Scale Your System with Sharding
 Ahmed Elamery
Ahmed Elamery
In today's world of ever-expanding data and user bases, scaling your system efficiently is more crucial than ever. One of the most effective strategies for achieving this is sharding. In this blog, we'll explore what sharding is, delve into key partitioning methods, address challenges like data skew, and discuss how consistency hashing using virtual nodes can significantly enhance your system's performance and reliability.
What is Sharding?
Sharding is a technique used to distribute data across multiple machines, ensuring that no single machine is overwhelmed with too much data or too many requests. By breaking down a large dataset into smaller, more manageable pieces called shards, systems can handle more data and traffic seamlessly.
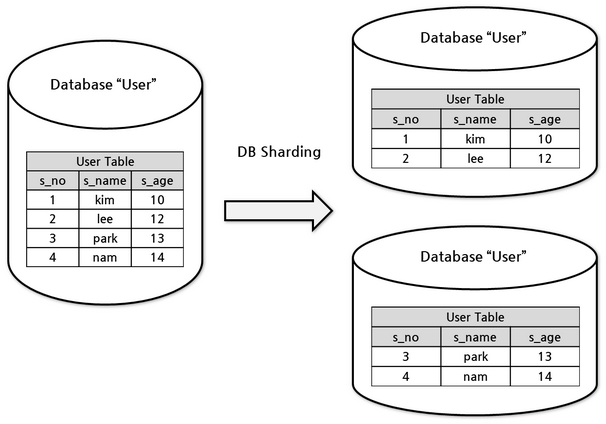
When you divide a dataset into smaller parts, each part can handle small tasks on its own. Bigger tasks that need information from several parts can be done faster by sharing the work across many computers, but this makes things more complicated.
To make the system more reliable, each part of the dataset is often copied and stored on several computers "By Replication". This way, even if one computer fails, the data is still safe and available from other computers
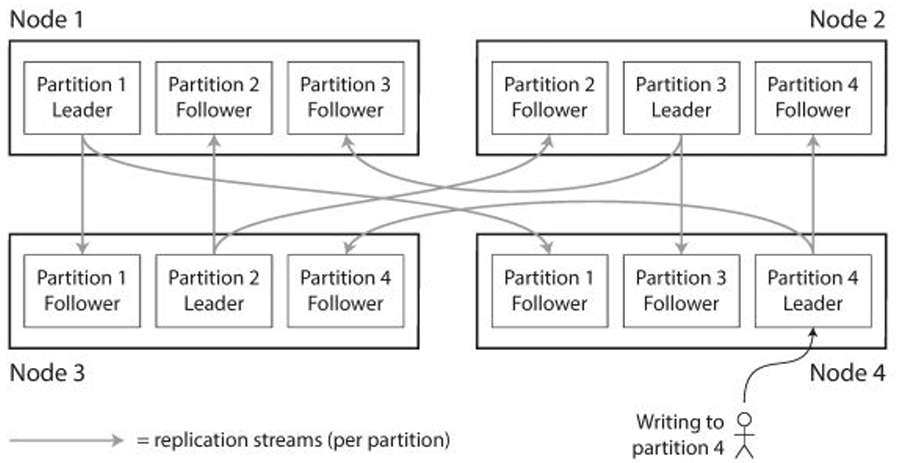
Key Partitioning
Key partitioning is the process of dividing data into distinct partitions based on a key attribute. This key determines which shard a particular piece of data belongs to. Key partitioning helps in:
Distributing data evenly across shards
Simplifying data retrieval
Enhancing query performance
Imagine our dataset is a collection of books, each identified by its title. In an old-fashioned paper encyclopedia, these books are sorted by title, creating 12 sections (partitions). For example, the first section has all books with titles starting with 'A'.
This setup allows us to quickly find a book by its title because we know exactly which section to look in. Additionally, because each section is sorted, we can easily read a range of books, like those starting with 'C' to 'H'.
However, there's a problem: the partitions might not be evenly spread. For example, the section for 'A' might be very large, while the section for 'T', 'U', 'V', 'X', 'Y', and 'Z' is small, causing imbalances.
And we also may not know the distribution of the key at the beginning.

