Hashnode 🤙🏽 calls your endpoints. Serverless Webhooks with AWS Step Functions
 Sandro Volpicella
Sandro Volpicella
In our last internal hackathon, Jannik Wempe and Sandro Volpicella built one of the most requested enterprise features - Webhooks.
The problem.
Imagine you host your headless blog on Hashnode. Your frontend consists of statically generated HTML pages. You need to trigger your build process once you publish a new blog post. This is one example where webhooks can help you. Once you click publish we automatically call your desired endpoint with an event.
The solution. Building webhooks.
Hashnode's architecture is mainly based on an event-driven architecture (EDA). That means that almost every action a user is doing emits events. For example:
user publishes a post
user updates the publication
user changes the name
These events result in an event to a central event broker (Amazon EventBridge). The idea of building webhooks is to allow customers to react to these events as well. We forward the events, sign it with a secret, and the users can flexibly react to them.
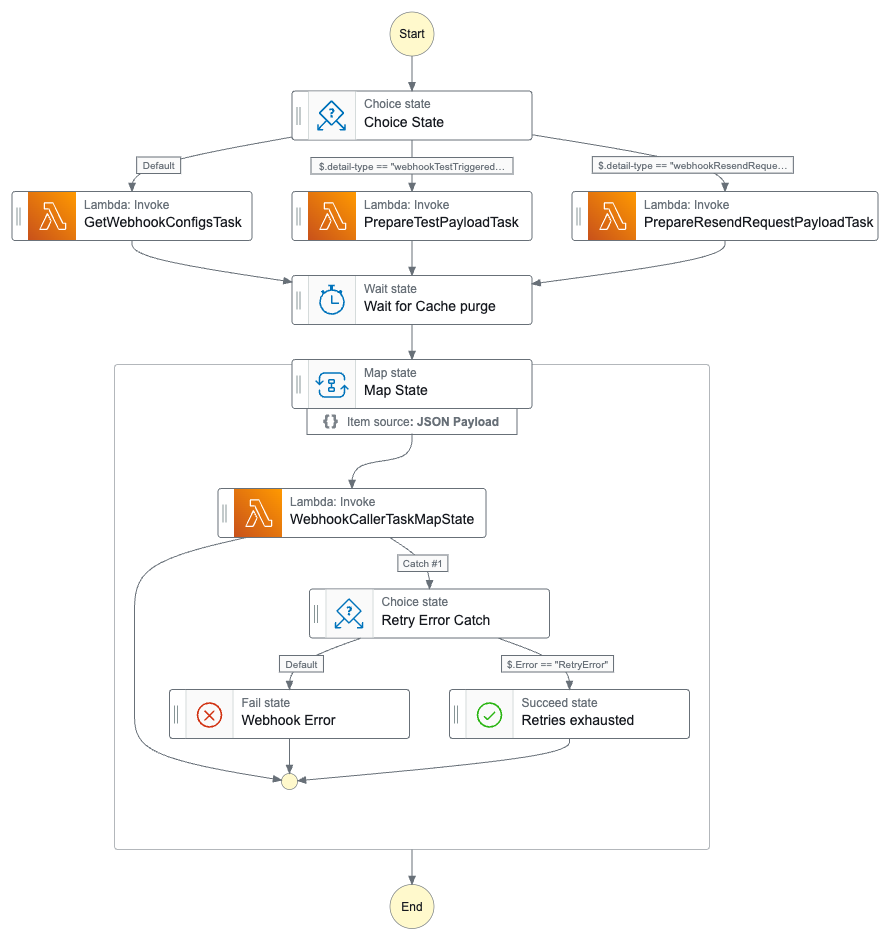
Building webhooks as a multi-step process
There are several steps involved in building webhooks.
