Week 3: Spark Transformations - Navigating Schema and Data Types 🧭
 Mehul Kansal
Mehul Kansal
Introduction
Welcome back, data enthusiasts! This week, we'll unravel the intricacies of schema inference and enforcement, data type handling, creating and refining dataframes, and removing duplicates. Let's get started right away!
Schema inference, sampling ratio and schema enforcement
- Schema inference can lead to errors in inferring datatypes and can also lead to performance degradation since scanning the entire data is time consuming.


- In sampling ratio, we infer the schema based on the ratio provided, rather than scanning the entire dataset.

- Without sampling ratio

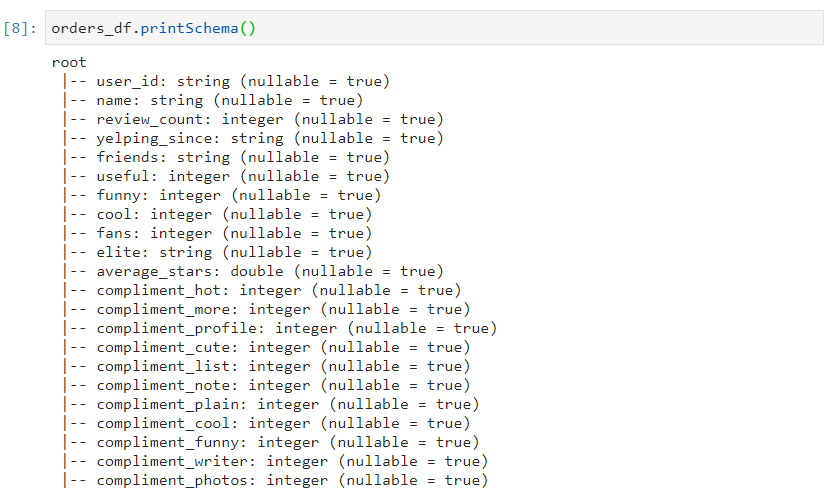
- With sampling ratio

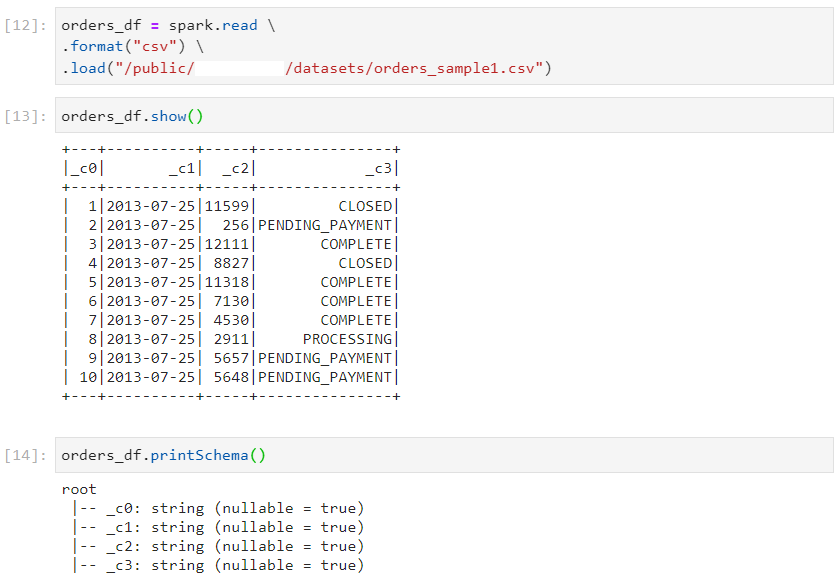
In schema enforcement, we explicitly specify the columns and datatypes for our dataset.
Without schema enforcement
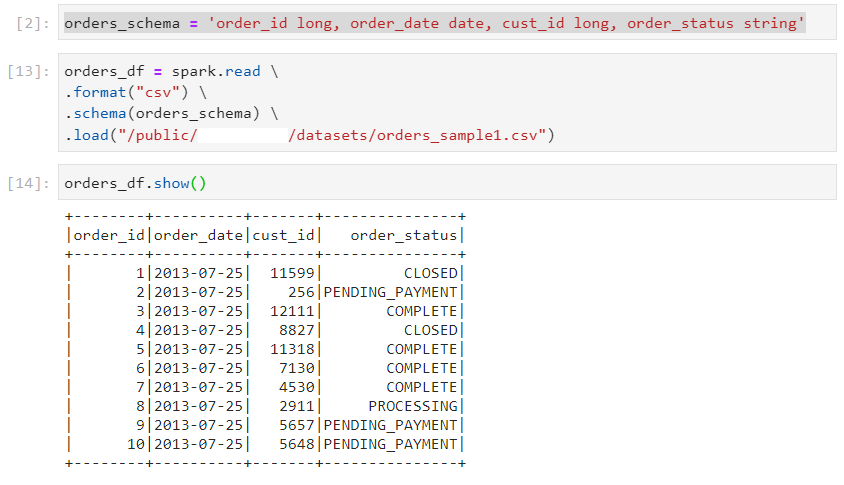
- With schema enforcement: Schema DDL

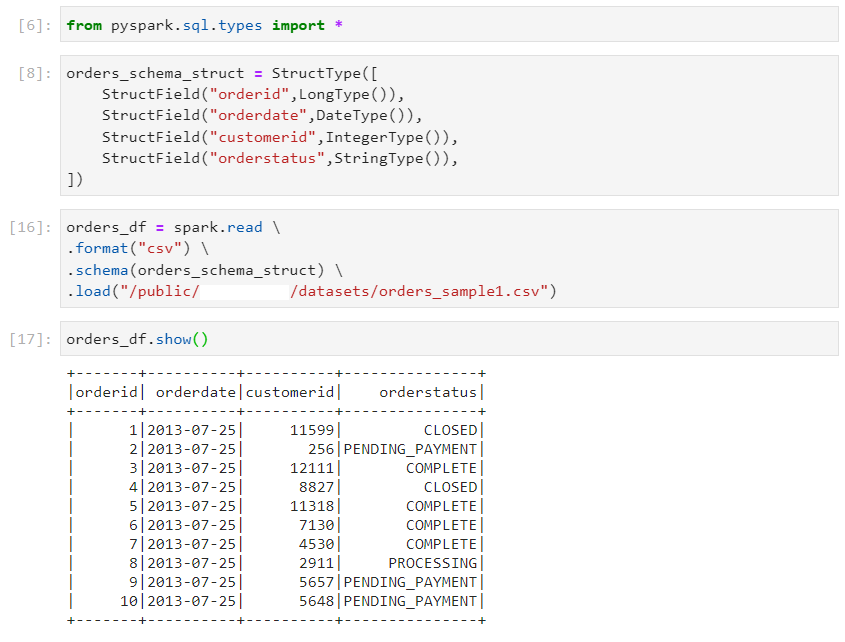
- With schema enforcement: StructType

Handling data types
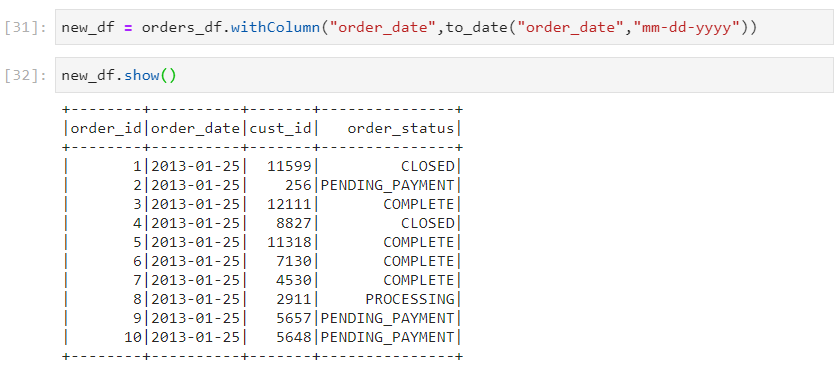
- The default format for date data type is 'yyyy-mm-dd' in Spark. If any different format is provided, we will encounter a Parse Error.
