Go Concurrency: Building Blocks
 Basel Rabia
Basel RabiaTable of contents
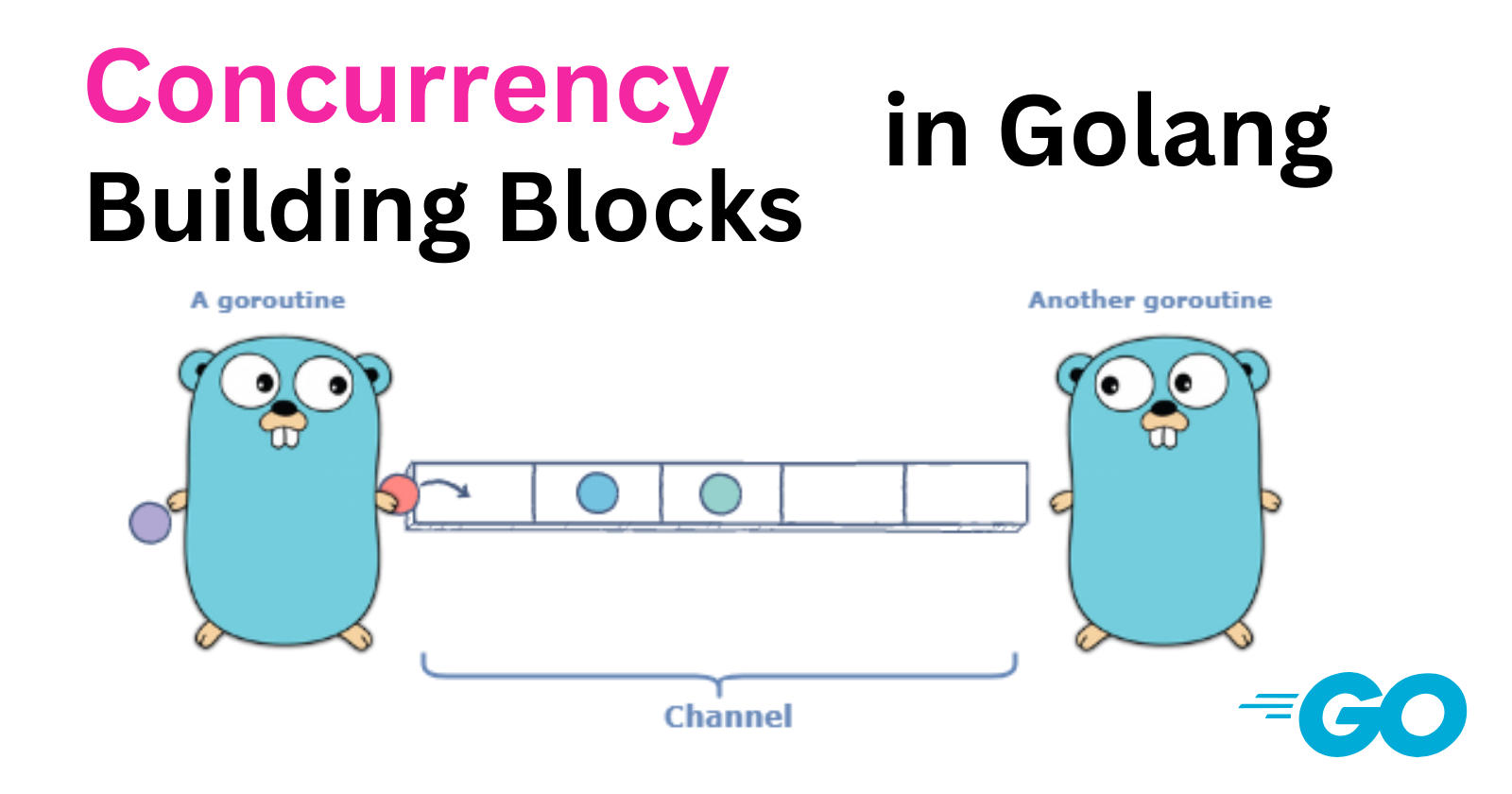
In Go, concurrency is a fundamental concept that allows multiple processes to be executed simultaneously, making efficient use of CPU time and resources. Go provides several key building blocks for implementing concurrency, which are designed to be simple yet powerful.
Go provides two ways to handle concurrency:
Low-level synchronization (sync package): This is similar to what you might find in other languages and is for fine-grained control over memory access.
Higher-level concurrency primitives: Go provides built-in tools like goroutines and channels that offer a more structured way to handle concurrency, often recommended over manual memory access synchronization.