A similar issue occurs when indexing logs by timestamps; new logs always go to the same partition, creating a "hot spot" with too much data.
A solution is to add a prefix to help distribute the load evenly. For instance, including the service name along with the timestamp can help balance the partitions.
Key Partitioning Using Hash
Hash functions play a vital role in key partitioning. By applying a hash function to the key, we can convert it into a hash value that determines the shard assignment. Here's how it works:
Select a hash function: Choose a consistent hash function that distributes keys evenly.
Apply the hash function: Convert the key into a hash value.
Determine the shard: Use the hash value to assign the key to a specific shard.
For example, if we have three shards and a hash function that produces values between 0 and 2 H(k) mod N where N is the number of shards, we can assign keys to shards based on the hash value.

By using hash, we have solved the problem of skewing data we do not know the distribution at the beginning, but we have got a new problem which is now we cannot do range queries from the same partition
Challenges: Data Skew
Data skew occurs when data is unevenly distributed across shards, leading to some shards being overburdened while others are underutilized. This imbalance can significantly degrade system performance.

For example, if a celebrity user causes a surge of activity, all writes related to their actions will target the same partition. Hashing doesn’t help because identical IDs produce the same hash.
Most systems can't automatically handle such skewed loads. Application developers must design solutions, such as adding a small random prefix to hot keys (e.g., a 2-digit random number), to spread the load across multiple partitions. This requires special design and extra bookkeeping.
Rebalancing Partitions
What is Rebalancing?
Rebalancing in a database context refers to the process of redistributing data across different nodes in a cluster to ensure even distribution of load and resources. This involves moving data from one node to another to balance the workload and improve performance and reliability.
When is Rebalancing Requested?
Increased Query Load: When the number of queries increases, more compute power is needed. Rebalancing helps distribute the increased load across additional nodes.
Dataset Growth: As the dataset grows, more storage might be required. Rebalancing helps maintain consistent partition sizes by moving data into new partitions.
Machine Failure: If a machine fails, its data needs to be reassigned to other healthy machines to maintain availability and fault tolerance.
Strategies for Rebalancing
Hash Mod N:
Data is assigned based on the hash of the partitioning key.
Issue: Changes in the number of nodes cause significant data movement, making it inefficient.
For example, if hash(key) = 123456, with 10 nodes, the key is assigned to node 6 (123456 mod 10 = 6). When the number of nodes increases to 11, the key moves to node 3 (123456 mod 11 = 3). If the nodes increase again to 12, the key moves to node 0 (123456 mod 12 = 0). Such frequent moves make rebalancing excessively expensive.
We need a strategy that minimizes unnecessary data movement during rebalancing.
Fixed Number of Partitions:
Create more partitions than nodes. Nodes handle several partitions.
Adding nodes changes which nodes handle which partitions, but not the key assignments.
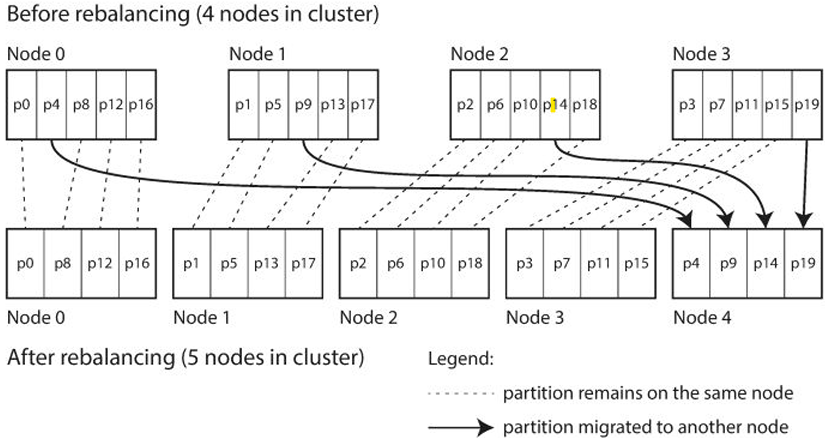
In the previous image, a cluster with 4 nodes had its data partitioned into 20 partitions, with each node handling 5 partitions. The key-to-partition assignment is independent of the number of nodes, relying instead on the number of partitions.