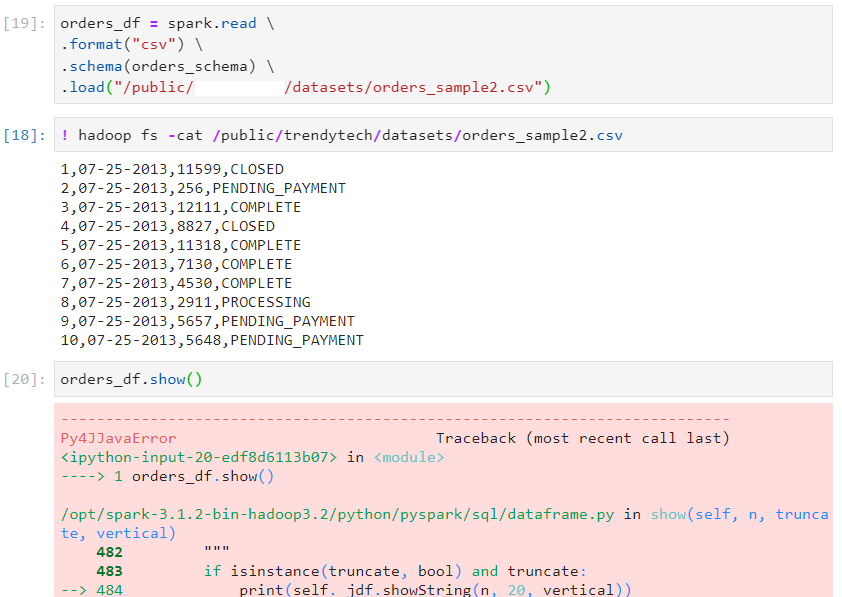
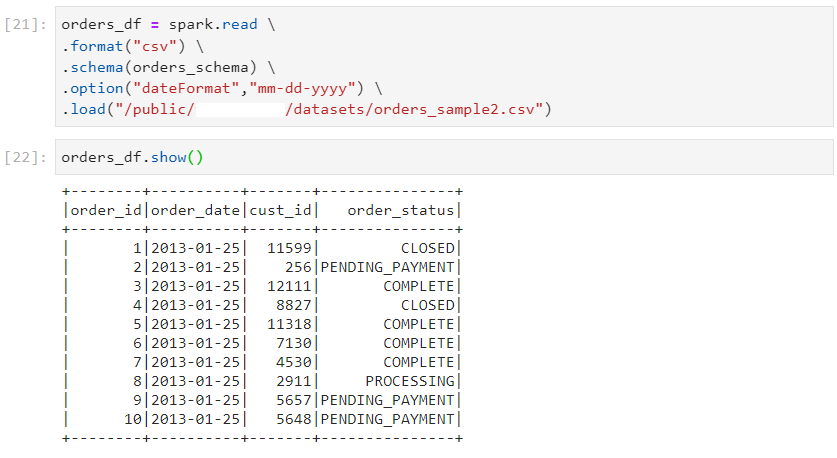
- One way of handling date formats is to explicitly specify them, using option.
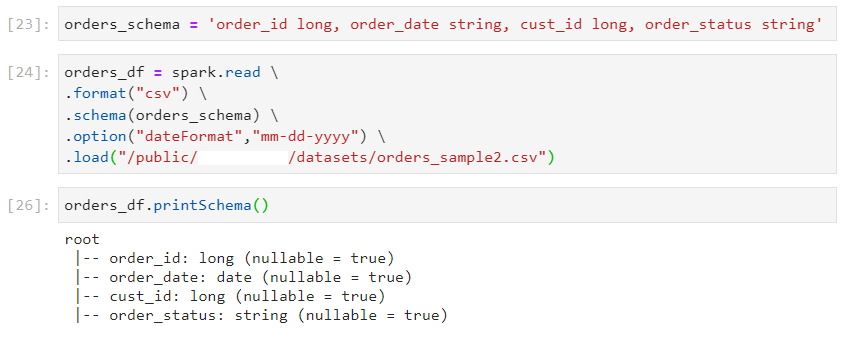
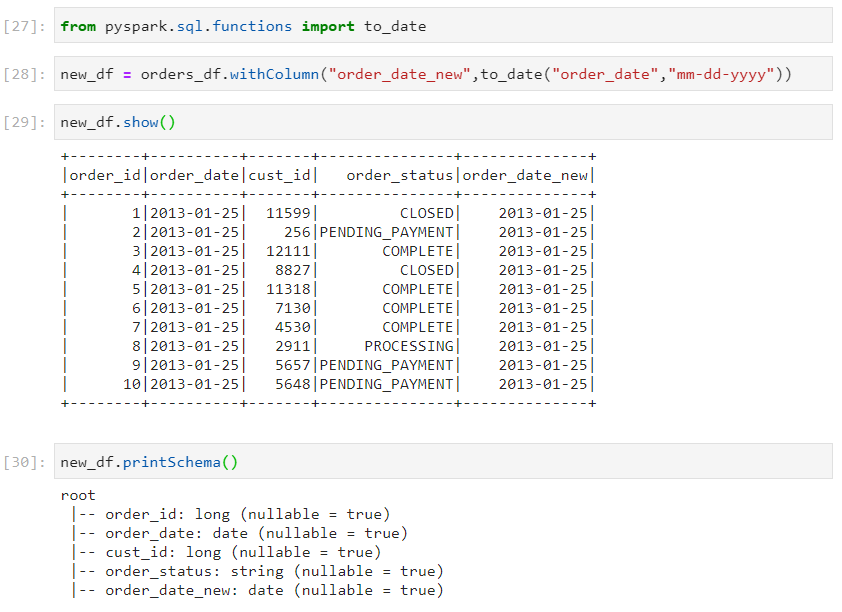
- Another way of handling date types is to load date as string initially and then, applying transformations to convert it later.
Datatype mismatch and dataframe read modes
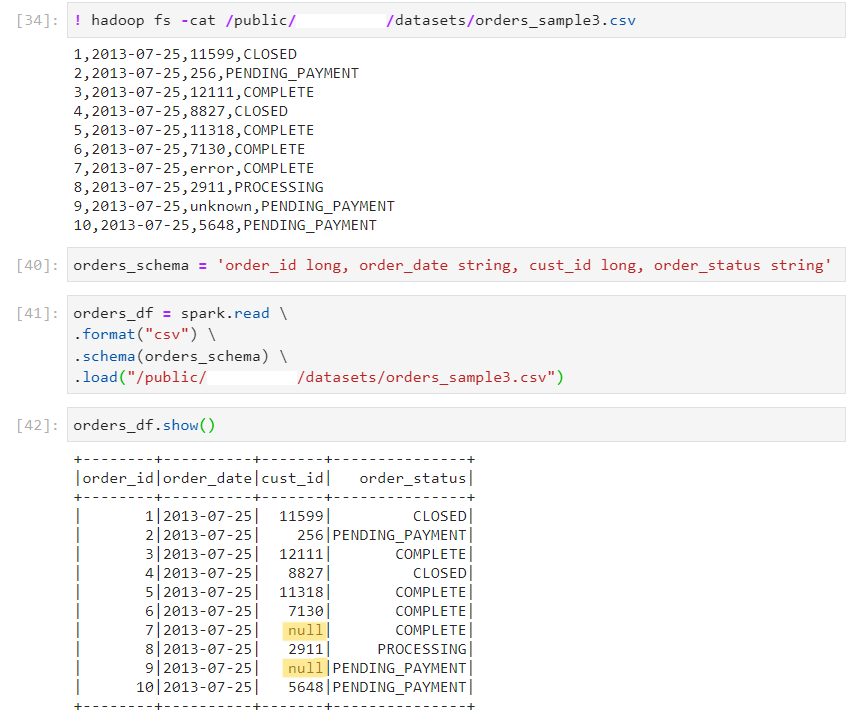
Permissive (default): In case of datatype mispatch, convert the specific values to null, without impacting other values.
Here, there are some datatype mismatches in cust_id column.
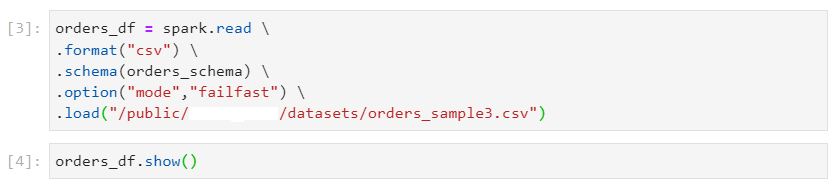
- Failfast: This read mode errors out on occurrence of any malformed records.

