System Design -3 (Sharding Techniques)
 Shivam Saurabh
Shivam SaurabhIn the previous article, I have explained about CAP theorem and types of database based on CAP characteristic also i have given basic understanding of sharding and sharding techniques. Now it's time to understand these techniques in detail.
First of all let's understand, how sharding is helping us to design a scalable system ?.
the answer is, as we have a very large database which contains a very big amount of data so when we perform any query on this database then due to large data, computation takes more time to find relevant data also as data is large index could be large enough to not fit into memory which can even lead to disk read which is slower than memory also in a large database more than one operation contend for the same resource to perform operation leading the more waiting time, these things affect badly on latency as well as throughput, here sharding comes to rescue us as we know in sharding we split up the data into smaller parts into multiple server thus performing query on these shards is way more efficient also query can be distributed across multiple shards allowing for parallel processing.
Sharding Techniques and their key problem:
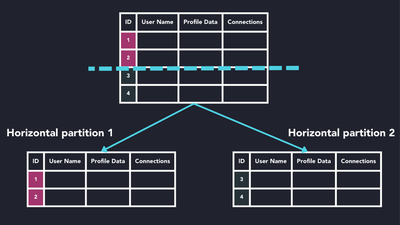
Horizontal partitioning: In this technique we put different rows in different table. This technique is also known as range based partitioning.
let's understand this with an example, Suppose a school has a database that stores information about all its students, including their grade level, name, age, subjects, etc. The school decides to horizontally partition this database by grade level. Each partition (or shard) would contain complete data for students in one particular grade. For example, one shard might contain data for all the 1st-grade students, another for all the 2nd-grade students, and so on.
This way, if a query is specific to students from a particular grade, it only needs to be executed on the corresponding shard, not the entire database. This can significantly improve query performance.
But there is a key problem with this technique is uneven data distribution. if one grade has significantly more students than others, the corresponding shard could become larger and slower to query. This could lead to performance issues. so while partitioning the database it require careful design and management.
Vertical partitioning: In this technique we divide our data to store the table related to specific feature.
let’s consider Instagram’s database as an example for this,
Instagram stores a lot of data for each user, such as profile information, posts, comments, likes, followers, and following lists. In a vertically partitioned database, Instagram could decide to split this data across different database servers based on the type of data. For example:
One server could store user profile information (like username, email, bio).
Another server could store posts (photos, videos).
Yet another server could handle social graph data (followers, following).
This way, a query needs to load data only from the relevant server, reducing the amount of data that needs to be loaded and processed.
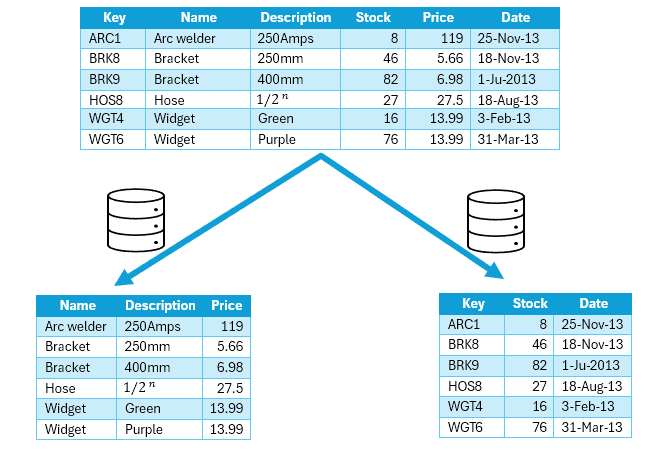
Moreover, vertical partitioning can lead to uneven load distribution. If one type of data (like posts) is accessed more frequently than others, the server handling that data could become a bottleneck, leading to performance issues.
So, while vertical partitioning can provide benefits in terms of performance and scalability, it also requires careful design and management to handle these challenges effectively
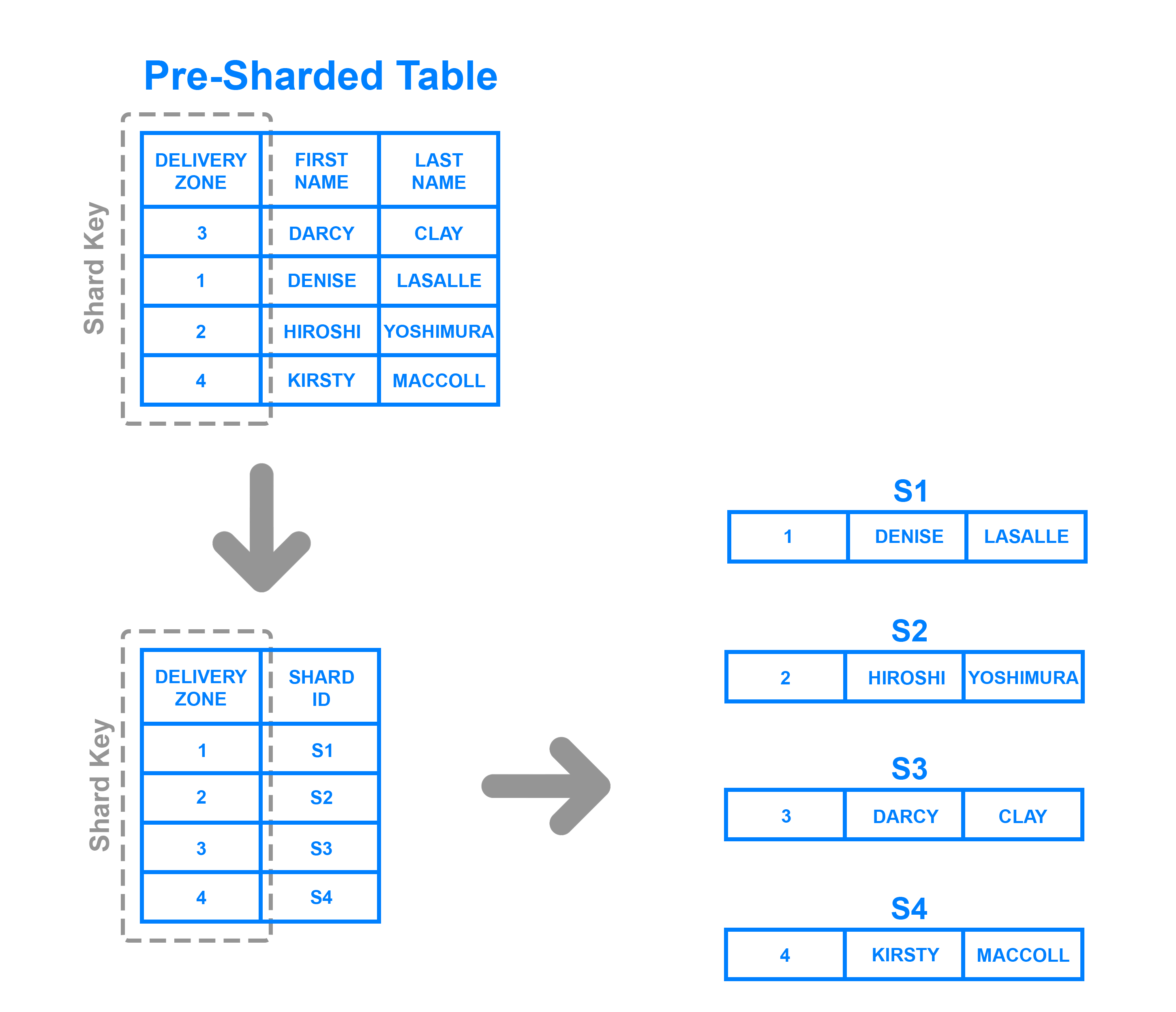
Directory based partitioning: This is the mostly used technique in case of sharding. In this technique we have a directory service (lookup service) which knows the current partition scheme and keeps a map of each entity and which database shard it is stored on. The lookup service is usually implemented as a webservice.