Get the webhook configuratoin
Wait to avoid caching/purging race conditions
Loop over all configured webhooks and call them
This was our MVP sketch during the hackathon:

The final Step Function looks like that:
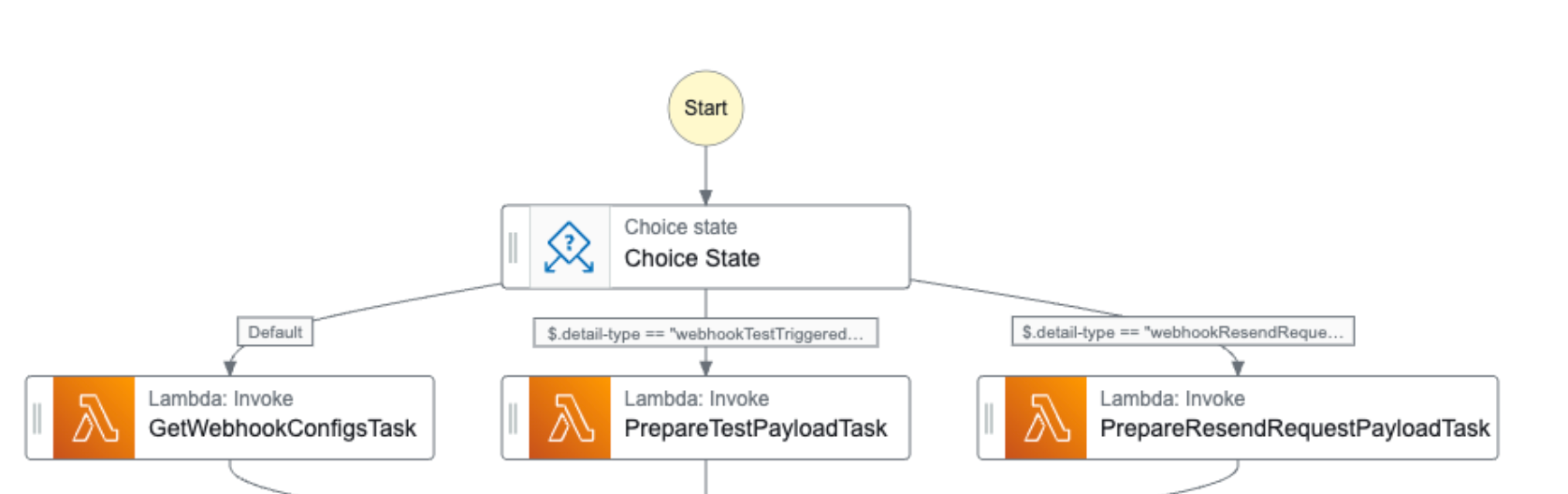
The Step Function will be triggered by certain events. At this moment these events are:
post published
post updated
post removed
static page published
static page updated
status page removed
When one of these events occurs, one or more Step Functoins are invoked.
Webhook Test vs. Webhook Resends
There are two special cases in our webhook Step Function.
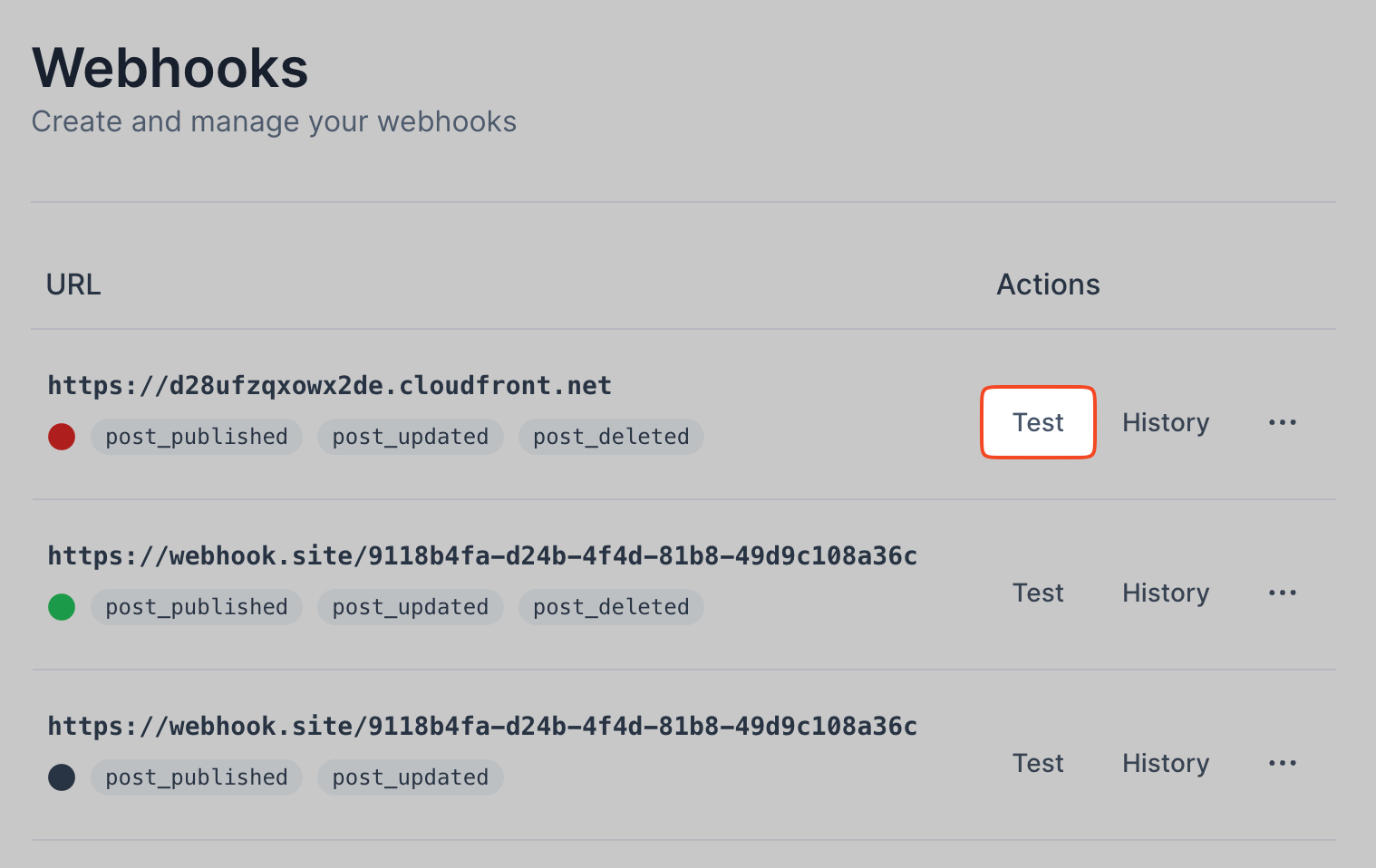
There are two events that can be manually triggered from the webhook console.
Webhook Test: Manually send a payload to your webhook
This will send an example event to your defined webhooks. It is useful for testing your consumer systems.
Resending Webhook Messages:
The second special case is resending webhook messages. Messages may fail on your consumer. Or you want to process some event again. This is where resending the message can help.