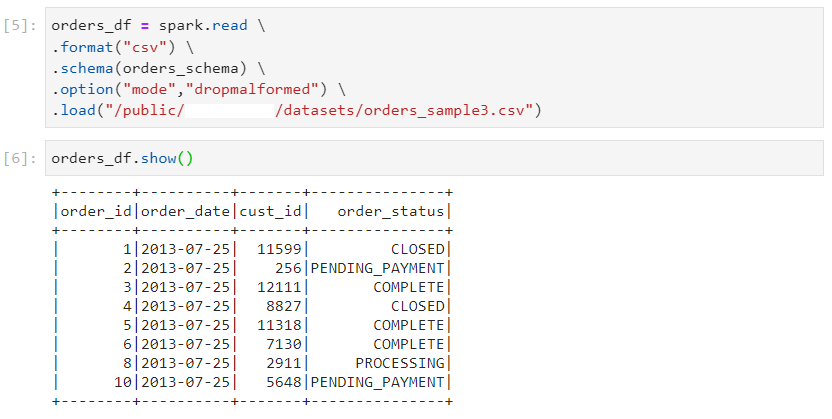
- Dropmalformed: Only the malformed records will be eliminated in this read mode and the rest of the records will be processed without any errors.
Different ways of creating a dataframe
- Using spark.read
df = spark.read.format("csv").option("header","true").load(filePath)
- Using spark.sql
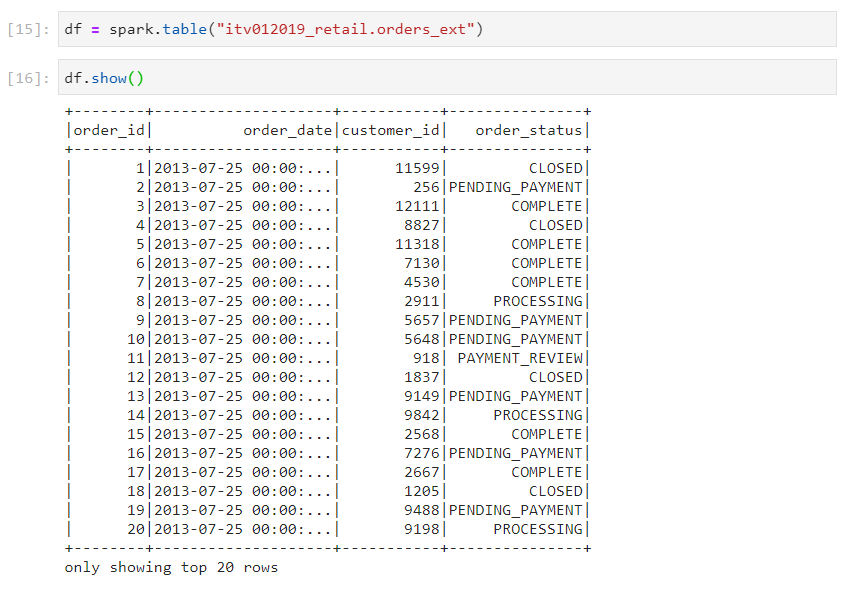
- Using spark.table
- Using spark.range
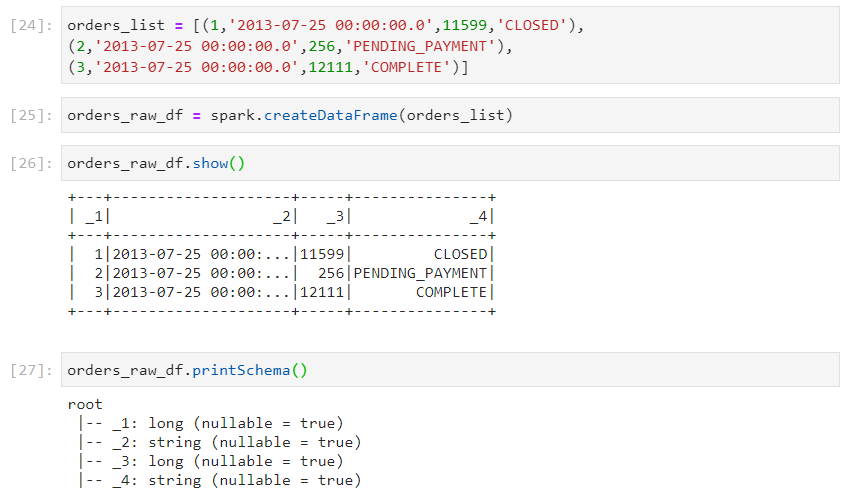
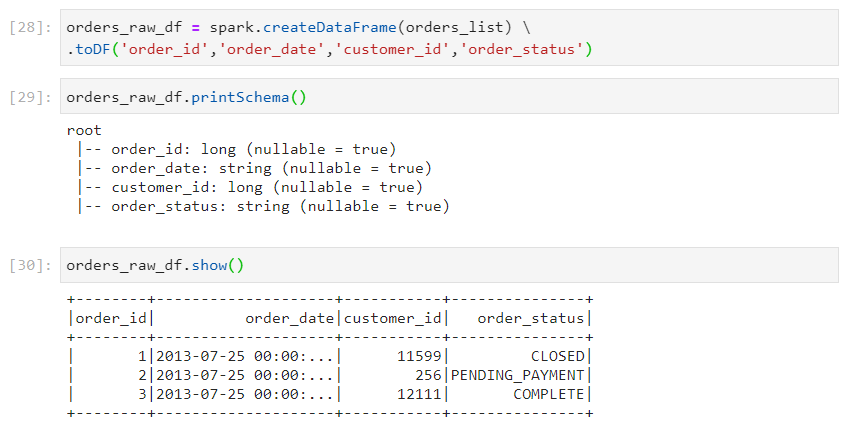
- Using a local list to create a dataframe
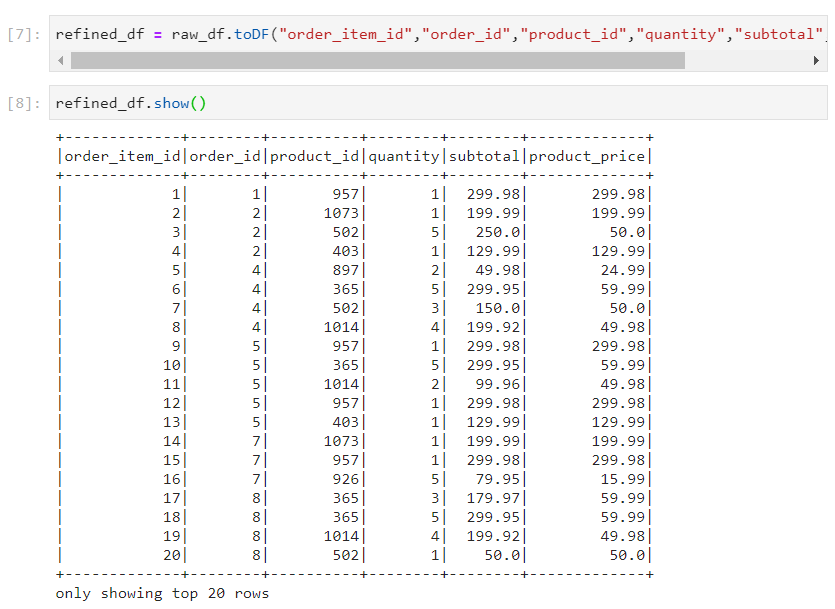
- For fixing the column names in the above dataframe, we can explicitly specify the column names, using toDF() function.
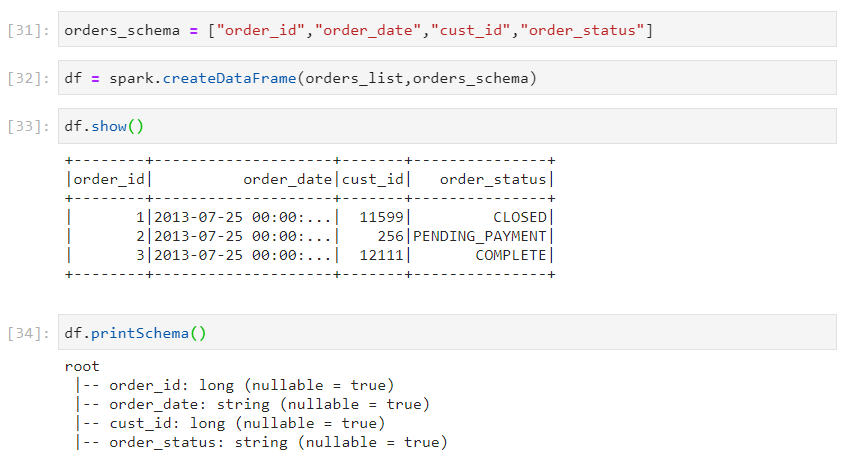
- On similar lines, a dataframe can also be created using a defined schema, using createDataFrame(list, schema) function.
