How real-time sync apps actually work?
 Ronit Panda
Ronit PandaTable of contents

Hey everyone, if you're excited after the last blog and curious about how these systems work, let's briefly discuss how they operate.
IndexDB
"DB of your browser"
before moving forward though let's discuss a bit about indexDB, which is an inherent property of every browser, and plays a vital part in the working of real time sync engine.
IndexDB is a low-level API for client-side browser storage of significant amounts of structured data.
Transactional capabilities like RDBMS, however is a JS-based object-oriented database
Objects are indexed with a key, fetching and updating data into the indexDB with a proper schema is extremely fast; reads and writes generally have latency < 1ms and data can be scanned at over 500MB/s on most devices
The Sync Engine
"IndexDB and Cache are written interchangeably"
Now that we have a fundamental understanding of IndexDB let's dive into the various steps involved in building these sync engines on a very hight level
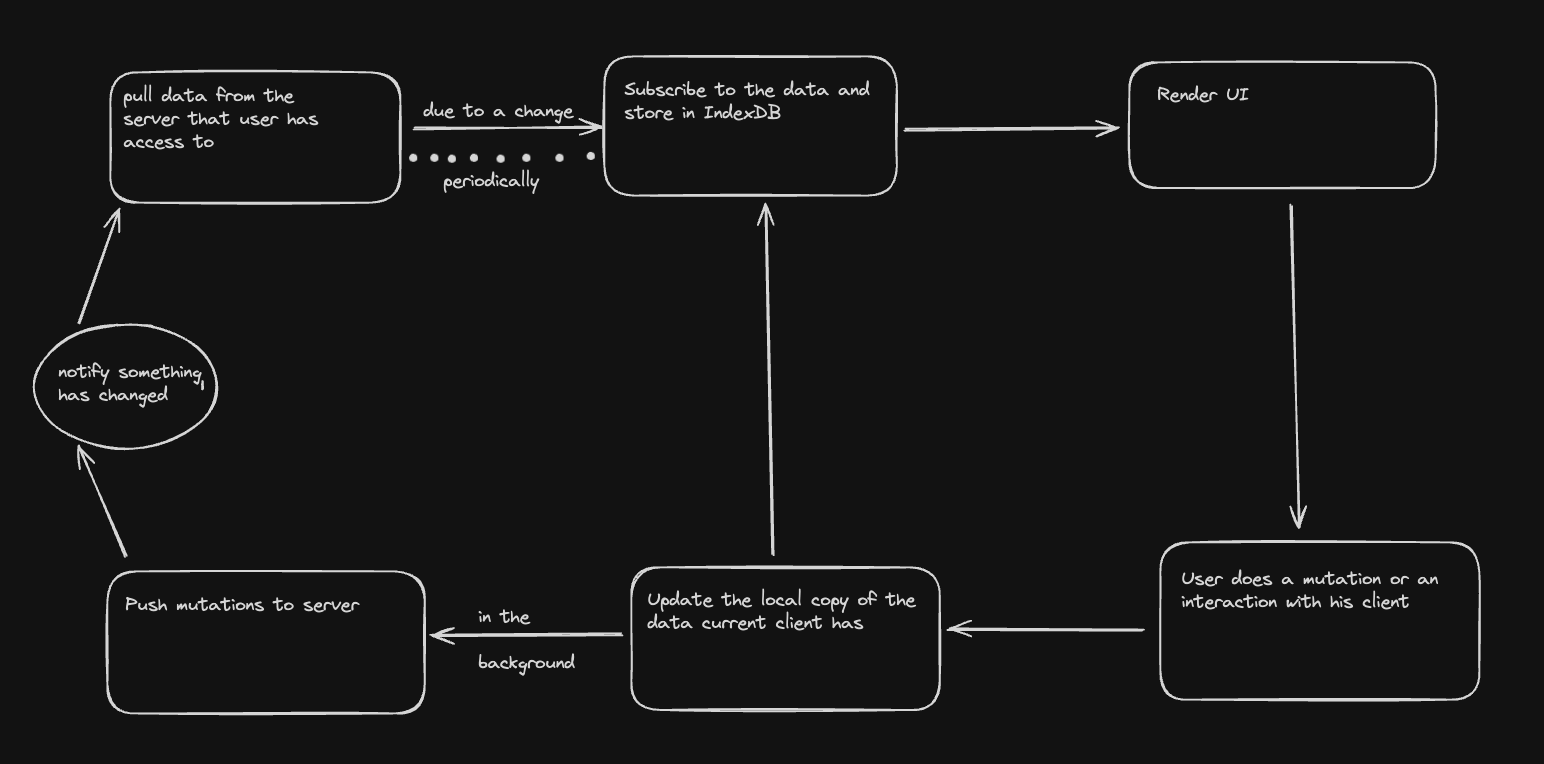
When a user signs up for the app, their browser client downloads an initial chunk of data they have access to and stores it in IndexDB.
The client application then reads and writes to its local copy of data stored in its cache, making interactions within the application instant.
The client should be directly subscribed to the data stored in the cache, which triggers re-renders whenever the state changes.
The changes the client makes need to be synced with the central database via our API. Also, the changes the current user makes need to be reflected to all clients that have access to the same data.
This can be achieved by storing all changes in a transaction queue and pushing them to our API to sync with the database and other clients.
We have to make sure that changes in the queue need to be pushed to the server as soon as a mutation happens inside the client to deliver that real time speed between multiple clients
Because of this pattern we can also achieve offline capabilities because of storing all mutations done by the user done inside a persistent storage providing the same UX when they are offline or even our server is down
Once the server has acknowledged these changes, we can send a request to all concerned clients to pull these changes via web-sockets.
After that, the clients request a patch of the new updates from the server. Once the server sends them a delta or patch of what has changed, the client updates their local IndexDB with the given delta, completing the full loop.
Building applications in this fashion gives us three significant advantages over traditional apps
Your application reads and writes at memory fast speed making the app instant and realtime, by taking the server round-trip off the application’s critical path, and instead syncing data continuously in the background.
Sync being bi-directional also enables the current client to see updates by other clients in real time without reloading the app
Once the sync engine is setup properly you don't really have to think much about network calls and managing state etc, because all of that will be managed by the sync engine for you. The developers will feel like updating and reading data in memory and the same magically changing the UI
Subscribe to my newsletter
Read articles from Ronit Panda directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ronit Panda
Ronit Panda
Founding full stack engineer at dimension.dev