataframe Reader
The way we created the dataframe above, is the standard way of creating it. Additionally, there are some alternative shortcuts to create dataframes for different file formats.
- csv file format
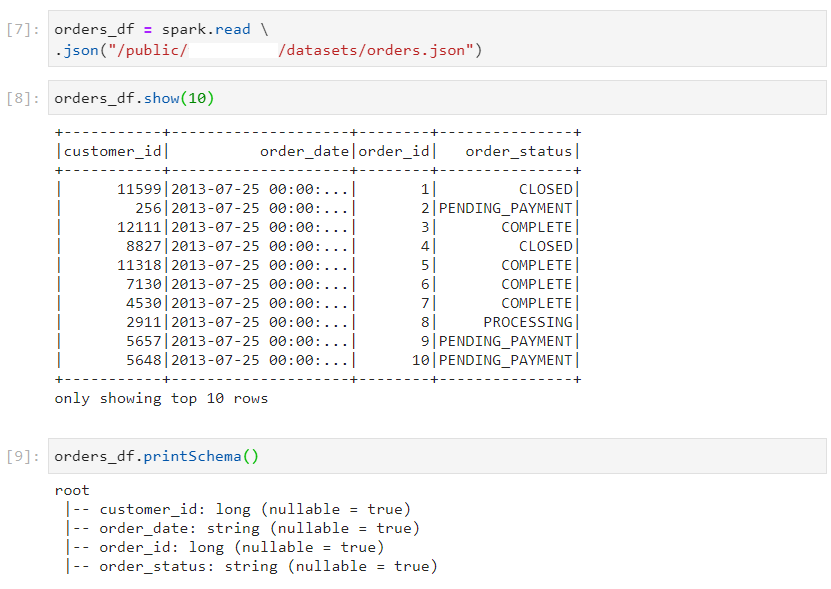
- json file format
- parquet file format
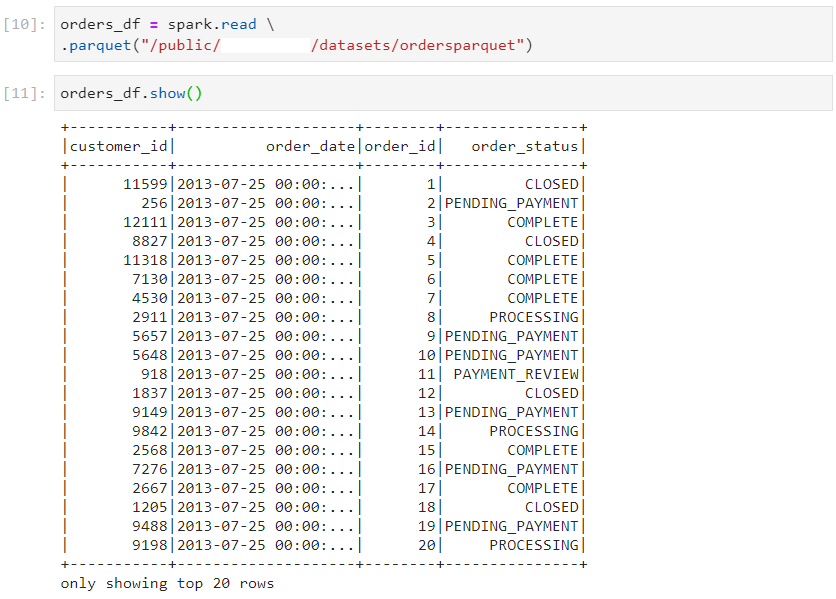
- orc file format
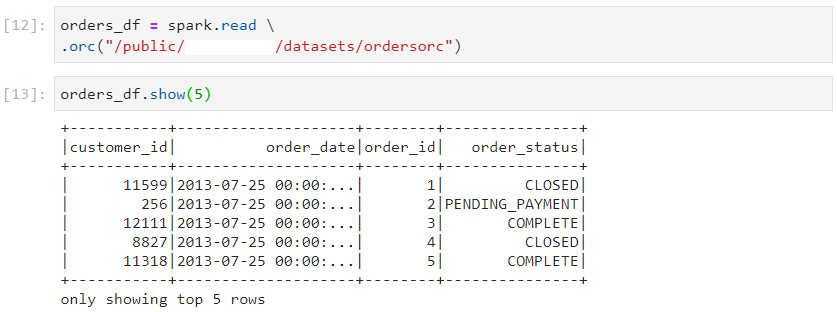
- Transformations work equally well with dataframes loaded in this manner.