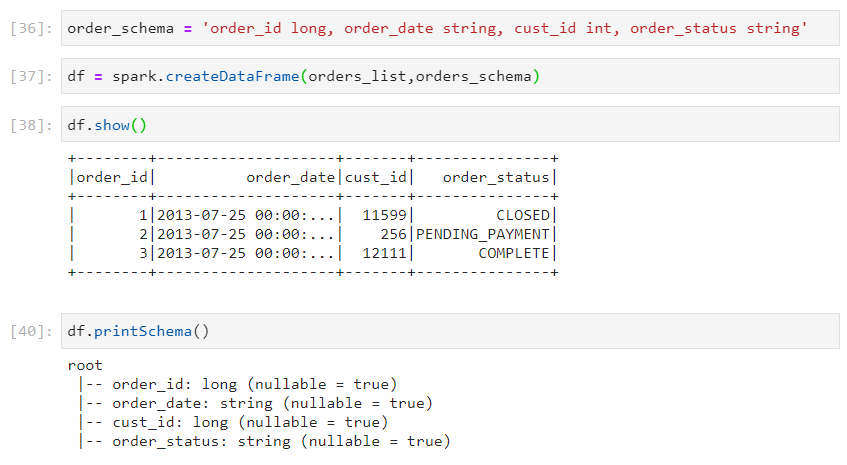
- In addition, we can also specify the datatypes for the columns.
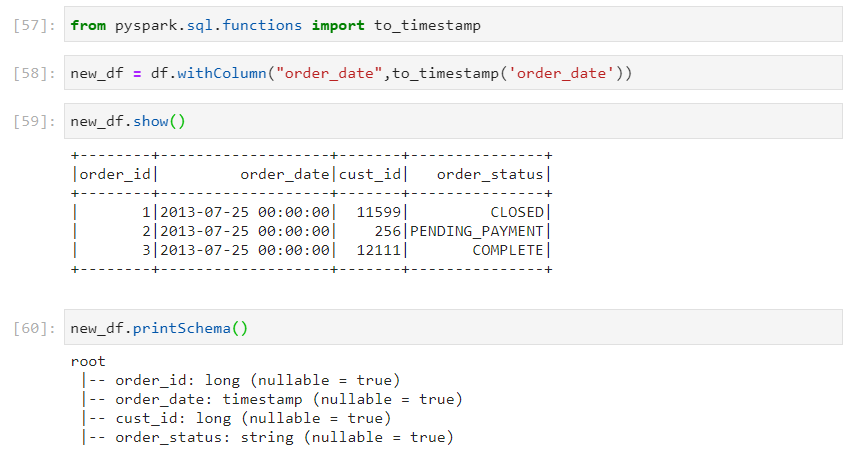
- to_timestamp() transformation can be applied to convert the datatype.
Converting an RDD into a dataframe
Consider the following RDD.
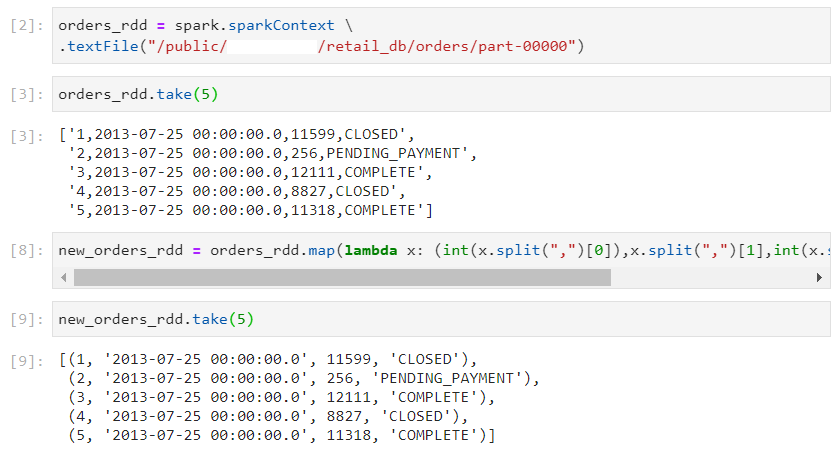
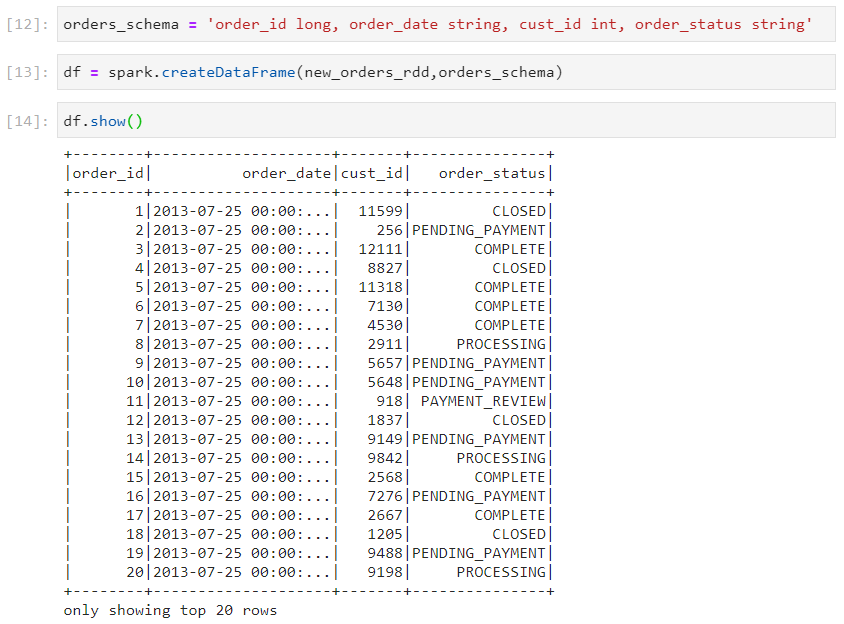
- Using spark.createDataFrame(rdd, schema)

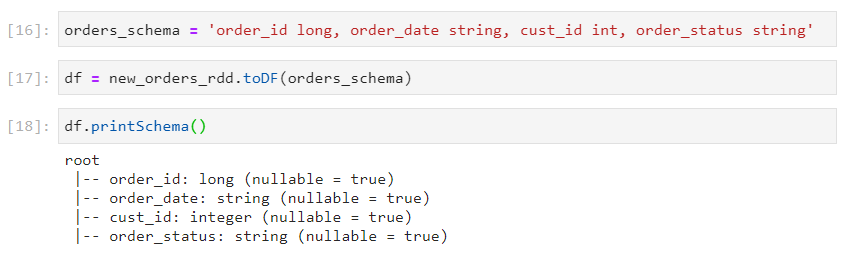
- Using rdd.toDF(schema)
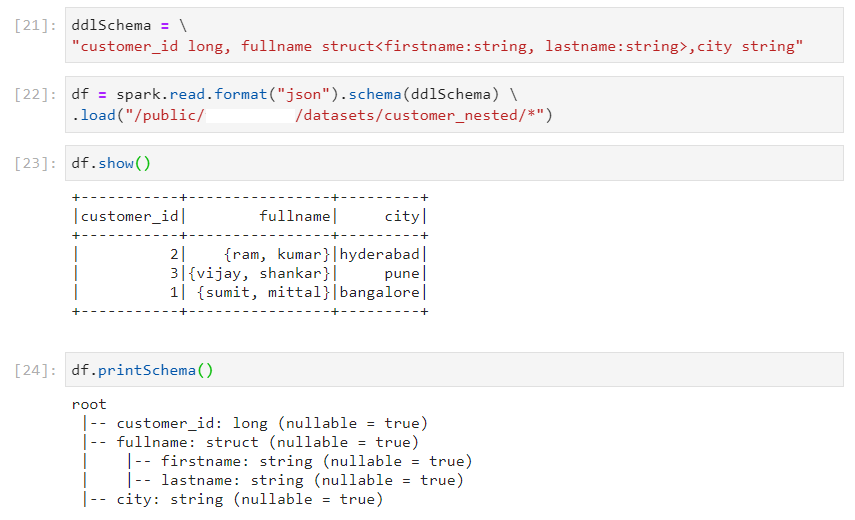
Handling nested schema
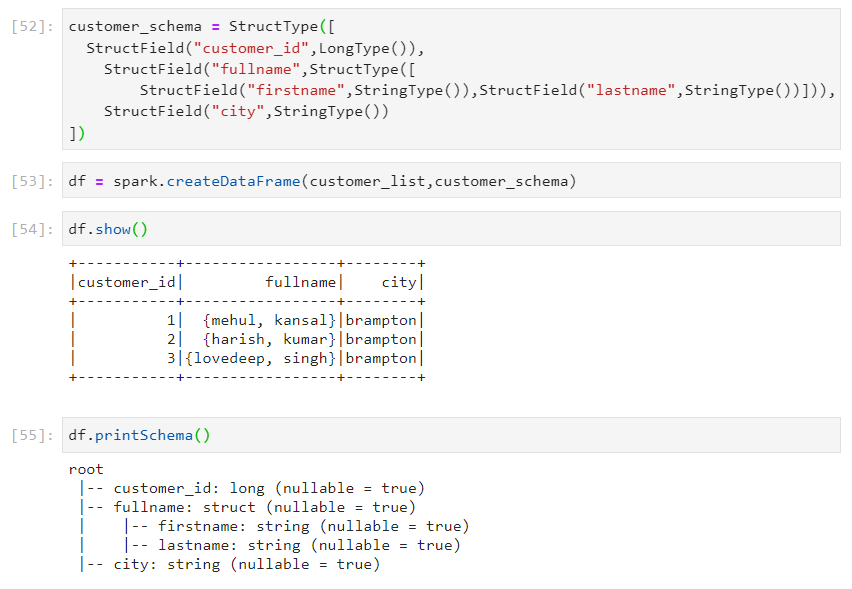
- Consider the following nested schema.

