Benchmarking UUID vs ULID for DB indexing
 Syed Jafer K
Syed Jafer K
In DB, for unique identifiers we are using UUID (Universally Unique Identifier) and ULID (Universally Unique Lexicographically Sortable Identifier).
TL;DR
CODE:https://github.com/syedjaferk/benchmarking_uuid_vs_ulid
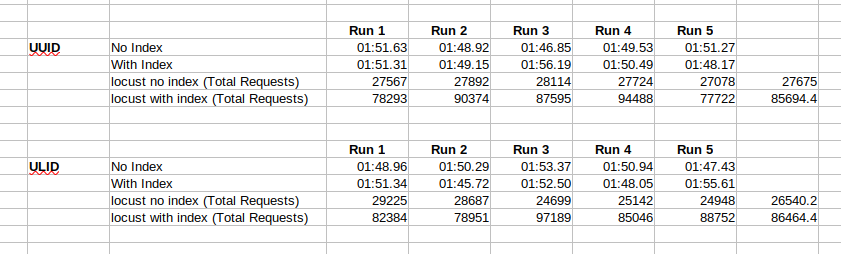
There was no big difference between ULID and UUID on indexing runs.
ULID ids performed good on reads compared to UUID.
Insertion for both UUID and ULID are almost same.
UUID:
UUIDs are standardized 128-bit identifiers. There are different versions of it. In this experiment we use uuid-4 which is randomly generated id. Also this is the most used id in applications.
ULID:
ULIDs are 128-bit identifiers that are designed to be sortable based on time and provide a more compact and readable format. They are composed of two parts:
Timestamp (48 bits): Encodes the number of milliseconds since Unix epoch (January 1, 1970).
Randomness (80 bits): Provides uniqueness.
A ULID example looks like this: 01HZBFHT49F3NWC2QJVAZE4SS1
In this benchmarking experiment, we are going to check fact ULID performs better than UUID in DB (under the usecase where are just care about uniqueness)
Stack used for benchmarking
Database: MongoDB
Application: FastAPI
Performance Testing: Locust
We are going to check,
Insert 1M data with UUID to a new collection without having index.
Insert 1M data with ULID to a new collection without having index.
Insert 1M data with UUID to a new collection with index.
Insert 1M data with ULID to a new collection with index.
Run get requests with 100 users at 100 spawn rate for 2 min for ulid collection without index.
Run get requests with 100 users at 100 spawn rate for 2 min for ulid collection with index.
Run get requests with 100 users at 100 spawn rate for 2 min for uuid collection without index.
Run get requests with 100 users at 100 spawn rate for 2 min for uuid collection with index.
Let's create the base data for benchmarking
We are using Faker python package to generate 1M fake data.
we have written this data to mock.json file. This will create all the test json files for our testing.
Benchmarking
Let's spin up a mongodb container.
docker run -p 27017:27017 --name mongo_container --rm mongo and create a database named ulid_vs_uuid
Insert 1M data with UUID to a new collection without having index.
create a collection named, uuid_no_index .
The below script will read the data from mock.json file created using faker and inserts it into the db collection.
Insert 1M data with ULID to a new collection without having index.
create a collection named, ulid_no_index .
The below script will read the data from mock.json file created using faker and inserts it into the db collection.
Insert 1M data with UUID to a new collection with index.
create a collection named uuid_with_index and set the index field to id with order as desc -1
The below script will read the data from mock.json file created using faker and inserts it into the db collection.
Insert 1M data with ULID to a new collection with index.
create a collection named ulid_with_index and set the index field to id with order as desc -1
The below script will read the data from mock.json file created using faker and inserts it into the db collection.
After writing in to the db,
Run get requests with 100 users at 100 spawn rate for 2 min for ulid collection without index.
For this test, we wrote a fastapi application, which connects to the mongodb and fetches the data from it. Run it using uvicorn <file_name>:app --port 8000
To performance test it, we have created a locust file,
Run the locust file with 100 users 100 spawn rate for 2 min. locust -f <file_name.py> -u 100 -r 100 -t 2m
Run get requests with 100 users at 100 spawn rate for 2 min for ulid collection with index.
For this test, we wrote a fastapi application, which connects to the mongodb and fetches the data from it. Run it using uvicorn <file_name>:app --port 8000
To performance test it, we have created a locust file,
Run the locust file with 100 users 100 spawn rate for 2 min. locust -f <file_name.py> -u 100 -r 100 -t 2m
After indexing we are able to handle more requests.
Run get requests with 100 users at 100 spawn rate for 2 min for uuid collection without index.
For this test, we wrote a fastapi application, which connects to the mongodb and fetches the data from it. Run it using uvicorn <file_name>:app --port 8000.
To performance test it, we have created a locust file, which consumes uuid.json (a file which contains the details of all the ids inserted in to the db)
Run get requests with 100 users at 100 spawn rate for 2 min for uuid collection without index.
For this test, we wrote a fastapi application, which connects to the mongodb and fetches the data from it. Run it using uvicorn <file_name>:app --port 8000.
To performance test it, we have created a locust file, which consumes uuid.json (a file which contains the details of all the ids inserted in to the db)
Subscribe to my newsletter
Read articles from Syed Jafer K directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by