A toy problem and a bunch of models
 RJ Honicky
RJ Honicky
I have a ton of ideas bouncing around in my head about interesting things to do with or to LLMs and other types of models. I've been using a children's story co-authoring and publishing tool (https://github.com/honicky/story-time and https://www.storytime.glass/) as a toy project to learn about generative AI. One thing I've discovered is that consistency across images (Sora notwithstanding) is a tough problem. This actually matters quite a bit in a children's story since so much of the story is told visually.
One idea I've had some success with is to use identical language in image prompts for each character and location. The story generator first generates a story and then generates an image prompt for each paragraph to go along with the text (checking out an example at https://www.storytime.glass/ might help here). This means that I need to be able to identify all of the characters in the story, and also the characters in a give paragraph and image.
Since my god-model story generator is pretty slow, the app is difficult to interact with right now. That sounds like an excuse to learn about the best, fastest, cheapest way to figure out who are the characters in a story and a scene. I could obviously ask GPT-4o or claude-3-opus who are the characters in the story, but
the generation loop is already slow and
where's the fun in that?
In this post, I will play around with several options for extracting the character names from stories and paragraphs, including a 60M parameter BERT-based NER model (more below), all the way to my own fine-tuned flan-t5. I have links to notebooks for each experiment.
TL;DR
In case you're mostly just interested in the results, skip to the bottom with the table and graphs. The nutshell: haiku is the top performer, and my flan-t5-large fine-tune is the fastest, and also the lowest cost, but only if we assume 50% occupancy on the GPU, which is a high bar to cross.
The space to explore
There are a few dimensions across which I would like to understand the behavior of different models. As I have done the experiments below, I've had as many new questions as answers. I've limited myself to a few representative examples, so this is obviously not a rigorous survey, but its enough to get a feel for how different models behave with this problem