When a new node is added, it takes over some partitions from existing nodes, ensuring each node handles an equal number of partitions. The total number of partitions remains fixed at 20
One of the drawbacks of that approach is that choosing the right number of partitions is challenging when the total dataset size is highly variable, such as when it starts small but is expected to grow significantly. Each partition holds a fixed fraction of the total data, so as the dataset grows, the size of each partition increases proportionally. Large partitions make rebalancing and recovery from node failures costly, while small partitions create excessive overhead. The best performance occurs when partition sizes are "just right," neither too large nor too small. Achieving this balance is difficult if the number of partitions is fixed while the dataset size changes.
Dynamic Partitioning:
Fixed partitions work well with hash partitioning since keys are uniformly distributed. However, for key range partitioning (e.g., assigning a book based on its title's first character), fixed boundaries can be problematic, leading to uneven data distribution.
To address this, key-range-partitioned databases use dynamic rebalancing, where the number of partitions changes to evenly spread the load. For example, if a partition exceeds 10GB, it splits into two; if it shrinks below a threshold, it merges with another. This is similar to B-tree operations.
Each partition is assigned to one node, and nodes can handle multiple partitions. When a partition splits, one part may move to another node to balance the load.
Advantages:
Adaptable: The number of partitions adjusts to the data volume, keeping overheads low.
Pre-Splitting: Some databases allow setting an initial number of partitions to avoid initial load issues.
Rebalancing using Consistent Hash:
What is Consistent Hashing?
Consistent hashing is a technique used to distribute keys uniformly across a cluster of nodes, minimizing the number of keys that need to be moved when nodes are added or removed. This technique reduces the impact on the overall system.
Key Concepts:
Hash Ring: Nodes and keys are placed on a virtual ring using a hash function.
Key Assignment: Each key is served by the first node encountered when moving clockwise on the ring.
Efficiency: Adding or removing nodes only affects a small number of keys, reducing overhead and ensuring stability.
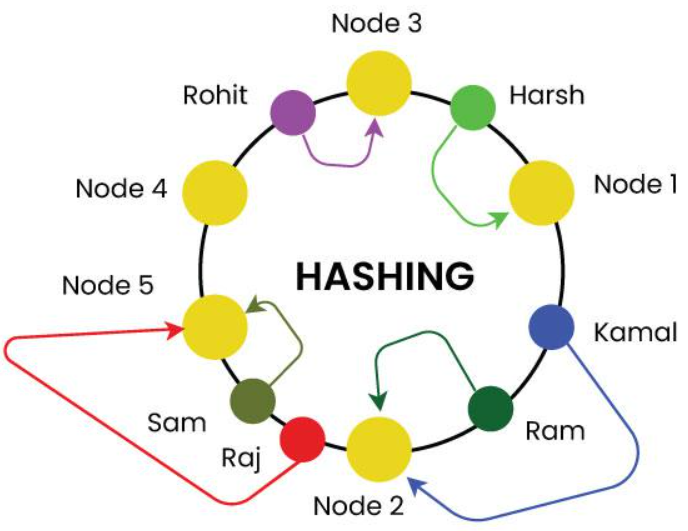
This image illustrates the concept of consistent hashing using a hash ring.
Here we just use names as keys but in practice keys should be hash of the primary key.
Rohit: Positioned on the ring and assigned to Node 3.
Harsh: Positioned on the ring and assigned to Node 1.
Kamal: Positioned on the ring and assigned to Node 1.
And so on for other input keys
Uses of Consistent Hashing:
Load Distribution: Balances the workload among nodes.
Node Failure: Minimizes the impact of node failures by affecting only a few keys.
Data Availability: Ensures data remains accessible and consistent, even if some nodes fail.
Phases of Consistent Hashing:
Hash Function Selection: Choose a hash function that deterministically maps keys to nodes.
Node Assignment: Assign keys to the closest node in a clockwise direction based on the hash value.
Node Addition/Removal: Remap a small portion of keys when nodes are added or removed.
Load Balancing: Redistribute keys to balance the load if a node becomes overloaded.
To make the Consistent Hashing more efficient we add virtual nodes which allow us to make every node store different ranges.
