NVIDIA H100 vs H200: A Detailed Comparison
 Spheron Network
Spheron Network
NVIDIA's H200 GPU is generating significant excitement in the AI community, offering notably higher memory capacity—approximately two times more than its predecessor, the H100. These GPUs share the robust Hopper architecture, tailored for managing extensive AI and HPC responsibilities efficiently.
Upon its introduction, the NVIDIA H100 brought about a major shift in AI performance standards. As we look forward to the arrival of the H200 in 2024, curiosity intensifies around the degree of advancement it will offer beyond the H100's achievements. Delving deeper into their respective architectural aspects and Nvidia's sneak peeks of the H200 enables us to gauge the potential performance enhancement for end-users.
NVIDIA H100 architecture and specification
The NVIDIA H100 is NVIDIA's most powerful and programmable GPU to date, featuring several architectural enhancements, such as higher GPU core frequencies and greater computational power compared to its predecessor, the A100.
The H100 introduces a new Streaming Multiprocessor (SM), which handles various tasks within the GPU architecture, including:
Executing CUDA threads, which are the fundamental units of execution in NVIDIA's programming model.
Performing traditional floating-point computations (FP32, FP64).
Incorporating specialized cores, like Tensor Cores.
The H100 SM can perform Matrix Multiply-Accumulate (MMA) operations twice as fast as the A100 for the same data types. Additionally, it delivers four times the performance boost over the A100 SM for floating-point operations. This is achieved through two key advancements:
FP8 Data Type: The H100 introduces a new data format (FP8), which uses 8 bits compared to the A100's standard FP32 (32 bits), allowing faster calculations with slightly reduced precision.
Improved SM Architecture: The H100 SM is inherently twice as powerful for traditional data types (FP32, FP64) due to internal architectural enhancements.
Is H100 the best GPU?
Upon its release, the NVIDIA H100 is regarded as the top GPU for AI and HPC workloads, thanks to its advanced architecture, extensive memory bandwidth, and exceptional AI acceleration capabilities. It is specifically designed for large-scale deep learning, scientific computing, and data analytics. However, the "best" GPU can vary based on specific use cases, budgets, and compatibility needs.
The H100 features fourth-generation Tensor Cores, significantly improving performance over the previous generation A100.
Additionally, the H100 introduces a new transformer engine tailored to accelerate the training and inference of transformer models, which is essential for Natural Language Processing (NLP). This engine combines software optimizations with Hopper Tensor Cores to achieve substantial speedups.
The engine dynamically switches between two data precision formats (FP8 and FP16) for faster calculations with minimal accuracy loss, automatically handling conversions between these formats within the model for optimal performance.
The H100 transformer engine provides up to 9x faster AI training and 30x faster AI inference speeds on large language models than the A100.
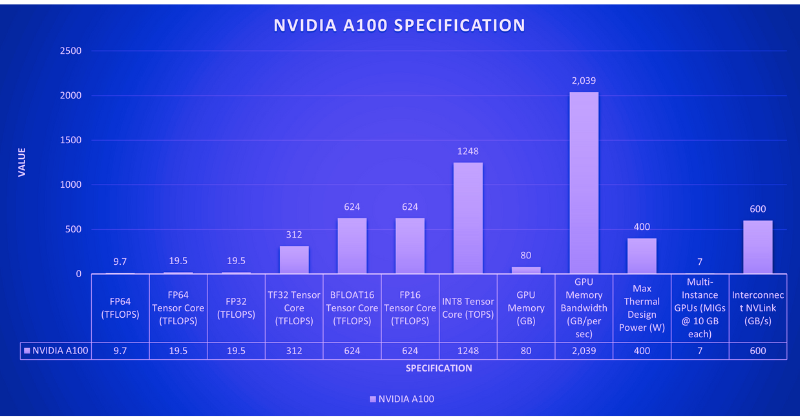
The NVIDIA H100's powerful NVLink Network Interconnect enables communication between up to 256 GPUs across multiple to compute nodes, making it ideal for handling massive datasets and complex problems. Secure MIG technology allows the GPU to be partitioned into secure, right-sized instances, optimizing the quality of service for smaller workloads.