The client application first queries the lookup service to figure out the shard (database partition) on which the entity resides. Then it queries the shard returned by the lookup service.
It is loosley coupled so adding more shard is really easy.
Let's understand this technique with an example, consider an e-commerce application with millions of users. In a directory-based sharding setup, user data could be distributed across multiple shards. The directory service (lookup service) would maintain a mapping of user IDs to the shard that contains their data. When a request comes in for a specific user’s data, the system would consult the directory to determine which shard to query then it will perform the query on specific shard where data reside.
Hash-based partitioning: This is not a widely used technique. In this technique we just use a hash function and from the hash function we decide that data should be store in which particular shard. It can be difficult to choose an appropriate hash function and partition key that ensure good balance of data and performance, and this can result in skewed or uneven partitions which can affect query performance and scalability. Changing or modifying the hash function or the partition key once the table is partitioned can be difficult, and require re-partitioning or re-distributing the data, which can be costly and time-consuming.
Challenges of Sharding:
sharding a database across multiple servers can indeed introduce several challenges. Here are some of them:
Join and denormalizarion : In a sharded database, performing joins on data that is spread across multiple shards can be complex and inefficient. This is because data has to be compiled from multiple servers, which can be a performance hit. To mitigate this, denormalization is often used. Denormalization is a database optimization technique where redundant data is added to one or more tables to avoid costly joins. However, it’s not always practical to completely de-normalize the data.
Referential Integrity: Referential integrity ensures that relationships between tables remain consistent. In a non-sharded environment, enforcing foreign key constraints is relatively straightforward because all related data resides in the same database. However, related data may be distributed across multiple shards in a sharded setup. This makes maintaining referential integrity more challenging.
Rebalancing: Rebalancing is the process of redistributing data across all shards to ensure that each shard holds roughly the same amount of data. we can avoid this using directory based sharding.
That’s all for this article. In the next article i will give overview on System destem design or Instagram newsfeed.
Subscribe to my newsletter
Read articles from Shivam Saurabh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shivam Saurabh
Shivam Saurabh
👋 Hello, fellow tech enthusiasts! I'm a Full Stack Developer with a passion for building scalable and efficient web applications. My journey in the tech world is driven by my curiosity and my desire to turn ideas into reality. My expertise spans across various technologies and languages, enabling me to work on both the front-end and back-end of applications. I believe in writing clean, efficient, and maintainable code that not only solves problems but also creates an engaging user experience. Beyond coding, I have a keen interest in system architecture and design. I enjoy the challenge of designing systems that are robust, scalable, and easy to maintain. I'm always exploring new architectural patterns and design principles to keep my skills sharp and stay ahead of the curve. When I'm not coding or architecting systems, you'll find me diving into tech articles, exploring open-source projects, or contributing to the developer community. I believe in the power of sharing knowledge and learning from others. Feel free to reach out if you want to discuss tech, need some advice, or just want to say hi. Let's connect and create something amazing together! 👩💻🚀