Architecture
I find it most useful to think about the different Transfomer-based LLMs in terms of their input and output during training and inference. In very broad strokes, Transfomer-based LLMs come in three main flavors
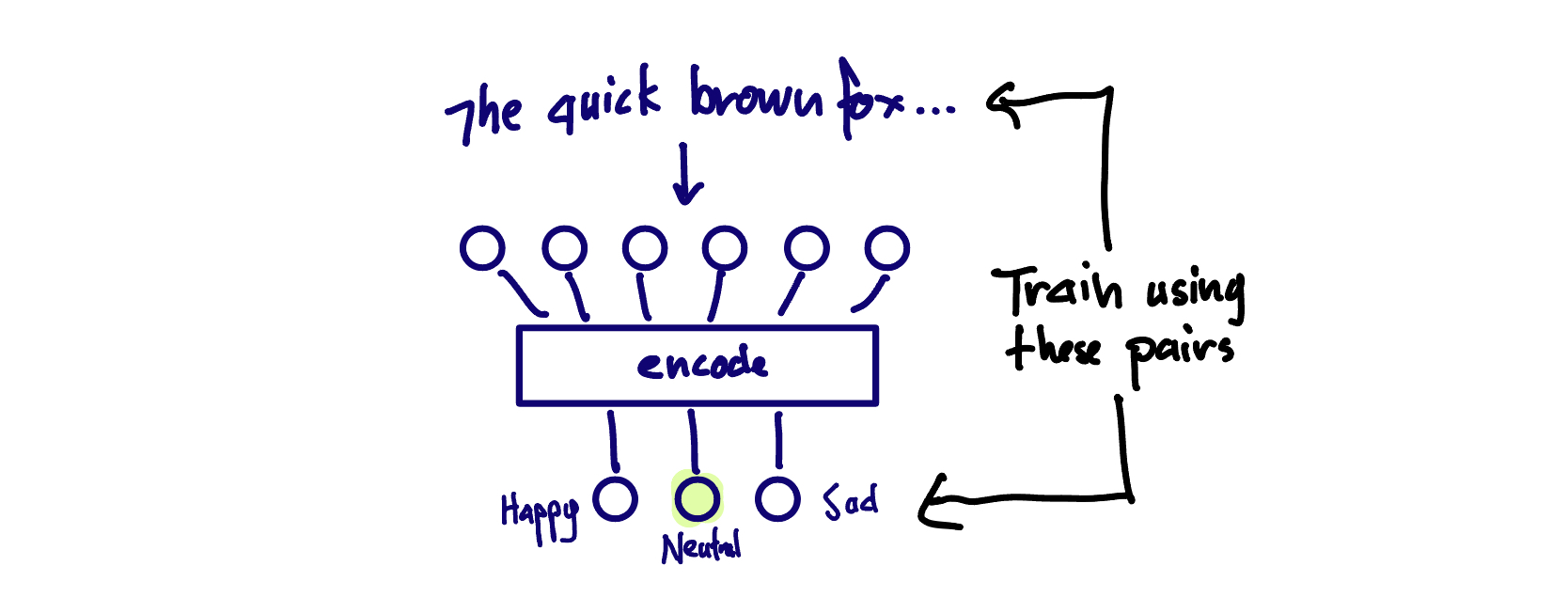
encoder-only - BERT is an encoder-only model. These models take in text and output a fixed set of probabilities. Exactly what those probabilities mean, how many of them there are, etc. depends on the specific problem they are designed to solve. With BERT, you can replace the last layer of the network with a layer that is appropriate for your problem (and then fine tune it). For example, if you were classifying text into three categories, then maybe you would have three output nodes, one representing each class. In our case we will have one output node per input-token, per class of token (is it part of a name?). The key characteristic of this type of model is that the output is a fixed, pre-determined number of numerical outputs. You have to squeeze your problem into this type of output in order to use an encoder-only model
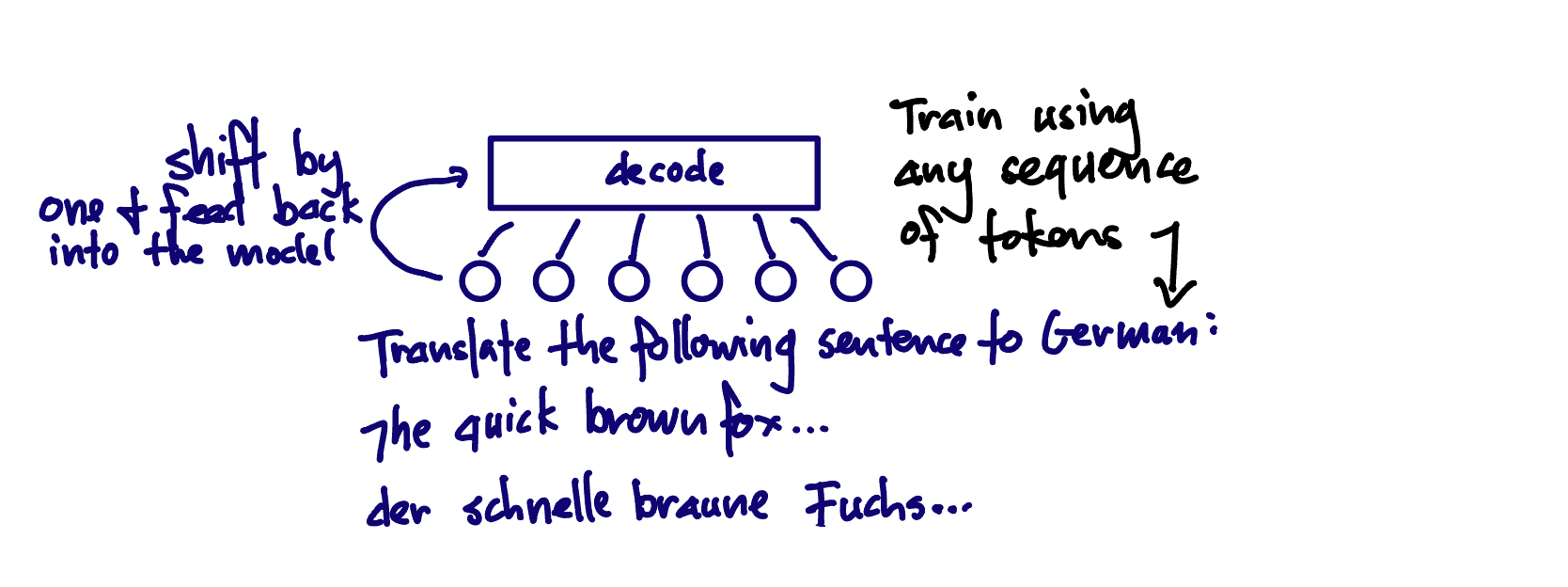
decoder-only - the GPT-type models are decoder-only models. The problems that they solve must be framed in terms of a stream of text. Given some starting text, what is the "completion" of it. This is how you are probably used to using Chat GPT: 'What are the names of all the characters in the follow story: "Once upon a time..." ' and we expect a response like "The characters are RJ, Keivan and Aashray."
decoder-only models are "auto-regressive," meaning that we predict a token (part of a word) that follows the text so far, and then we feed the whole text back into the model and predict the next-next token, as if the token we just predicted was part of the prompt we provided.
We train models like this by providing lots of examples of the sequence of text in the form that we want the model to copy. For question answering like this, we would have a whole bunch of questions followed by answers stuck together (and and End-Of-Sequence token in between each pair of question/answers to tell the LLM that it doesn't need to generate more tokens after it has answered).