The NVIDIA H100 is the first truly asynchronous GPU capable of overlapping data movement with computations to maximize overall computational efficiency. This capability ensures that the GPU can perform data transfers in parallel with processing tasks, reducing idle times and enhancing the throughput of AI and high-performance computing (HPC) workloads. Efficiency is further improved with the Tensor Memory Accelerator (TMA), which optimizes memory management on the GPU. By streamlining memory operations, the TMA reduces the CUDA threads needed to manage memory bandwidth, freeing more CUDA threads for core computations.
Another innovation is the Thread Block Cluster, which groups multiple threads to enable efficient cooperation and data sharing across multiple processing units within the H100. This extends to asynchronous operations, ensuring efficient TMA and Tensor Cores use. Additionally, the H100 introduces a new Asynchronous Transaction Barrier to streamline communication between different processing units. This feature allows threads and accelerators to synchronize efficiently, even when located on separate chip parts.
NVIDIA H100 vs H200 Benchmarks
In our previous benchmarks of the NVIDIA H100, we covered its memory specifications and other features. In this article, we will turn our attention to the NVIDIA H200.
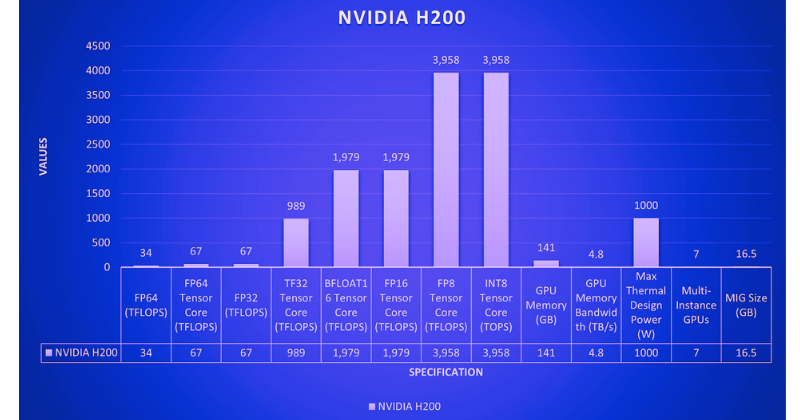
As impressive as the H100 is, the H200 takes its capabilities even further. It is the first GPU to feature HBM3e memory, boasting a memory capacity of 141 GB, nearly double that of the H100. This increased memory size is crucial for AI, allowing larger models and datasets to be stored directly on the GPU, thus reducing latency associated with data transfer. The H200 also offers 4.8 TB/s of memory bandwidth, a significant improvement over the H100's 3.35 TB/s, enabling much faster data transfer to the processing cores, which is essential for high-throughput workloads.
For memory-intensive HPC tasks such as weather modeling, the H200's superior memory bandwidth facilitates more efficient data flow between the GPU memory and processing cores, reducing bottlenecks and shortening time to insights. The reported up to 110x performance increase in HPC tasks highlights the H200's potential to handle highly complex simulations, allowing researchers and engineers to achieve more in less time.