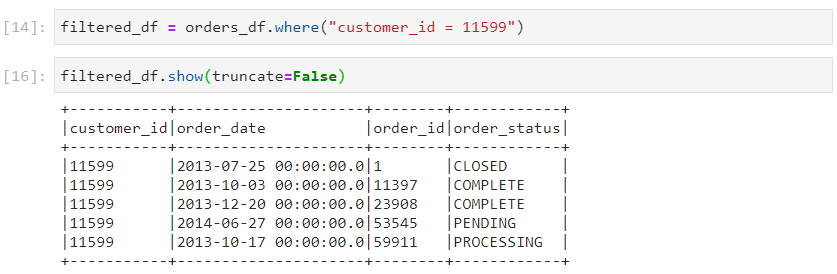
Task 4: Dataframes and Spark SQL table
Interestingly, dataframes and Spark SQL tables are interconvertible.
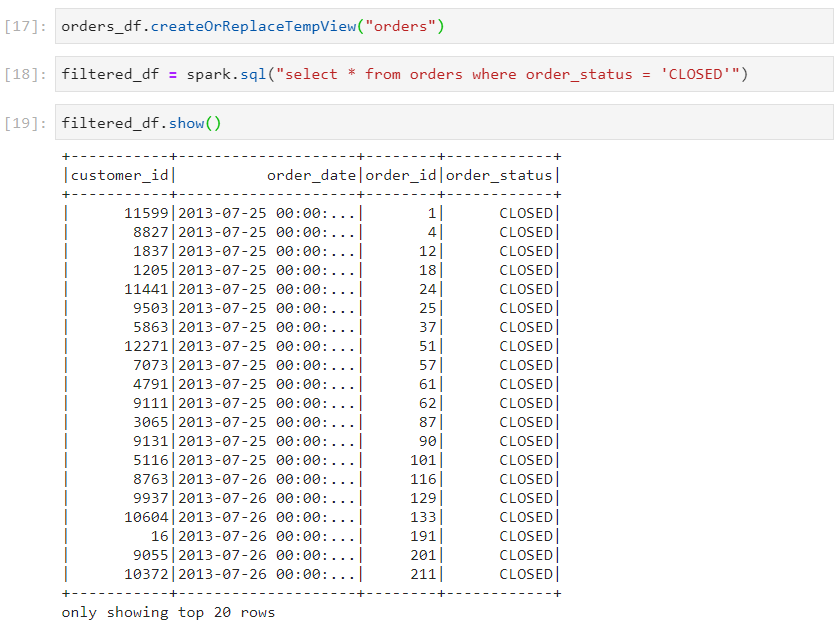
We can create a Spark SQL table from an existing dataframe, using the function createOrReplaceTempView.
Thereafter, we can execute SQL queries on the SparkSQL table view, as we normally do.