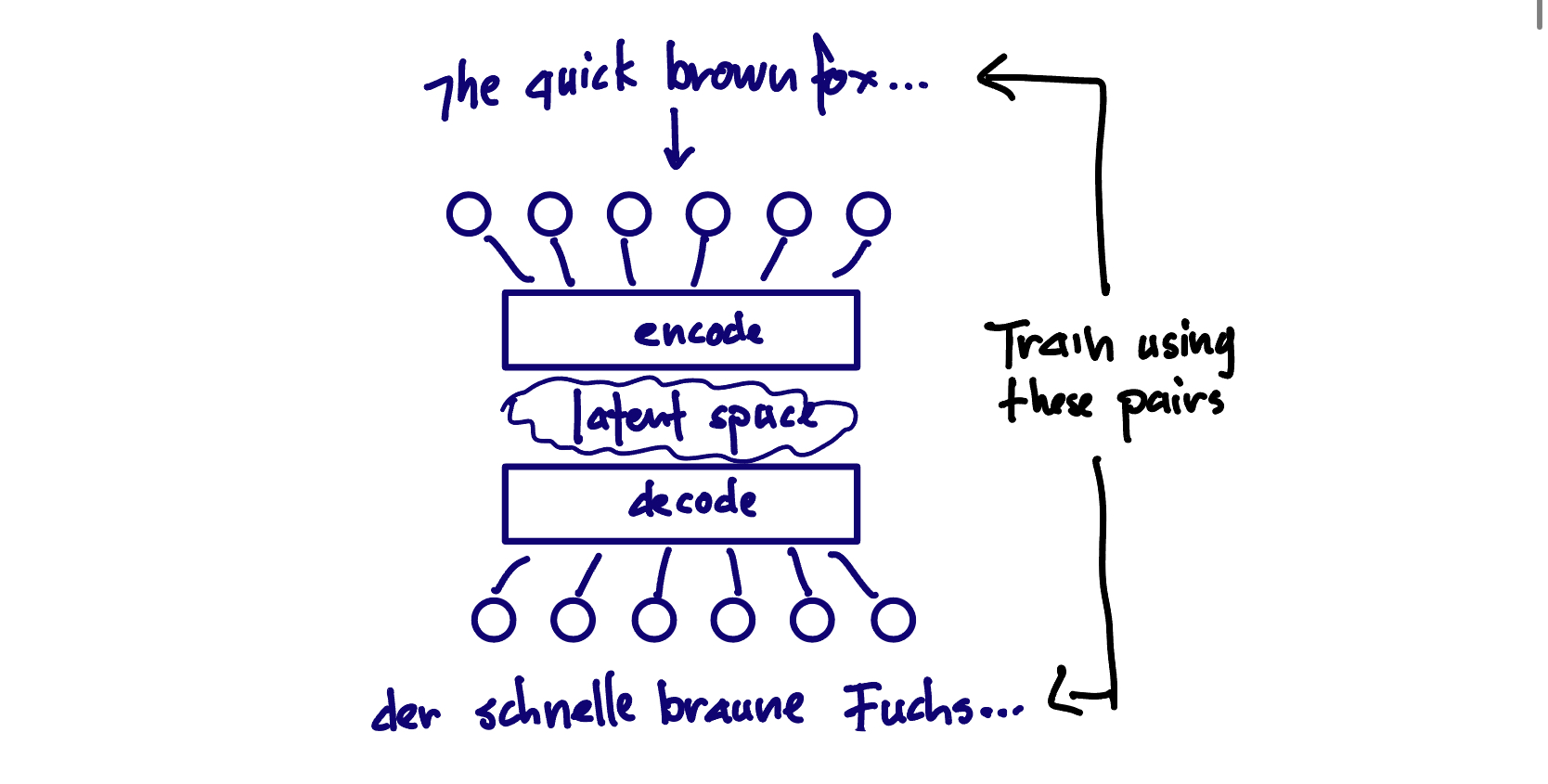
encoder-decoder - T5 is an example of this type of model. This was the original Transformer architecture, and was originally designed for translating from one language to another. The input is a sequence of tokens, such as some text in Korean, and the output is another sequence of tokens such as some text in English. These models are often called sequence-to-sequence models.
One of the key differences between an encoder-decoder Transformer and a decoder-only transformer is that you train and encoder-decoder transformer with separate input and output sequences. (This is why decoders are the dominant architecture: you can use unsupervised training on tons of text to pretrain decoder-only LMs) For an encoder-decoder architecture, you're teaching the model to map one sequence of tokens to another, rather than predicting what comes next in a sequence.
Obviously we can map many problems to any of these architectures. We can map our character extraction problem in the following way
encoder-only: For each token in the input, output whether it is a part of a character name. We can then go through the labels and put together successive character-name tokens, deduplicate and we will have a list of character names.
decoder-only: prompt as above
encoder-decoder: Input is a story, output is a list of names
The encoder-decoder architecture seems like a good match for this problem, but it is unclear to me which architecture is the most efficient use of parameters for this problem vs. a decoder-only architecture that can dedicate more resources to understand the text of the story, since the output format is so simple.
Other model considerations
Parameter Count: Obviously parameter count will matter, but maybe not in the way that we might expect. We will discuss "inverse-scaling" problems below, of which this is probably one.
"Local" vs API will have big operational consequences. We must buy or rent a GPU, and have enough inference workload to keep it busy. If we use serverless GPU services, we will pay a latency penalty on startup while the model loads into the GPU. If we use an API, then maybe things get expensive at large scale? Or maybe economies of scale for the API providers will be enough to make up for the markup, even at some scale (I think so).
Proprietary vs. open source matters in-as-much as we either care about open-source intrinsically, or want to keep our data very private, and therefore want things to be actually on-prem (I guess this is basically the same as "local").
For my character extractor problem, our data is not private, our scale is small, and latency matters. All of these things push us towards API inference, but lets find out how things shake out.
The models to try
I'm trying to learn about the space of options, so I decided to generate some data and do an experiment to figure out the cost and speed and inference quality of various options:
an existing old(ish) school Named Entity Recognition (NER) model called
DistilBERT-NERopen source LLMs:
mistral-7Bandphi-3-miniproprietary:
gpt-3.5-turbo,claude-3-haiku,claude-3-sonnet,mistral-small(the dark horse)a fine-tune of
flan-t5
Evaluation metrics
For our problem, accuracy (well not exactly accuracy...) is pretty important. Missing characters, multiple characters that represent the same person, hallucinated characters, etc. will mean images that don't match the story.