| Specification | NVIDIA H100 SXM | NVIDIA H200 |
| Form Factor | SXM | SXM |
| FP64 | 34 TFLOPS | 34 TFLOPS |
| FP64 Tensor Core | 67 TFLOPS | 67 TFLOPS |
| FP32 | 67 TFLOPS | 67 TFLOPS |
| TF32 Tensor Core | 989 TFLOPS | 989 TFLOPS |
| BFLOAT16 Tensor Core | 1,979 TFLOPS | 1,979 TFLOPS |
| FP16 Tensor Core | 1,979 TFLOPS | 1,979 TFLOPS |
| FP8 Tensor Core | 3,958 TFLOPS | 3,958 TFLOPS |
| INT8 Tensor Core | 3,958 TOPS | 3,958 TOPS |
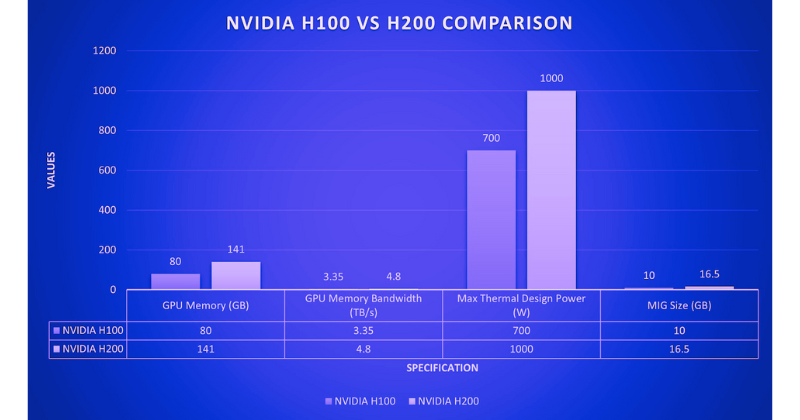
| GPU Memory | 80GB | 141GB |
| GPU Memory Bandwidth | 3.35TB/s | 4.8 TB/s |
| Decoders | 7 NVDEC, 7 JPEG | 7 NVDEC, 7 JPEG |
| Max Thermal Design Power | Up to 700W | Up to 1000W |
| Multi-Instance GPUs | Up to 7 MIGs @ 10GB each | Up to 7 MIGs @ 16.5GB each |
| Interconnect | NVLink: 900GB/s, PCIe Gen5: 128GB/s | NVLink: 900GB/s, PCIe Gen5: 128GB/s |
The H200 matches the H100 in performance metrics for FP64 and FP32 operations, with no differences in FP8 and INT8 performance, achieving 3,958 TFLOPS. This remains impressive, as INT8 precision balances computational efficiency and model accuracy, making it ideal for edge devices with limited computational resources.
The H200 delivers enhanced performance while maintaining the same energy consumption levels as the H100. By reducing energy use for LLM tasks by 50% and doubling the memory bandwidth, it effectively reduces its total cost of ownership (TCO) by 50%.
How much faster is H200 vs H100?
The NVIDIA H200 GPU surpasses the H100, offering up to 45% more performance in specific generative AI and HPC (High Performance Computing) benchmarks. This improvement is primarily due to the H200's increased memory capacity with HBM3e, greater memory bandwidth, and optimizations in thermal management. The extent of performance enhancement can vary based on particular workloads and configurations.
NVIDIA H100 vs H200 MLPerf Inference Benchmarks
Let's examine how the NVIDIA H100 compares to the NVIDIA H200 in MLPerf inference analysis. MLPerf benchmarks are industry-standard tests designed to assess the performance of machine learning hardware, software, and services across different platforms and environments. They offer a reliable measure for comparing the efficiency and speed of machine learning solutions, helping users identify the best tools and technologies for their AI and ML projects.
Developers of advanced AI models need to test their creations. Inference is crucial in allowing Large Language Models (LLMs) to comprehend new, unseen data. When presented with unfamiliar information, inference enables the model to grasp the context, intent, and relationships within the data based on its training. The model then generates tokens (such as words) sequentially.
During inference, the LLM leverages the context obtained and the previously generated tokens to predict the next element in the sequence. This process enables the LLM to generate comprehensive outputs, whether translating a sentence, crafting various forms of creative text, or providing comprehensive answers to questions.
In comparing the H100 and the H200 in handling inference tasks, we look at the number of tokens each can generate within a specific timeframe. This approach provides a practical metric for evaluating their performance, particularly in tasks related to natural language processing.