- A SparkSQL table can be converted into a Dataframe using the following syntax:
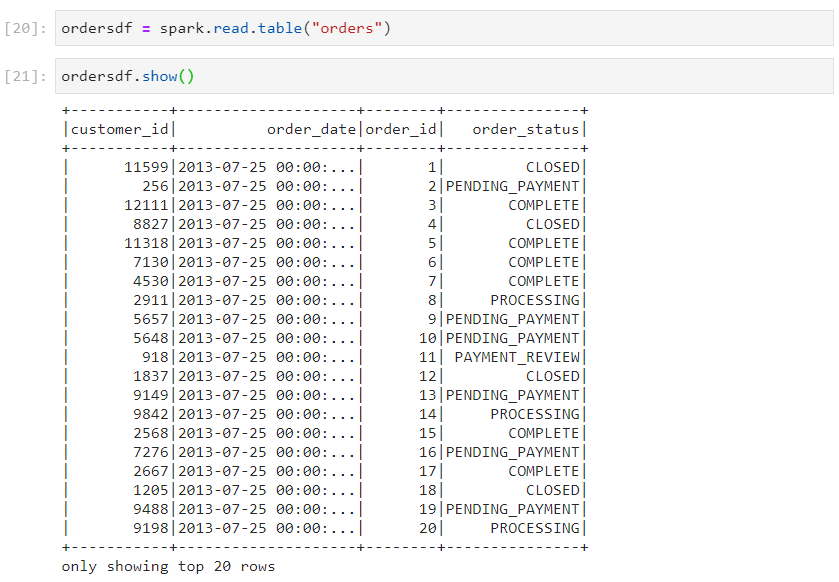
Other alternatives to create a SparkSQL table from a dataframe also exist:
createOrReplaceTempView: This function either creates the table or replaces the already existing table without throwing any error.
createTempView: It creates a new table but, if the table with the given name already exists, it throws an error stating that the table already exists.
createGlobalTempView: The global table created will be visible across other applications as well.
createOrReplaceGlobalTempView: As the name suggests, this function replaces the already existing table, if any, with the new table view.

Task 5: Creating a Spark Table
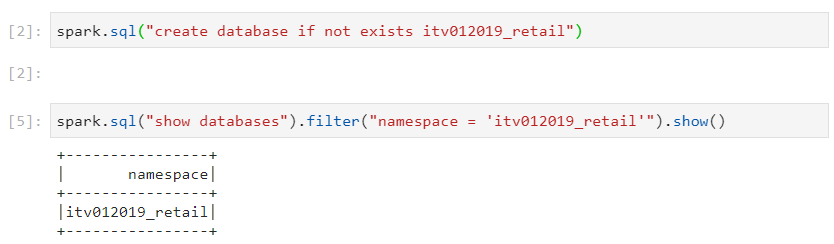
- By default, if a table is created at the very outset, it gets associated to the Default Database. For avoiding this scenario, we first create our own database.
- For creating the table, we use the usual SQL syntax, but inside spark.sql().
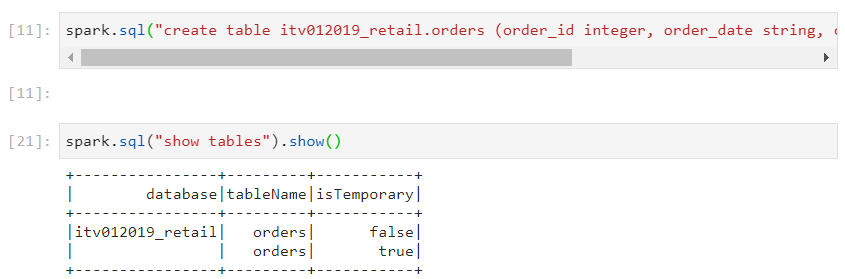
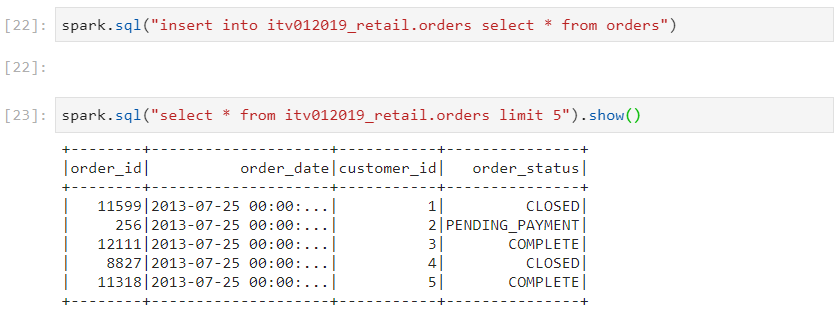
Use case: Consider a scenario where we have a temporary table, created using createTempView with some data residing in it (orders). We need to persist this data into a persistent table in the database (itv012019_retail.orders).