On the other hand, we will also want to extract the names of text that the user enters somewhat interactively, so the performance of the model needs to be high.
Cost will matter more if there are every lots of users, but it also serves as a good comparitor since I used different hardware for different models, not to mention the proprietary models.
The metrics I used to evaluate the different models are pretty standard. If you squint a little bit, this actually is a retrieval problem (the query is the story, the response is the characters in the story). So we will use some standard retrieval metrics
precision - of all the characters I "retrieved" from the story, how many were actually characters?
recall - of the actual characters in the story, how many did I "retrieve"
f1 - the harmonic mean of precision and recall. I think about harmonic mean as a "soft-min," meaning it tends to be close to the min of the precision and recall
I calculate each of these metrics for each story, and then calculate the mean of the metrics over the validation or test set.
DistilBERT-NER
Named Entity Recognition is a "classic" problem in NLP. NER usually mean recognizing any proper noun (including place names, organization, countries, etc. as well as people). BERT and it's reduced-size cousin DistilBERT are previous generation language models that are still in use because their design (encoder-only) works well for some tasks like text classification and... NER.
Fortunately, lots of people have fine tuned *BERT for NER, so we can just try out a model. dslim/distilbert-NER on HuggingFace looks both small (60M parameters) and accurate, so I tried it out on Colab:
Here are the results from the run:
| Metric | Value |
| precision | 0.733699 |
| recall | 0.736375 |
| f1 | 0.735035 |
Here is an example where the model did not have a perfect score:

The NER model misses the "Mr." in "Mr. Delivery", and it sometimes breaks up "Mrs. Smarty Pants" in different ways.
Here's another example:

The NER model also seems to have trouble with epithets like "Sammy the Smart Squirrel" and "Patty the Polite Parrot".
Perhaps I could add some heuristics and the model could do better, but maybe a larger, more general model with a decoder could do better without much work by me, so lets try that.
dslim/bert-large-NER, but the model outputs the predictions in a different way from dslim/distilbert-NER, and I don't think the encoder-only approach is going to be adequate for the more complex semantic names and epithets, so I gave up and moved on ¯_(ツ)_/¯Open source models
Three small models have been at the front of the hype-train recently: mistral-7B, llama-3-8B and phi-3-mini. I have heard that smaller models actually tend to do better than larger ones on some easier tasks. Jason Wei from OpenAI has an interesting explanation of phenomena like this in a Stanford CS25 V4 Lecture (this is an excellent series, BTW!) I want to see how these smaller models do with NER.
Here is my notebook:
Json output
One thing I have noticed about small models is that they tend to have trouble following instructions like "Output a comma-separated list of characters in this story. Don't output any other text, such as explanatory text." They tend to really, really want to output text like "Here is a list of characters: Fred, George, Michael. I hope this is helpful for your task," despite offering tips and warning of dead puppies.
We can fix this by using outlines, a library for enforcing a schema on the output of an LLM. It does this by altering the log-probabilities of the outputs at each step from the LLM to only to only allow valid json (or any other context-free grammar). The paper Efficient Guided Generation for Large Language Models describes how they do this efficiently.
Results
| Metric | Phi-3-mini 3.8B | Mistral-7B v0.3 | Llama-3 8B |
| precision | 0.800610 | 0.846937 | 0.616764 |
| recall | 0.837257 | 0.860567 | 0.679253 |
| f1 | 0.808432 | 0.845475 | 0.624396 |
Oof! Llama 3 does very poorly on this task, maybe related to "inverse scaling"? Mistral-7B is hardly smaller, but does way better on this task. Llama-3 was trained on 15T tokens (!!!). It is unclear how many tokens Mistral 7B was trained on, but it seems likely that it is less than Llama-3 since Meta has been pushing the boundary on the number of training tokens (one rumor puts it at 8B tokens) I wonder if inverse scaling could be related to token count as well as parameter count, since it is really related to capabilities, rather than parameters per se?
Proprietary models
OpenAI and Anthropic put a lot of money into building GPT-3.5/4/4o and Anthropic Claude 1/2/3, so presumably those models have good performance. They also have huge economies of scale, so presumably they also have good economics.
Since we are using the Mistral open-source model mistral-7b-v0.3, I'm also curious about their proprietary offering mistral-small. The cost per token is exactly twice that of gpt-3.5 at the time of writing, so it's not likely they're win on cost, but how does their performance stack up?
OpenAI has only gpt-3.5-turbo for their current generation small model offering (nobody knows for sure how big it is). Anthropic has claude-3-haiku which might be a 3B model (3 lines per poem) and clause-3-sonnet which might be a 14B model (14 lines per poem). The size of mistral is unclear, except that I would guess it is some sort of finetune or refinement of mistral-7b.
All three APIs offer "tool-use mode," which is presumably something similar to outlines, so we will use that. As it turns out, sonnet doesn't seem to work at all with "tool-use" mode, and haiku's performance (against our metrics) is lower in "tool-use" mode than just using a regular prompt (!). On top of that, the model uses more tokens in "tool-use" (perhaps because it is rejecting and retying tokens?)