- Approach 1:
- Approach 2:
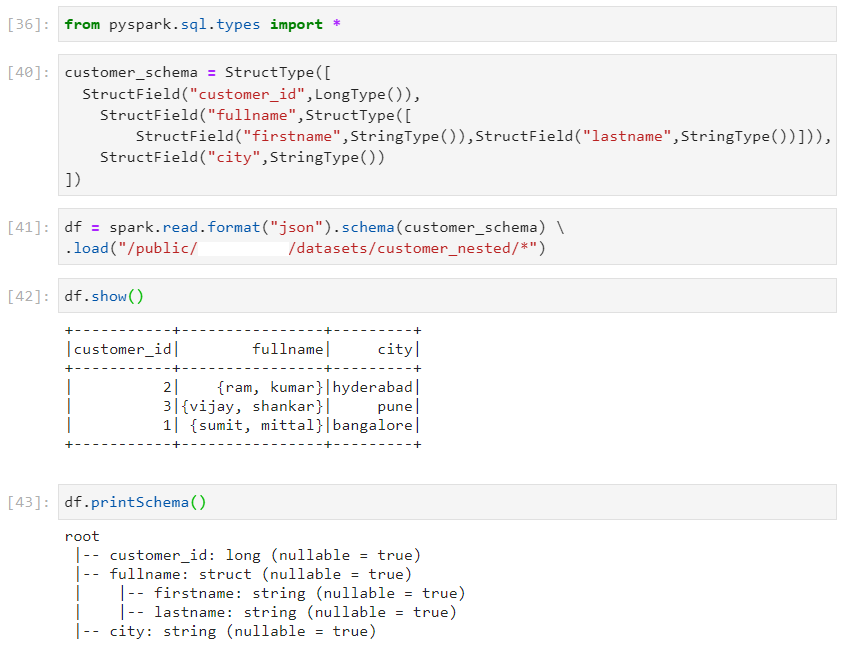
- Using approach 1 again.
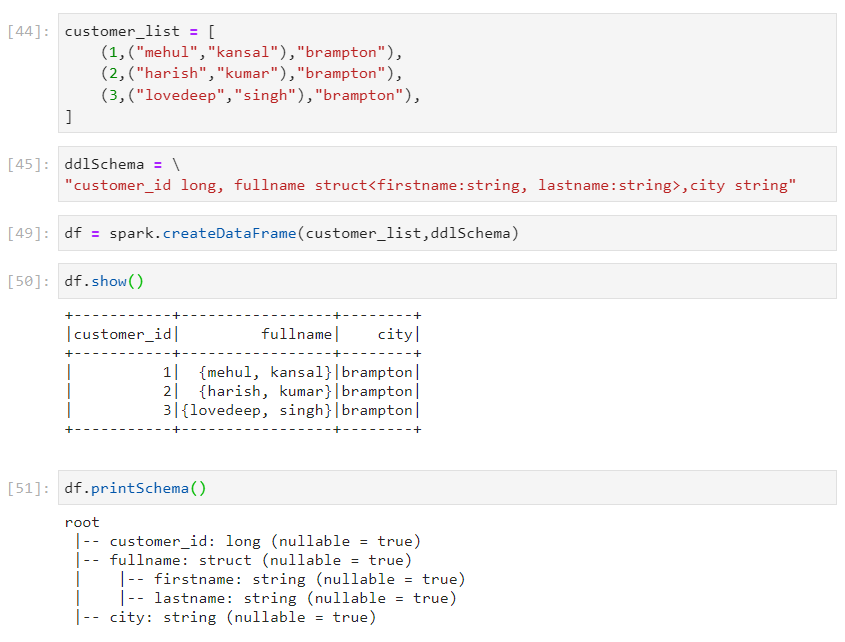
- Using approach 2 again.
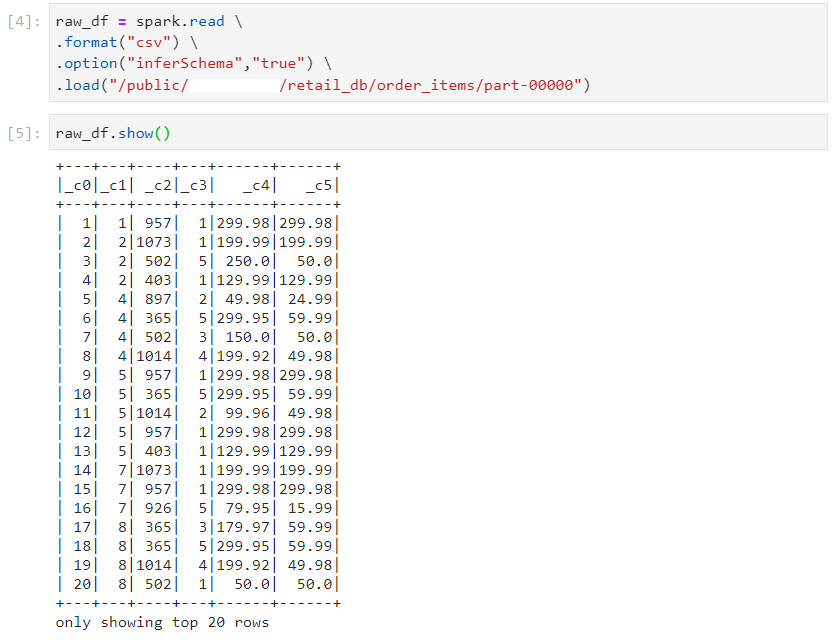
Dataframe transformations
- Consider the following dataframe.
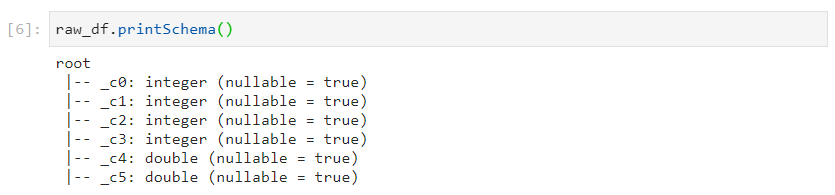
- Refining the column names.
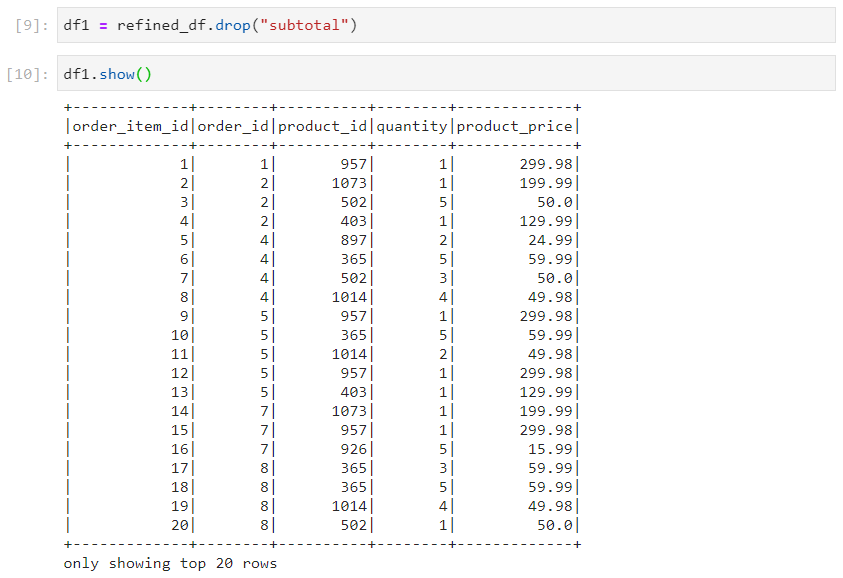
- For dropping a specific column.