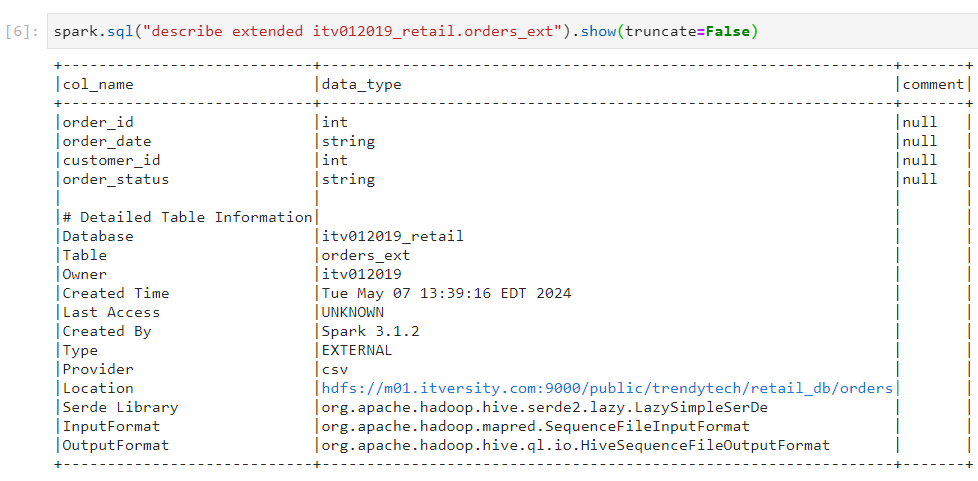
- We execute the following command to view the extended description of the table that we have just created.
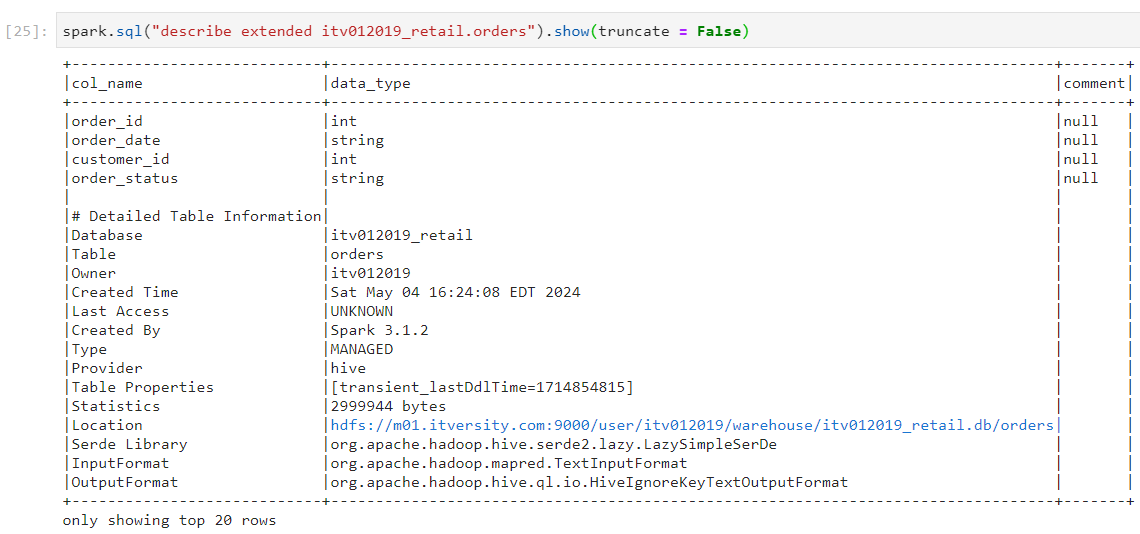
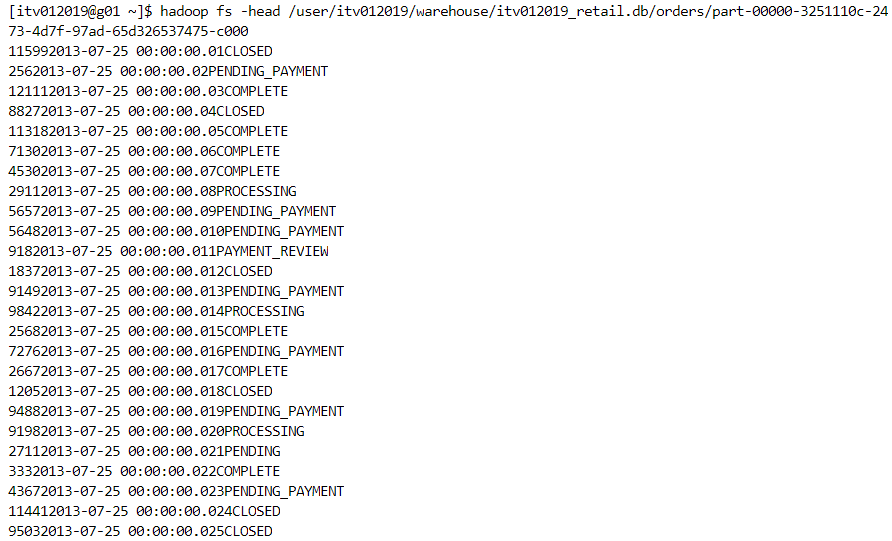
- As we can see above, this table is a managed table, the metadata for which is shown through describe command. The actual data of this table resides at the location mentioned above. It looks like this:
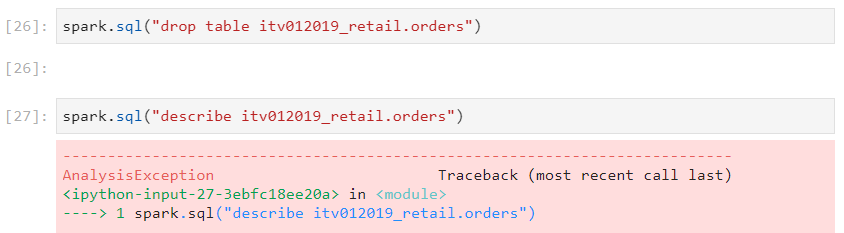
- Notably, if the managed table is dropped, then both the metadata and the actual data get deleted.

External Tables
In case of external tables, the data is already present in a specific location and a structure needs to be created for getting a tabular view.