Here is my notebook for the proprietary models:
Here are the results:
| model | precision | recall | f1 |
| gpt-3.5 | 0.885641 | 0.906672 | 0.890498 |
| haiku | 0.902815 | 0.936999 | 0.912284 |
| haiku-tool | 0.875685 | 0.938288 | 0.898414 |
| sonnet | 0.800982 | 0.897480 | 0.836882 |
| mistral-small | 0.868994 | 0.913717 | 0.883758 |
Interestingly, sonnet does worse that haiku, which again supports the "inverse scaling" theory mentioned above. Also, note that haiku-tool does worse than haiku except on recall. I don't have a good theory about why that is.
gpt-3.5 and mistral-small both have good performance.
T5 LoRA
I know this is a lot to keep track of, and there are some plots and a cost analysis below, but before we review that, lets see how well a small fine tuned model will do. I chose google/flan-t5-large, with 770M parameters, which is quite a bit smaller than the other models we have been testing besides the NER model we tried first.
T5 is an encoder-decoder model (like the original Transformer models), which roughly means that it is designed to translate one type of text into another. This could mean language-to-language, but it can also mean from story to list of characters.
Unlike a decoder-only model (like gtp), the output is separate from the input, so we don't need to extract the characters from the output text.
I'm not sure how much the model architecture will impact its performance on this task vs. a decoder-only model.
Here are the artifacts from fine-tuning
Notebook: Character_Extractor_T5_LoRA.ipynb
Weights and Biases: t5_target_finetune_for_character_extraction
And the results:
| Metric | Value |
| precision | 0.875659 |
| recall | 0.886578 |
| f1 | 0.874909 |
Fine tuning was obviously more work than the other methods, but a big chunk of the work was actually just figuring out how to use the transformer and peft libraries to do fine tune the particular model in the particular way I wanted to, and setting up the tokenizer, data collator, etc. I got caught by cut-and-paste errors a couple of times, and a mismatched collator caused tricky memory problems. Lots of other details such as fp16 not working for Seq2Seq models in the transformers library in some circumstances meant a lot of debugging to get the fine-tune to actually happen.
In the end, however, we got pretty good results, and very fast performance, and I learned a lot, so I'll take the "W".
Analysis
For my use case, I have a couple of considerations besides the metrics we have been tracking. Obviously inference time and cost are important, but the operational complexity of using a model, and the sensitivity to traffic volume are also things I need to consider.
Local vs. api
The open-source models can be served by inference providers like replicate, but their off-the-shelf offerings don't include JSON mode, which was important for our evals. fireworks.ai has the advantage that i also provides "json-mode" for the open-source models it serves, so i have included that in the evaluation, although I just assume we are using a particular number of tokens and that the performance metrics are the same as doing local inference.
Cost of local inference
In order to compare the cost of the proprietary models to local ones, I have assumed 50% occupancy on the local GPU. This obviously doesn't hold for a little demo, but maybe for a real deployment???
Since I have done some of the evaluations of the smaller models on smaller, older GPUs like T4s and L4s, I used a aggregate metric I found to create a performance ratio between T4 and RTX A4000, and between L4 and RTX A4000, since RTX A4000s are widely available for inference on RunPod and other GPU-as-a-service providers, and offer good cost/performance ratios and similar memory.
Finally, the results
Here is the analysis notebook:
And the results:
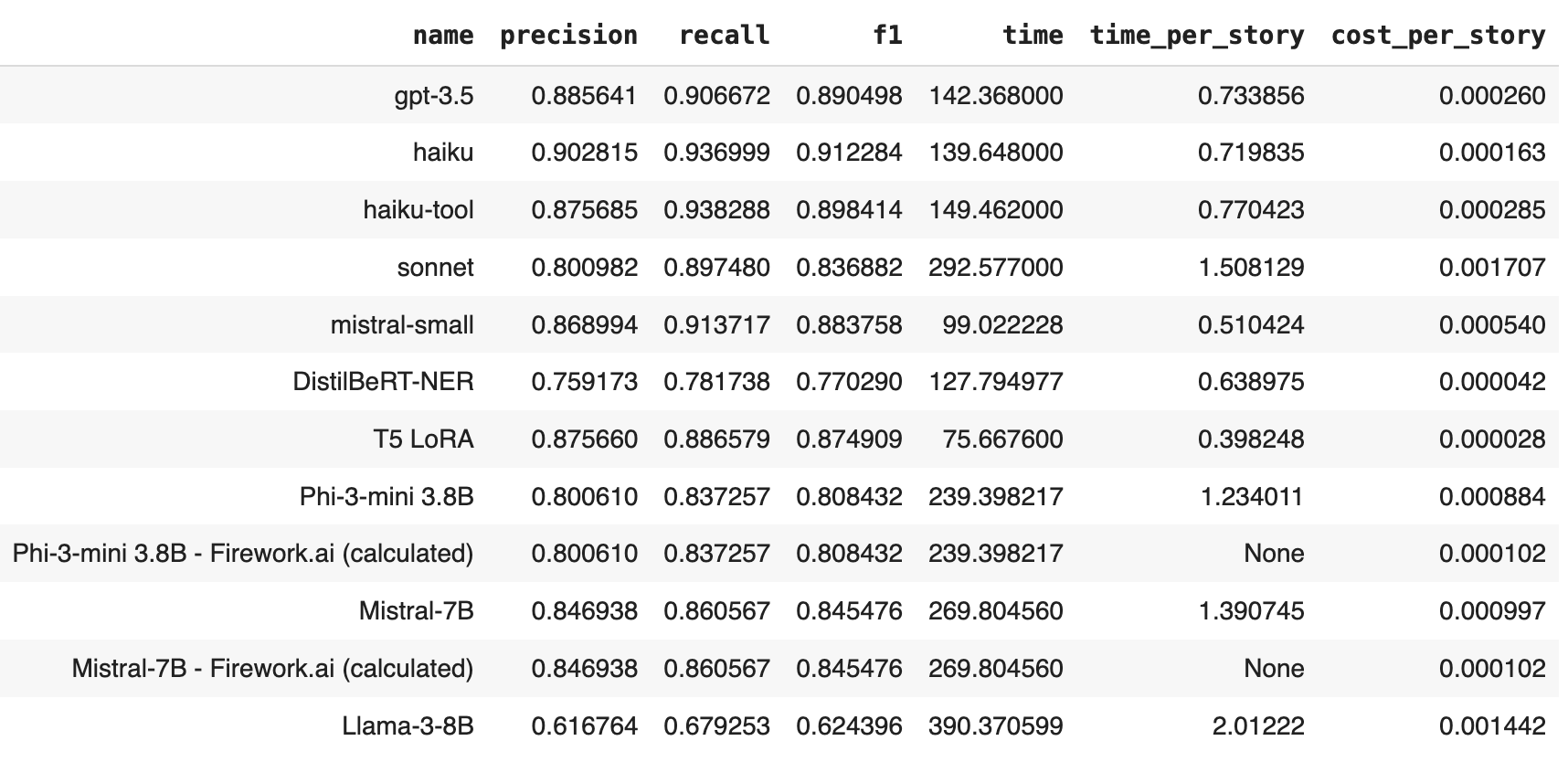
There's so much to talk about! Lets take a look at cost-per-story vs F1 score to start. Green means local, blue means hosted.
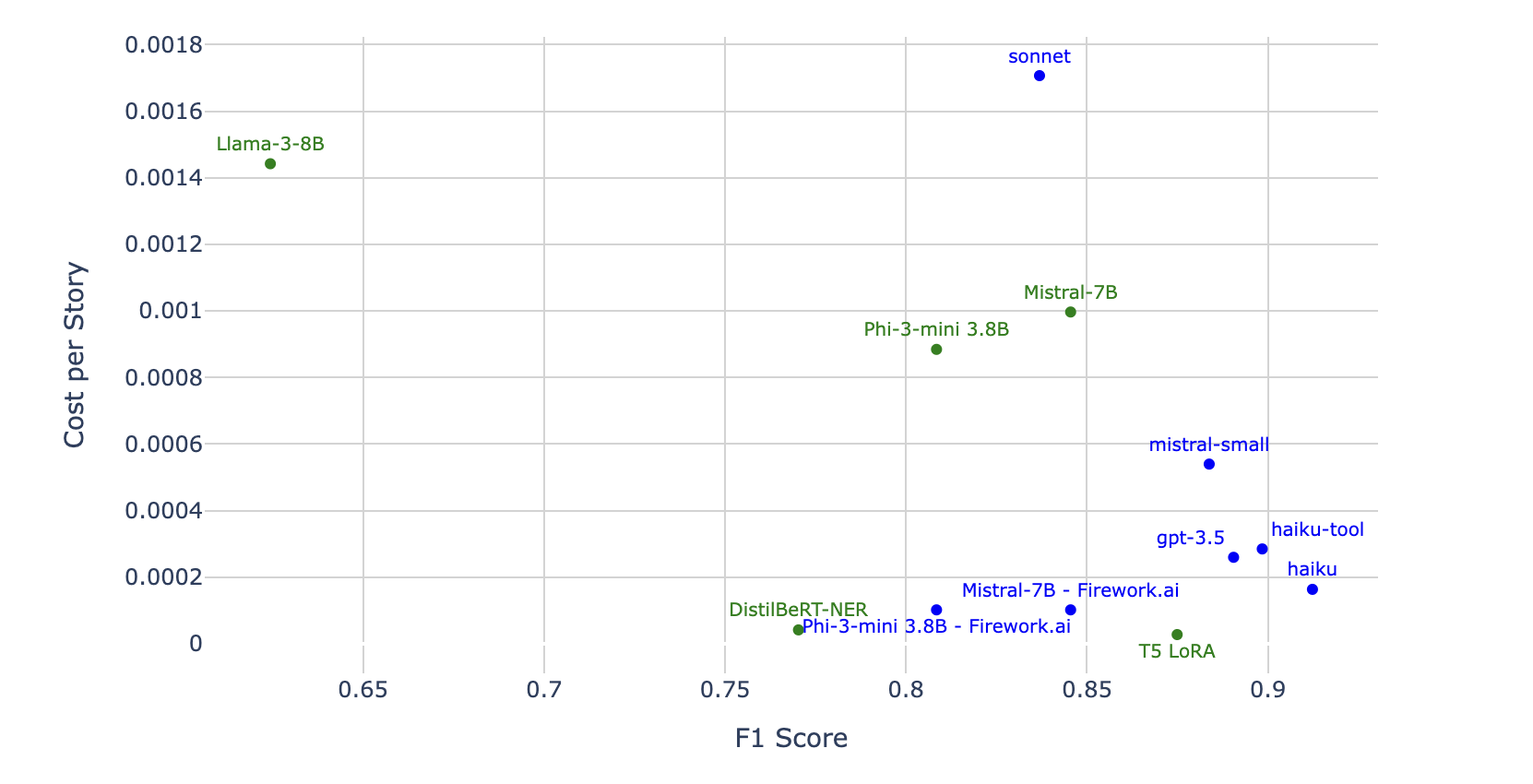
haiku is the clear winner for F1, and our T5 wins on cost. The other open source models are mostly trailing the proprietary models on performance and hosted generally also wins on cost, except for our very small models. sonnet and Lamma-3-8B are sad outliers :(
Lamma-3-8B setting up inference that made it slow. I didn't see anything obvious, but there are probably ways to make it faster if it was performing well on the metrics. Since its not, there's no need to figure that out.I added the approximate cost for phi-3-mini and mistral-7B on fireworks.ai, since fireworks.ai support serving open source models using JSON mode
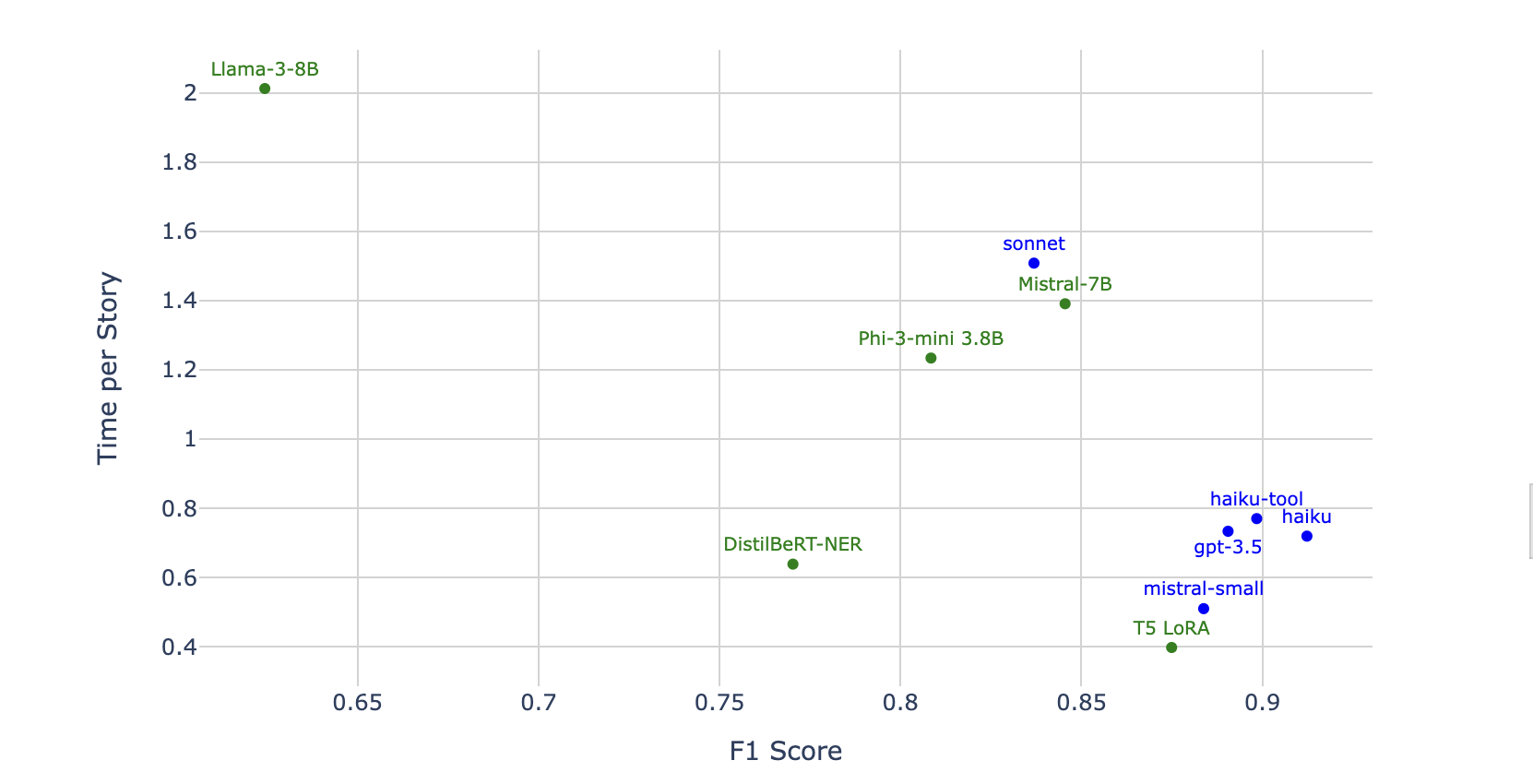
Time and cost are mostly the same thing, so not-surprisingly, the plot is very similar. One thing that stands out is that mistral-small is very fast. Too bad its so expensive!