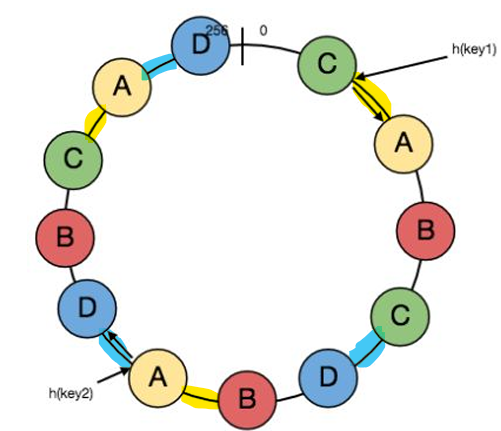
For example: in the above image ranges highlighted in yellow are the ranges of the keys that will be stored in shard A, ranges highlighted in blue for keys to be stored in shard D and so on.
But the question is what is the benefit of that?
By that we will make load balancing over all the shards either and the beginning of the system or when on node fails.
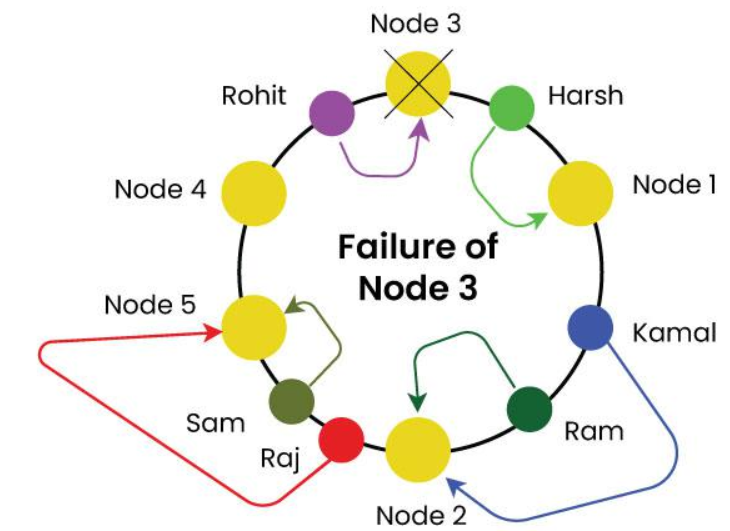
Imagine node 3 fails in the above consistent hash without virtual nodes. All load of Node 3 will go to node1 which leads to load balancing problem.
By adding virtual node to the ring structure and the biggening randomly that problem will not occur.
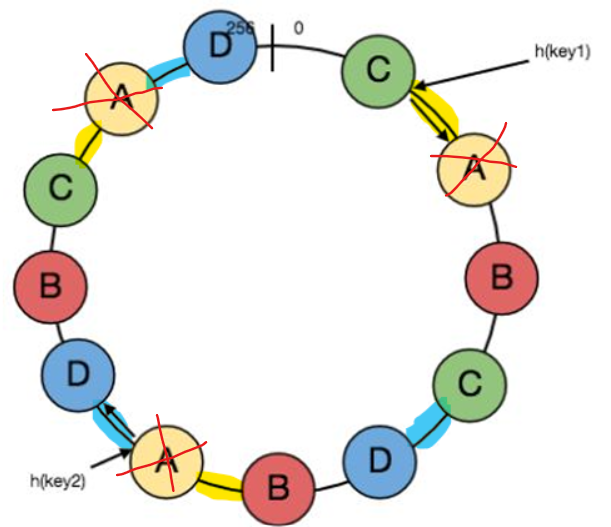
How can adding virtual nodes solve the balancing problem?
Imagine that we in the above image node A fails.
It's range will be distributed among nodes (D and B) and by increasing the number of sharding and the virtual node we will notice that the Consistency Hashing Using Virtual Nodes will give us more load balancing in cases of failures of adding new nodes.
Conclusion
Sharding is a powerful technique for scaling systems, and understanding the intricacies of key partitioning, data skew, rebalancing, and consistency hashing is crucial for implementing it effectively. By leveraging consistency hashing with virtual nodes, you can achieve a robust, scalable, and efficient system that can handle growing data and traffic demands with ease.
Subscribe to my newsletter
Read articles from Ahmed Elamery directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by