Interestingly, if the external table is dropped, only the metadata is dropped and the actual data remains untouched.
We use the following syntax in order to create an external table:
spark.sql("create table itv012019_retail.orders \ (order_id integer, order_date string, customer_id integer, \ order_status string) using csv location \ '/public/retail_db/orders'")
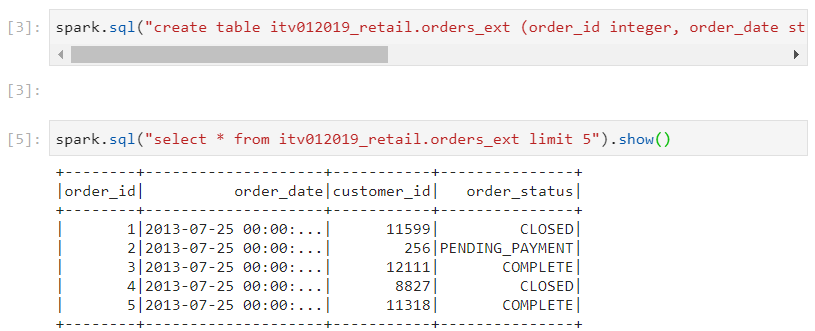
- Note that if multiple users require access to the data kept at a centralized location, then external tables are ideal. The users just reuse the data by applying the schema on the existing data, while the data itself remains intact.