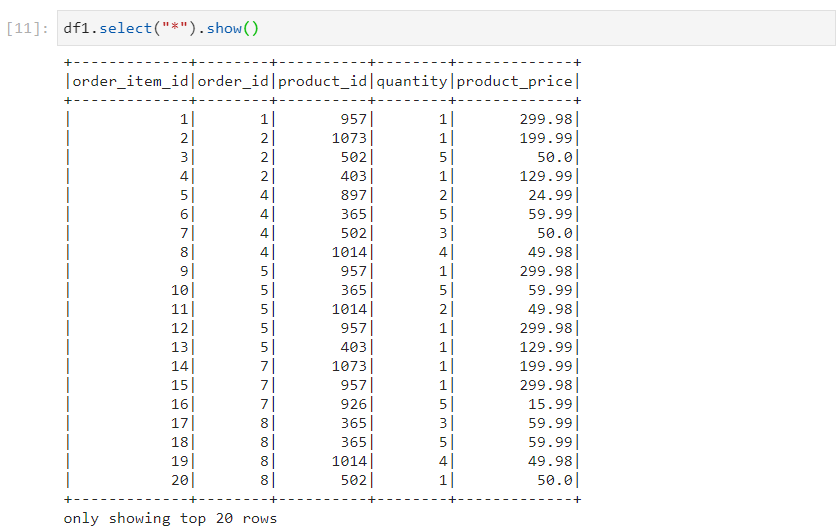
- For selecting all the columns in the dataframe.
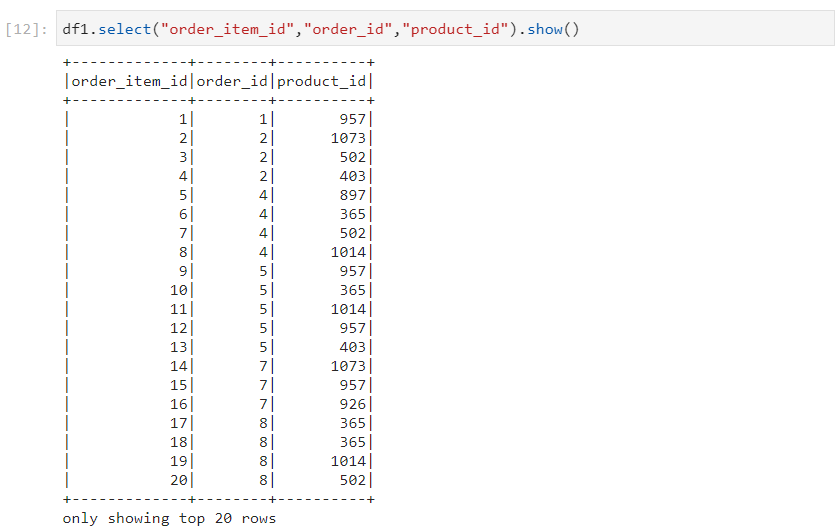
- For selecting particular columns only.
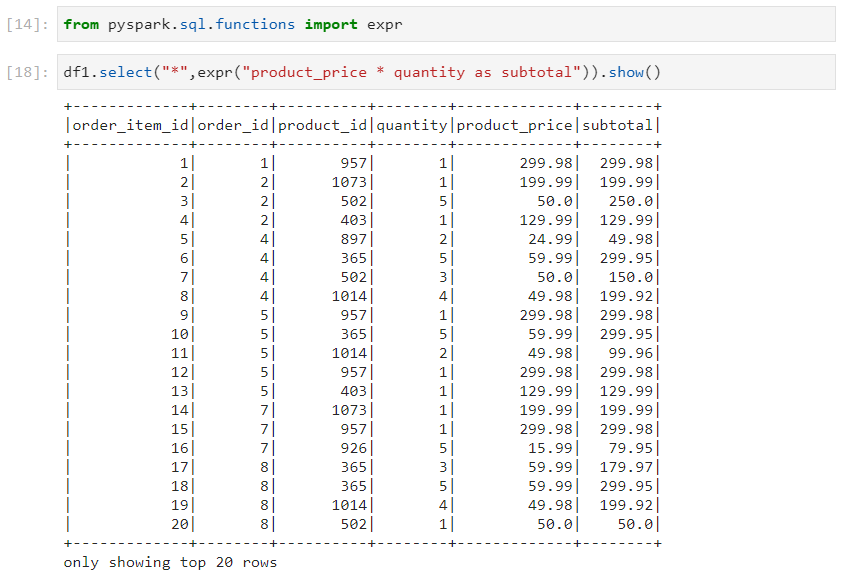
- While using select, we explicitly segregate the expressions in expr().
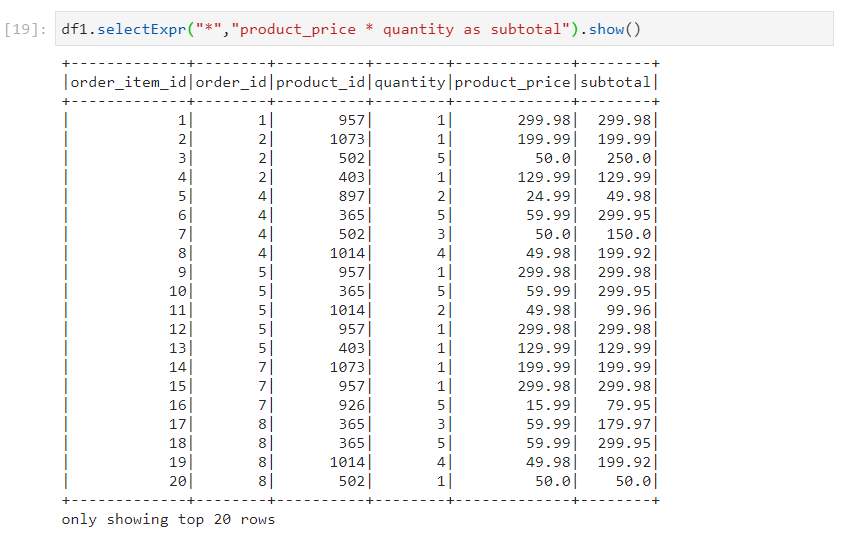
- In case of selectExpr, column names and expressions are implicitly identified.
- On similar lines, consider the following use case.
- Refining the columns
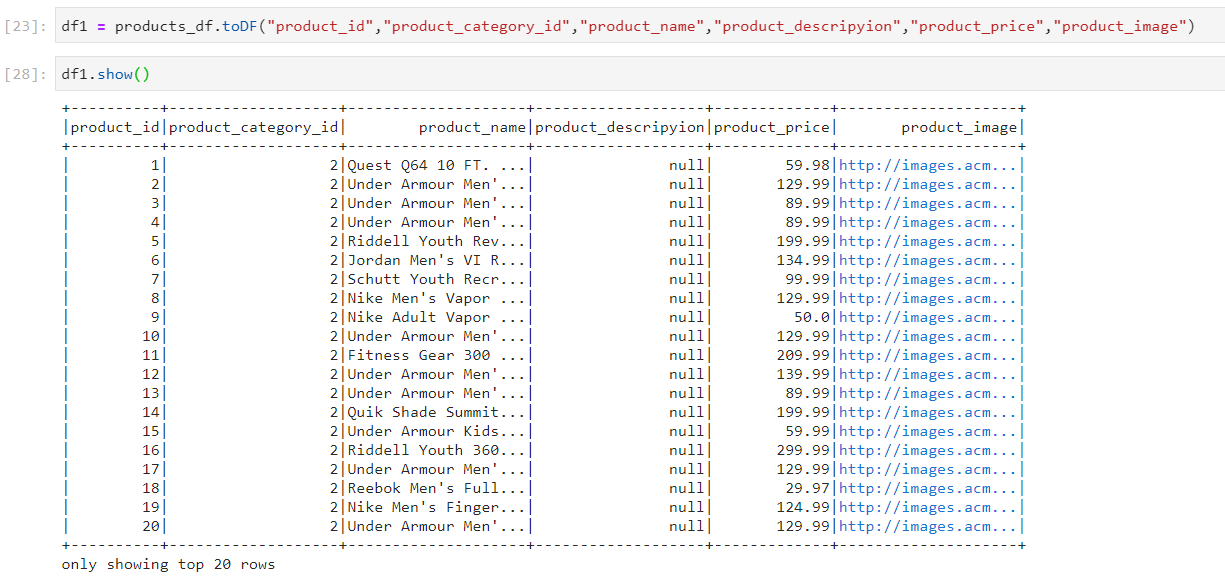
- Using expressions.