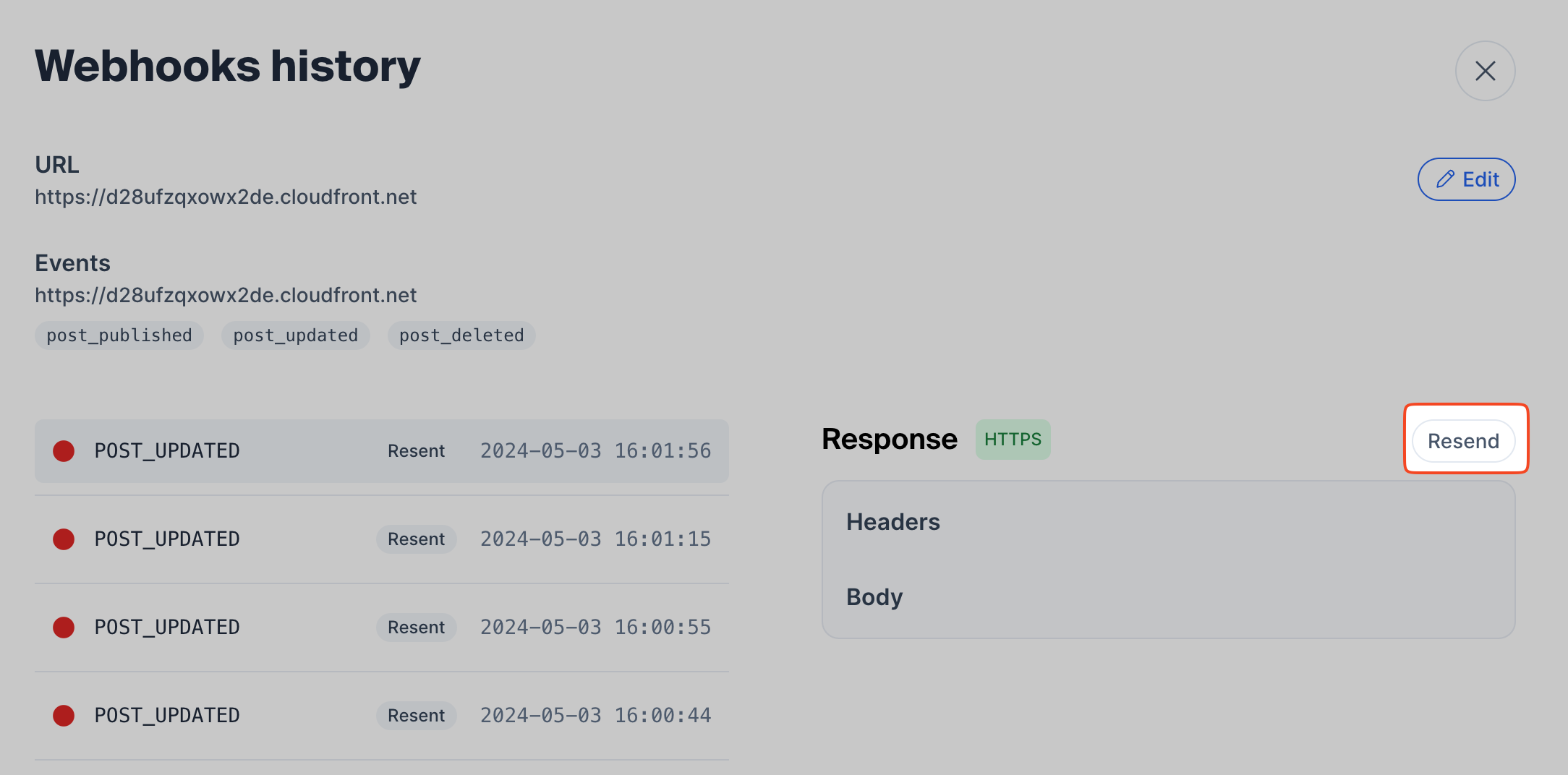
Executing all configured webhooks
The typical flow of a webhook task looks like the following:
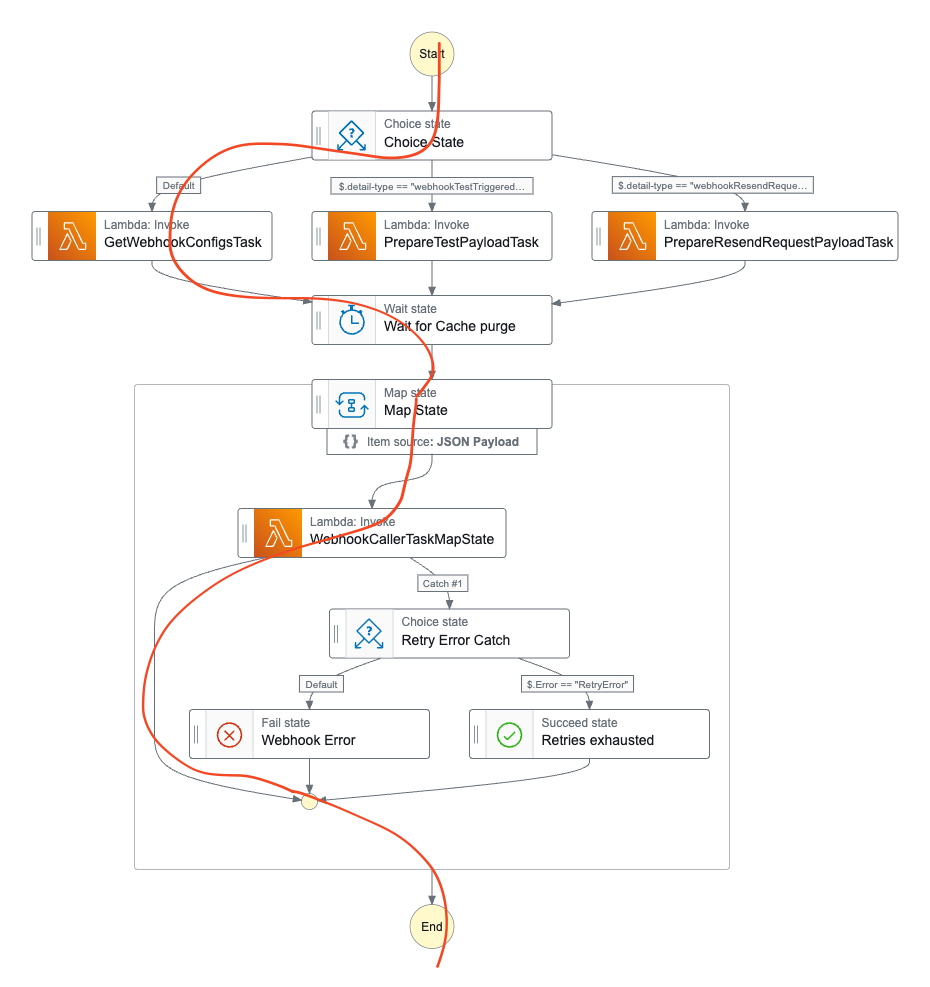
First, we get the webhook configs. A user can configure multiple webhooks based on the same event. For example, once a new blog post is published the user wants to:
Trigger the build process
Posts it to his GitHub Bio
The Map State iterates over all available webhooks. Within one map execution, the Lambda function calls the webhook and updates the database.
The call to the actual webhook looks like this:
const response = await got.post(url, {
json: payload,
headers: {
"User-Agent": "HashnodeWebhooks/1.0 (https://hashnode.com/)",
},
timeout: {
request: 30_000,
},
// the step function handles the retries
retry: 0,
throwHttpErrors: false,
followRedirect: true,
maxRedirects: 3,
hooks: {
beforeRequest: [
async (options) => {
// always recreating the signature because it has a limited lifetime and thus should be fresh
const { encodedHeader } = await sign({
payload,
signingSecret: decryptedSecret,
});
options.headers = {
...options.headers,