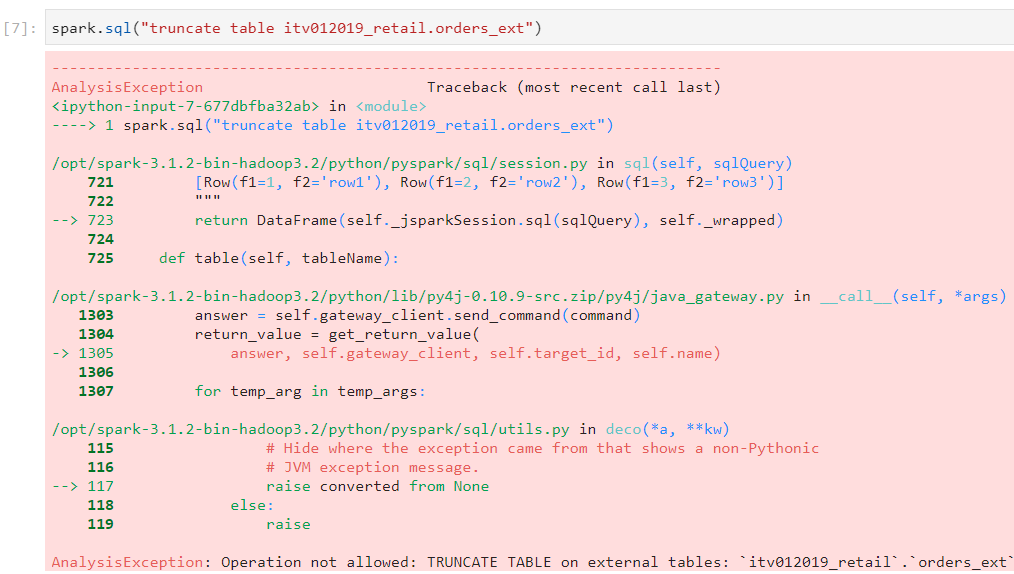
- In open source Apache Spark, only insert and select statements can be executed on tables. Other DML operations like update and delete don't work.
Task 6: Working with Spark SQL API vs Dataframe API
Consider the following dataframe and Spark SQL table.

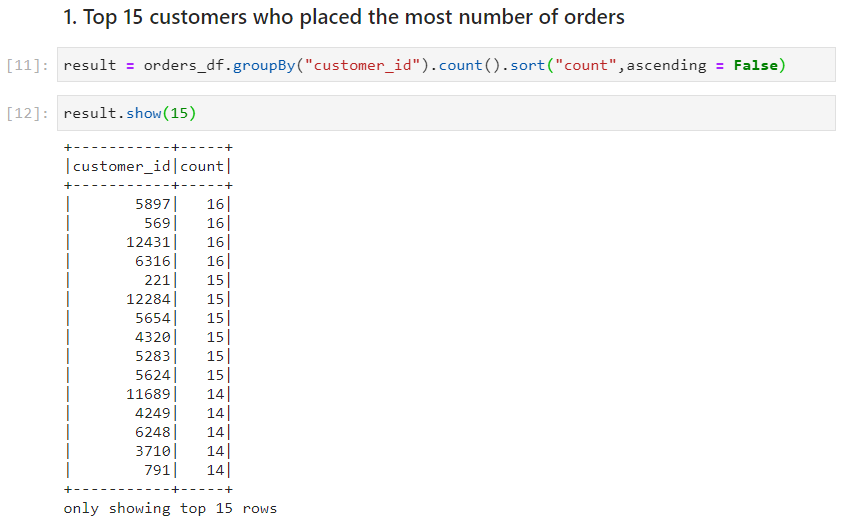
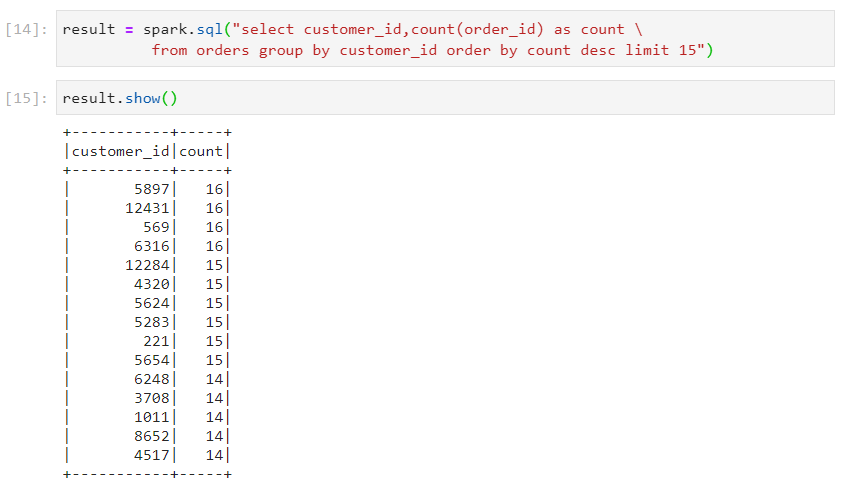
Use case 1: Top 15 customers who placed the most number of orders
- With dataframe
- With SparkSQL