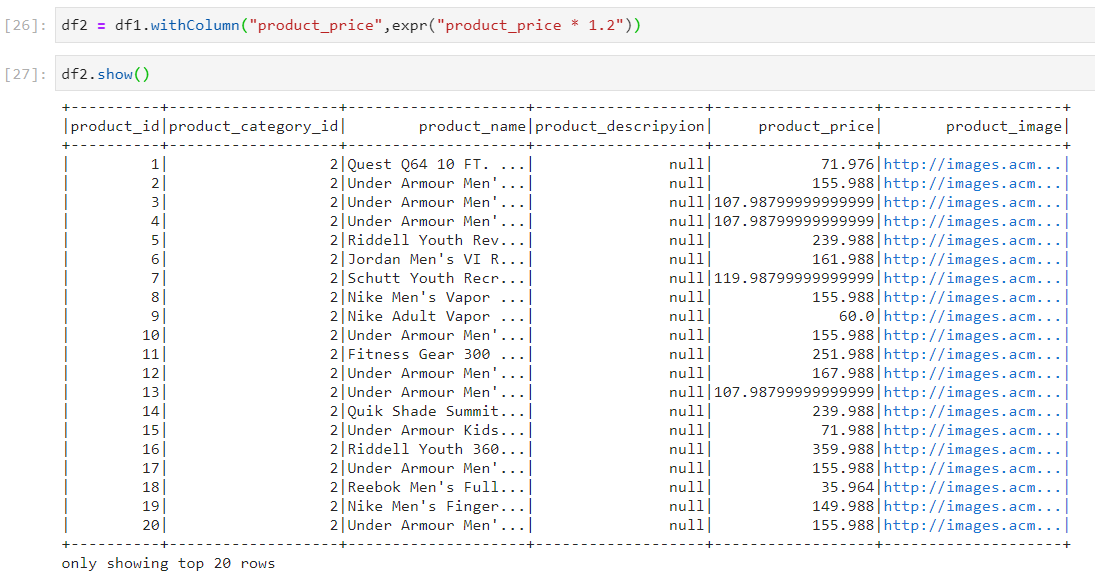
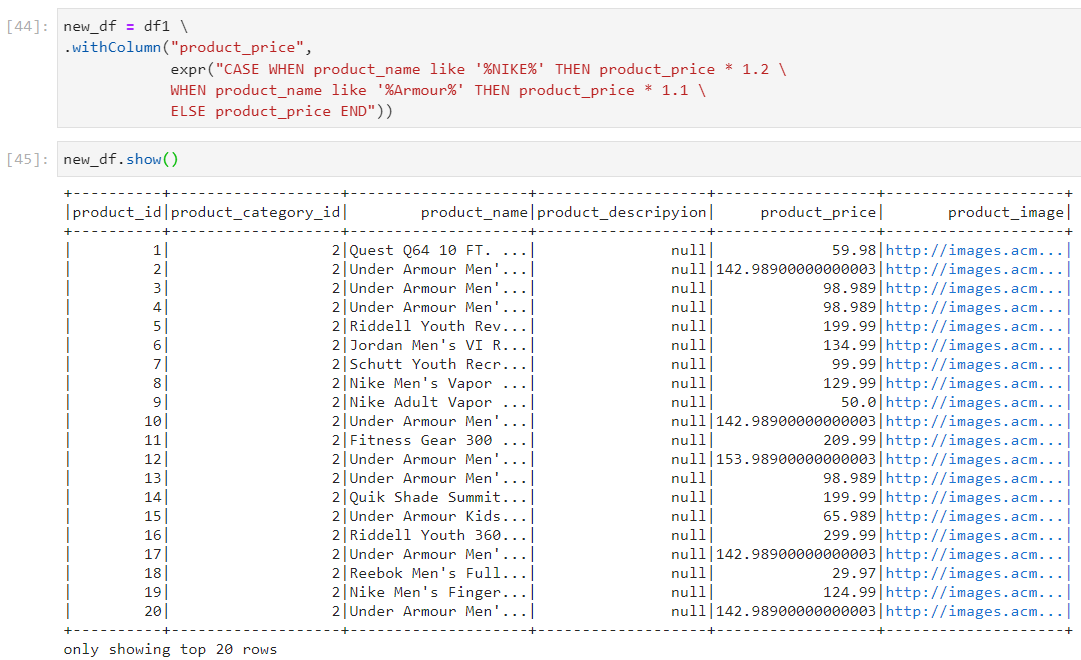
Removal of duplicates from dataframe
- Consider the following local list and the corresponding dataframe.
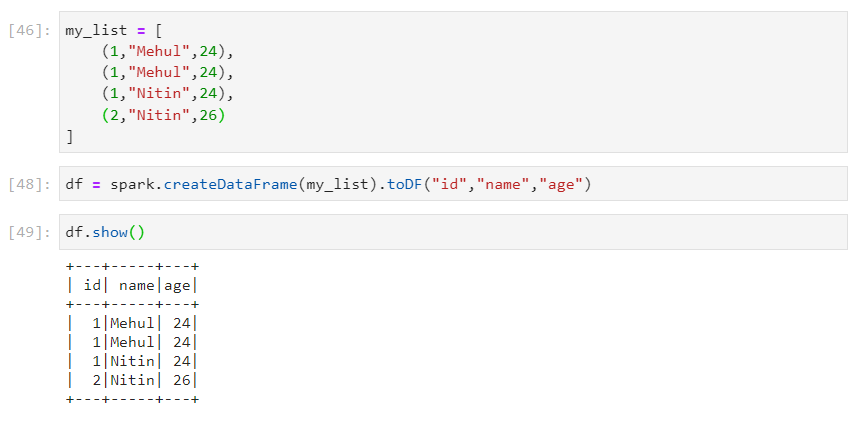
- distinct() removes duplicates after considering all the columns.
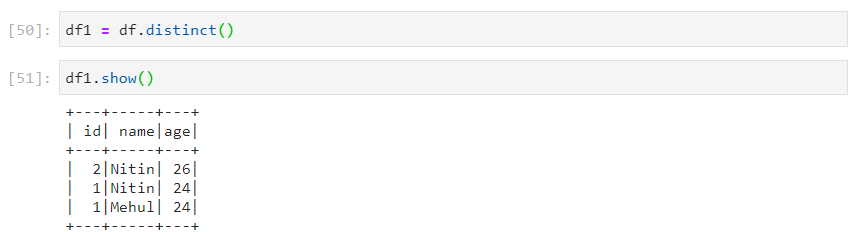
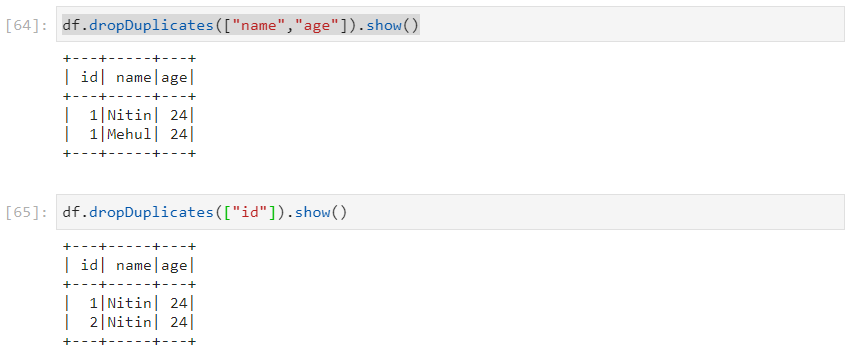
- dropDuplicates() removes duplicates after considering a subset of columns.
Creation of Spark Session
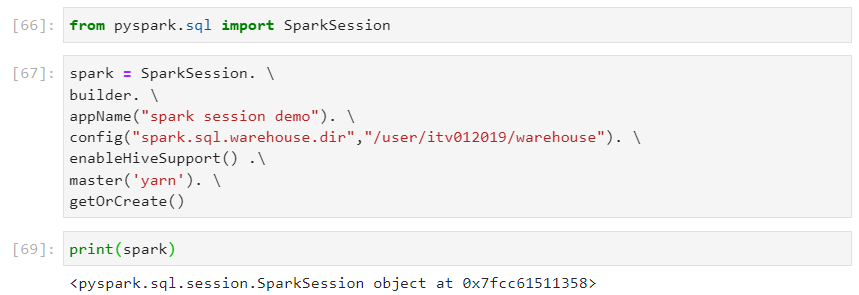
Spark session encapsulates different contexts like Spark context, Hive context, SQL context, etc. and acts as an entry point to the Spark cluster.