...encodedHeader,
};
logger.info("Sending request", {
payload,
headers: options.headers,
});
},
],
},
});
We are not using any retries within the Lambda function. Because the Step Function should handle all timeouts and errors.
Retrying RetryError
Of course, the Lambda function can fail. We have two type of errors:
RetryError- this error retries the execution againAll other errors - these errors won't be retried
We defined a RetryError so that we can retry specific errors. We retry if the following happens:
the response status code is >299
a request error happens
We don't retry if any other part of the Lambda function fails. If the database update fails, it is an actual error and won't be retried.
In the Lambda function we have configured a custom retrier for that:
{
"ErrorEquals": ["RetryError"],
"IntervalSeconds": 10,
"MaxAttempts": 3,
"BackoffRate": 2
}
If this special error occurs we retry up to 3 times with a backoff rate of 2 and an interval of 10 seconds.
The Step Function succeeds because the issue seems to be on the receiver side. The Step Function only fails if we have to look into it. E.g. if the Lambda fails while saving a database entry, that means even if the webhook call itself was unsuccessful, the Step Function will succeed.
This is defined in the following catch task:
webhookCallerLambdaTask.addCatch(
// Choice state to catch RetryError and continue
new sfn.Choice(this, "Retry Error Catch")
.when(
sfn.Condition.stringEquals("$.Error", "RetryError"),
new sfn.Succeed(this, "Retries exhausted")
)
.otherwise(
// Otherwise, fail the state machine
new sfn.Fail(this, "Webhook Error", {
cause: "Error happened in the webhook executor.",
error: "Error in Webhook Caller",
})
)
);
That's it!
I hope we could shed some light on our implementation of webhooks at Hashnode. If you have any questions don't hesitate to ask in the comments!
Subscribe to my newsletter
Read articles from Sandro Volpicella directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sandro Volpicella
Sandro Volpicella
I am a fullstack engineer working here @ hashnode. I love the cloud and really like to build serverless things that scale. https://awsfundamentals.com 📕 https://cloudwatchbook.com 📙