According to the MLPerf Inference v4.0 performance benchmarks for the Llama 2 70B model, the H100 achieves a throughput of 22,290 tokens/second in offline scenarios. In contrast, the H200 achieves a throughput of 31,712 tokens/second for the same scenarios, showcasing a significant performance increase.
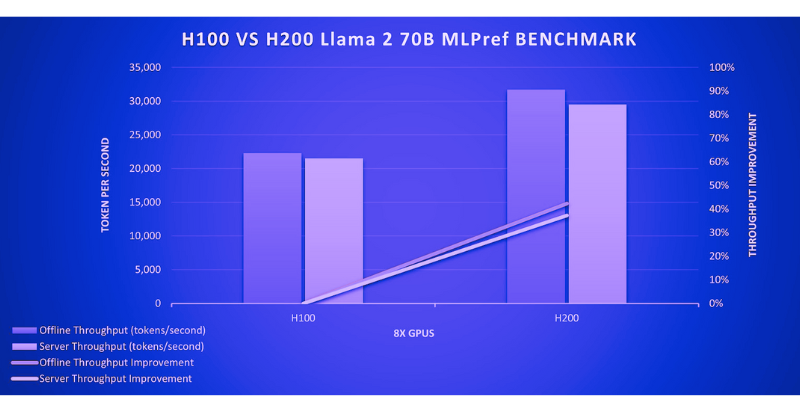
In server scenarios, the H100 achieves a throughput of 21,504 tokens/second, while the H200 reaches 29,526 tokens/second. This demonstrates that the H200 delivers a 37% increase in throughput compared to the H100 in server scenarios, representing a significant performance improvement. Additionally, a notable increase in performance was observed in offline scenarios.
| GPU | Offline Throughput (tokens/second) | Throughput Improvement | Server Throughput (tokens/second) | Throughput Improvement |
| H100 | 22,290 | - | 21,504 | - |
| H200 | 31,712 | +42.4% | 29,526 | +37.3% |
The reasons for this can be summarized as follows:
Memory and Bandwidth Boost of H200:
The H200 boasts larger memory (141GB) and higher bandwidth (4.8 TB/s) compared to the H100, approximately 1.8 and 1.4 times, respectively. This enables the H200 to accommodate larger data sizes, reducing the need for constant fetching of data from slower external memory. The increased bandwidth facilitates faster data transfer between memory and GPU. As a result, the H200 can handle substantial tasks without resorting to complex techniques like tensor parallelism or pipeline parallelism.
Improved Inference Throughput of H200:
The absence of memory and communication bottlenecks allows the H200 to allocate more processing power to computations, resulting in faster inference. Benchmarks conducted on the Llama test demonstrate this advantage, with the H200 achieving up to a 28% improvement even at the same power level (700W TDP) as the H100.
Performance Gains of H200:
Benchmarks indicate that the H200 delivers up to a 45% performance improvement on the Llama test compared to the H100 when power consumption is configured to 1000W. These comparisons underscore the technological advancements and performance enhancements achieved with the H200 GPU over the H100, particularly in managing the demands of generative AI inference workloads like Llama 2 70B, through greater memory capacity, higher memory bandwidth, and improved thermal management.
Join Spheron's Private Testnet and Get Complimentary Credits for your Projects
As a developer, you now have the opportunity to build on Spheron's cutting-edge technology using free credits during our private testnet phase. This is your chance to experience the benefits of decentralized computing firsthand at no cost to you.
If you're an AI researcher, deep learning expert, machine learning professional, or large language model enthusiast, we want to hear from you! Participating in our private testnet will give you early access to Spheron's robust capabilities and receive complimentary credits to help bring your projects to life.
Don't miss out on this exciting opportunity to revolutionize how you develop and deploy applications. Sign up now by filling out this form: https://b4t4v7fj3cd.typeform.com/to/Jp58YQB2
Join us in pushing the boundaries of what's possible with decentralized computing. We look forward to working with you!
Subscribe to my newsletter
Read articles from Spheron Network directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Spheron Network
Spheron Network
On-demand DePIN for GPU Compute