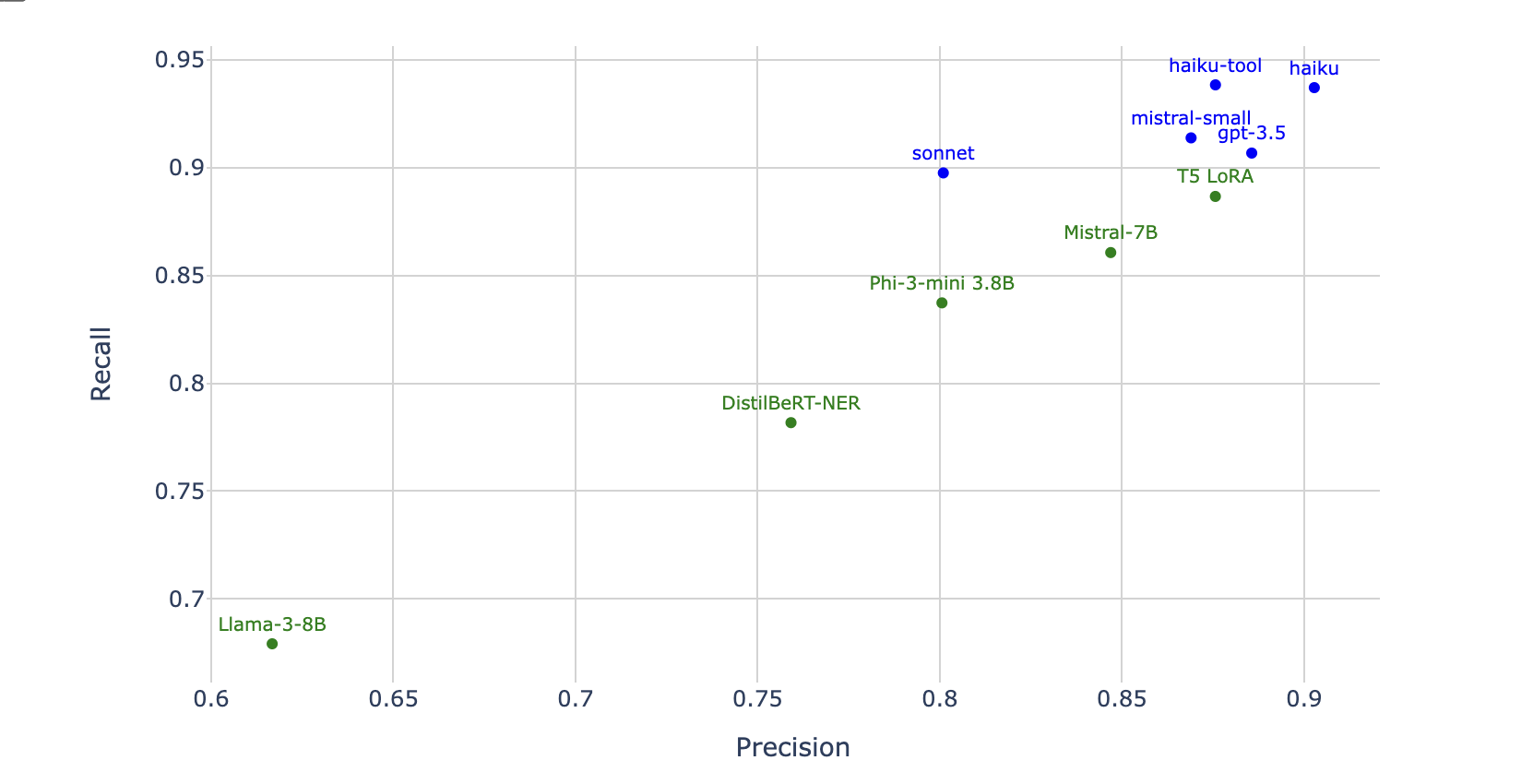
Finally when we just look at precision and recall, the proprietary models stand out as doing strictly better with recall. This means that they tend to get all of the characters in the story, but may throw in characters that GPT-4 didn't think were main characters. Maybe this is ok for our use case.
In summary:
T5 LoRA has the lowest cost per story assuming volume, but DistilBERT-NER might do better if we used a better GPU and a lot of volume
T5 LoRA performs pretty close to the proprietary models, despite only have 770M parameters
Llama-3-8B has low performance and high cost, as does sonnet
Phi-3-mini disappointed, and broke the inverse scaling "law": worse performance despite smaller size
haiku is the all-round winner
highest performer
easy to use - no need to rent GPUs, suffer slow startup for serverless, or maintain models
close to lowest cost at scale, lowest at low scale
T5 LoRA did not disappoint! Great cost / performance ratio, and we might be able to improve performance with better fine-tuning.
I'd still like to try...
I wonder if gpt-2-large, which also has 770M parameters, would perform better after fine-tuning than our T5 LoRA. It seems like having a sophisticated decoder to output a few names is probably a waste of parameters, and would be better spent on a single chain that looks at the input.
Feedback always appreciated
I'm writing this to learn. I'm sure I've said some dumb things, or missed something important. Please comment if you hand any feedback, questions or comments!
Subscribe to my newsletter
Read articles from RJ Honicky directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by