Spark session is particularly useful when we have to create more than one spark sessions for a single application, with their respective isolated environments.
Creating the first spark session object.
- Creating the second spark session object.
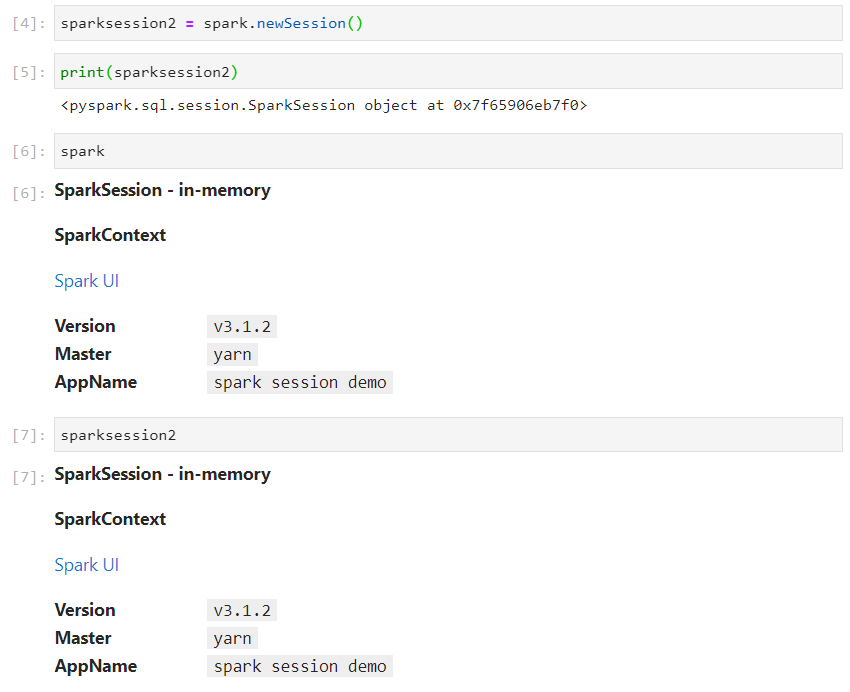
- Consider the following use case.
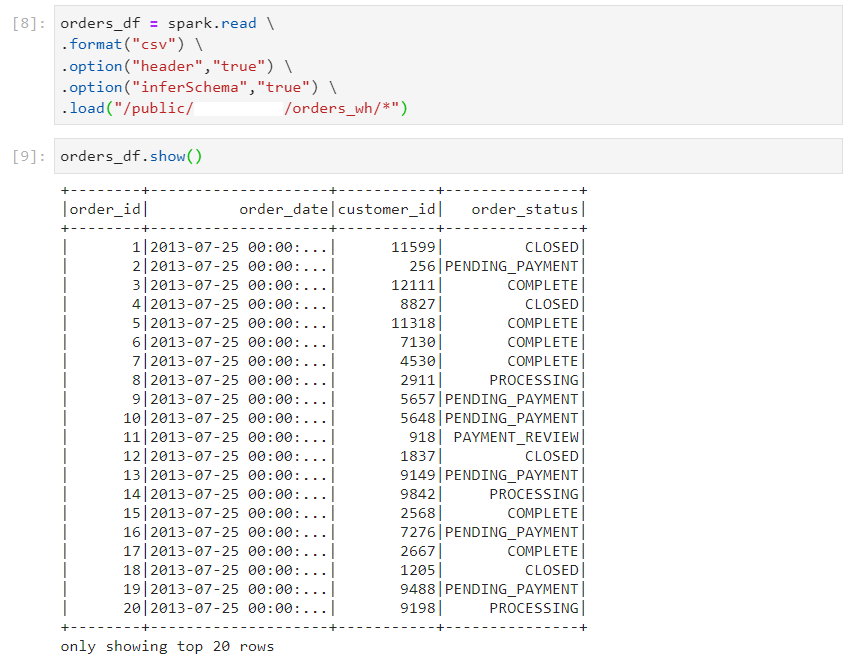
- We create a local view using one spark session.
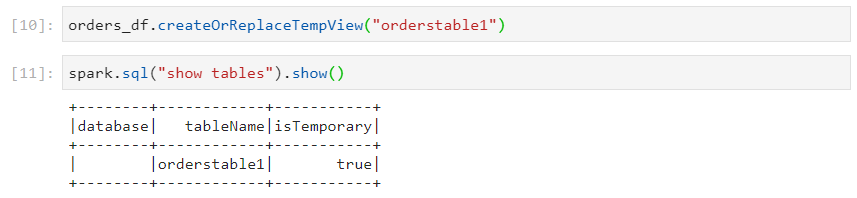
- This view is not visible in the second spark session.

- Now, if we create a global view in one spark session.
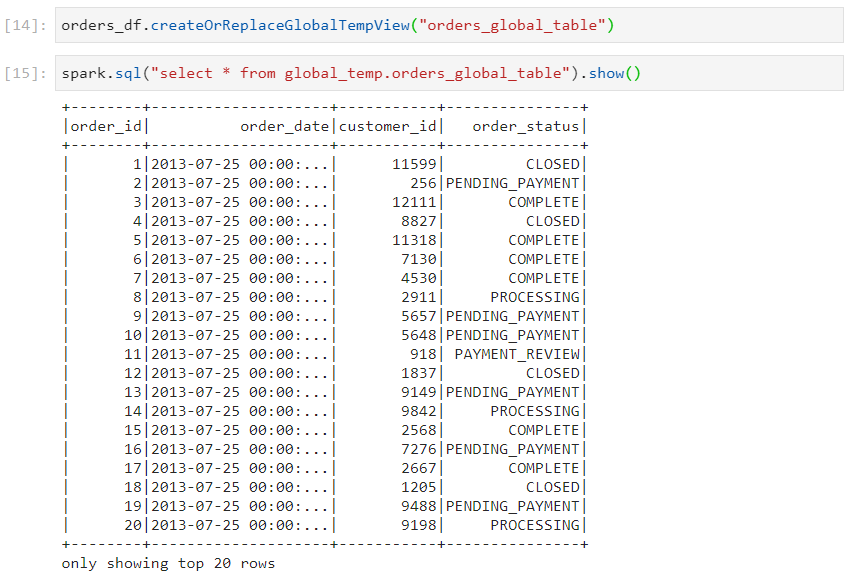
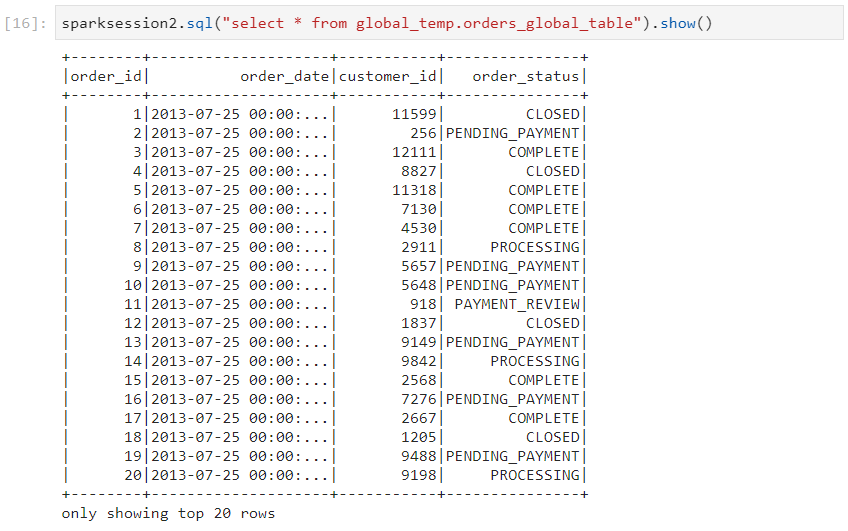
- The global view will be available in the second spark session as well.
Conclusion
By now, we've delved into the world of Spark dataframe transformations and uncovered the powerful techniques of handling schema and data types. These skills are essential for any data engineer looking to optimize data processing and ensure data integrity.
Stay tuned for next week's blog where we'll explore another exciting aspect of data engineering. Until then, keep transforming your data like a pro!
Subscribe to my newsletter
Read articles from Mehul Kansal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by