Redis : Cache Aside Pattern
 Syed Jafer K
Syed Jafer K
Its an Application level caching, where the application checks whether the data is present in the cache (In our case redis). If data is present it returns the data. Else checks from the database and stores it in Cache and then returns the data to client.
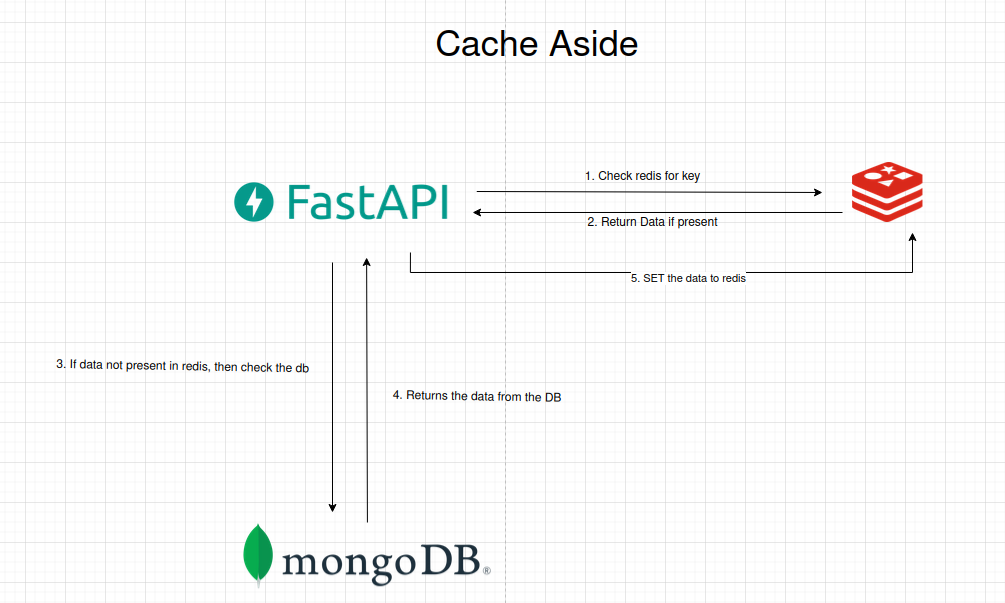
Steps:
The Application (Fast API), checks whether the requested data is present in the cache (redis).
If the data present in the cache (redis) it gets the data and returns the value.
If the data is not present in the cache (cache miss), it will check the details from the primary database (mongodb).
If the data is available it returns the data to the application.
The application now sets the data to Cache for future hits (cache hit).
Cache Hit: If the requested data is present in the cache.
Cache Miss: If the requested data is not present in the cache.
Implementation
We are going to create a mock todo application. Let's spin redis and mongo db using dockers,
For redis,
docker run -p 6379:6379 --rm redislabs/redismod:latest
For Mongo,
docker run --name mongo_container --rm mongo
To load the data into mongo, either you can use the below script, or restore from the dump file.
or
docker exec -i mongo_container sh -c 'mongorestore --archive' < 2l_data.dump
Lets create the api, app.py
Here i am exposing 2 apis,
/todos post - To create a record to db.
/todos/{todo_id} get - To get the record from resource.
Run the app
uvicorn app:app --port 8000
For the testing pupose, we are using python locust module to send requests,
locust-file.py
Run the locust-file,
locust -f locust_file.py -t 1m -u 100 -r 100
Drawbacks
For every request there is a cache miss. If the requested items aren't repeating in a good percentage, then this will create latency.
What happens if the record been updated in the database, but not in redis. Do we need to write on every update ?
In a distributed system, if a node fails, it will be replaced by a new empty node. This will increase the latency. (this can be overcomed with replication of the data).
If your application is a write-heavy workload, then this will add a good latency.
When to use ?
If your application is read heavy, then you can go with this approach.
If your application is not having any dynamic change of data, then this approach will be a good one.
Subscribe to my newsletter
Read articles from Syed Jafer K directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by