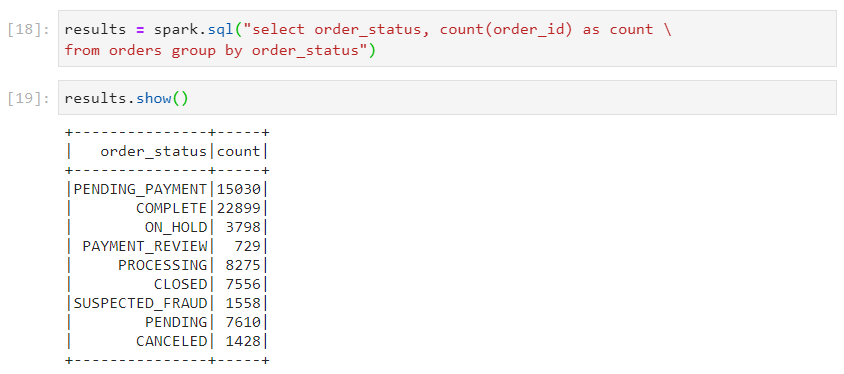
Use case 2: Find the number of orders under each order status
- With dataframe
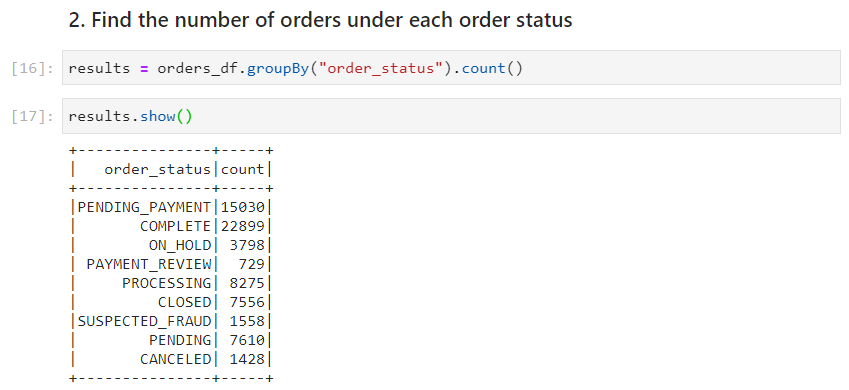
- With SparkSQL
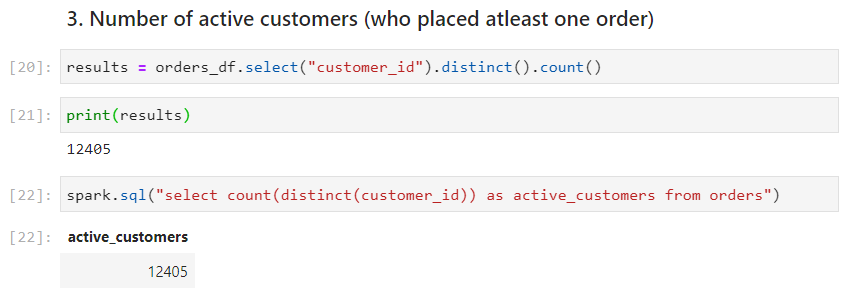
Use case 3: Number of active customers (customers who have placed at least one order)
- With dataframe and SparkSQL respectively
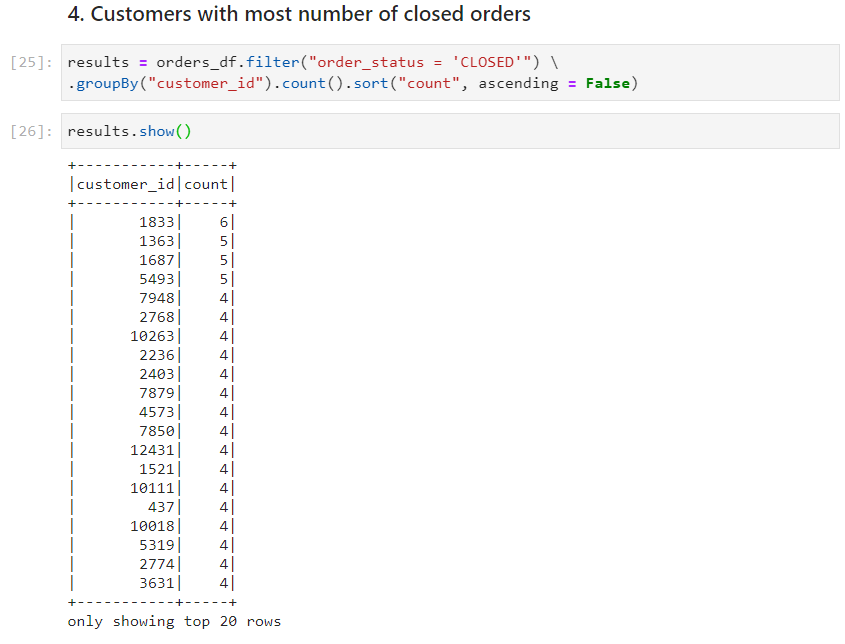
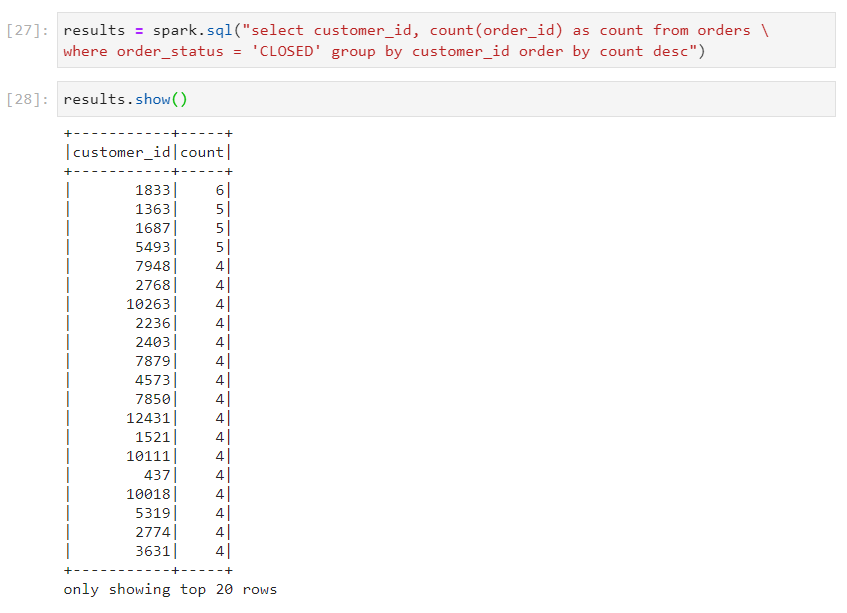
Use case 4: Customers with most number of closed orders
- With dataframe
- With SparkSQL
Conclusion
By performing these tasks, we have gained great insights into using Dataframes and Spark SQL. We've learnt about transformations, reading different file formats, conversion of dataframes into Spark SQL tables and vice-versa, dealing with Spark table DML operations, managed and external tables, and much more.
Stay tuned for more exciting data engineering aspects ahead!
Subscribe to my newsletter
Read articles from Mehul Kansal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by