Here are the main concurrency Building Blocks in Go:
Goroutines
a goroutine is a function that is running concurrently alongside other code. You can start one simply by placing the go keyword before a function, or anonymous function
func main() {
// ## regular function
go sayHello()
// continue doing other things
// ## anonymous function
go func() {
fmt.Println("hello")
}()
// continue doing other things
}
func sayHello() {
fmt.Println("hello")
}
Nature of Goroutines
Not OS Threads: Goroutines are not OS threads. Instead, they are more lightweight and managed by the Go runtime. They have much lower overhead in terms of memory and setup time compared to OS threads.
M:N Scheduling: Go implements a form of M:N scheduling, where M goroutines (which you can think of as lightweight processes or tasks) are multiplexed onto N OS threads managed by the Go runtime. The runtime has its own internal scheduler that handles the allocation of goroutines to available OS threads.
Stack Management: Each goroutine starts with a small stack that grows and shrinks as needed. This is more memory efficient compared to traditional threads, which typically have a fixed stack size that is usually much larger.
Comparison with Green Threads
Goroutines are often compared to green threads because both are scheduled by a runtime rather than the operating system. However, goroutines are usually more dynamic due to their stack management and tight integration with Go’s runtime, which optimizes scheduling, network I/O, and memory usage.
Creation and Limits
Theoretically, the number of goroutines you can create is only limited by the available system memory. Goroutines are extremely lightweight, often requiring only a few kilobytes of stack space to start.
In practical applications, it's not uncommon to run thousands or even tens of thousands of goroutines concurrently. The exact number you can create depends on the resources required by each goroutine and the total system resources (like memory).
The efficiency of goroutines comes from their lightweight nature and the effective scheduling done by the Go runtime, which makes decisions about when and how to execute them. This model allows developers to write highly concurrent applications without the complexity typically associated with managing threads directly.
Channels
Channels are concurrency primitives that enable communication and synchronization between goroutines. They serve as a pipe through which values can be sent and received, allowing different parts of a program to communicate safely and efficiently without direct knowledge of each other. Channels can be passed around to different parts of a program, making them flexible and powerful tools for managing concurrency.
While they can be used to synchronize access of the memory, they are best used to communicate information between goroutines
Creating a channel is very simple. Here’s an example
//// declare a channel.
// “of type” interface{} - empty interface.
var dataStream chan interface{}
// instantiate the channel
dataStream = make(chan interface{})
Channels are typed
In this example, we created a chan interface{} variable, which means that we can place any kind of data onto it, but we can also give it a stricter type to constrain the type of data it could pass along. Here’s an example of a channel for integers;
intStream := make(chan int)
How to use channels
Sending is done by placing the <- operator to the right of a channel, and receiving is done by placing the <- operator to the left of the channel
stringStream := make(chan string)
go func() {
// send (pass) a string literal onto the channel stringStream.
stringStream <- "Hello channels!"
}()
// Read the string literal off of the channel and print it out
fmt.Println(<-stringStream)
Unidirectional flow Channels
Read Channel
simply including the <- operator. To both declare and instantiate a channel that can only read, place the <- operator on the left-hand side, like so:
var dataStream <-chan interface{}
dataStream := make(<-chan interface{})
// Real use of it
func receiveOnly(ch <-chan int) {
for val := range ch {
fmt.Println(val)
}
}
Send Channel
create a channel that can only send, you place the <- operator on the right hand side, like so:
var dataStream chan<- interface{}
dataStream := make(chan<- interface{})
// Real use of it
func sendOnly(ch chan<- int, data []int) {
for _, val := range data {
ch <- val
}
close(ch)
}
Channels are Blocking
Channels in Go are said to be blocking. This means that:
Any goroutine that attempts to write to a channel that is full will wait (block) until there is space available in the channel.
Any goroutine that attempts to read from a channel that is empty will wait (block) until there is data available in the channel.
Blocking channels in Go can cause deadlocks if the program is not structured correctly. Consider the following example, which introduces a condition preventing the anonymous goroutine from placing a value on the channel:
stringStream := make(chan string)
go func() {
// always return -
if 0 != 1 {
return
}
// without placing a value on the channel.
stringStream <- "Hello channels!"
}()
// main goroutine waits (blocked) to read a value from the channel,
// which will never receive a value due to the condition
// in the anonymous goroutine.
fmt.Println(<-stringStream)
-------------------------------------------
// Output: This will panic with:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan receive]:
Closed channel
Closing a channel informs all receiving goroutines that no more values will be sent, allowing them to take appropriate actions based on this information.
valueStream := make(chan interface{})
close(valueStream)
Interestingly, we can read from a closed channel in Go. Consider the following example:
intStream := make(chan int)
close(intStream)
integer, ok := <-intStream
fmt.Printf("(%v): %v", ok, integer)
____________________________________
output : (false): 0
Buffered Channels
Buffered channels are channels with a specified capacity, allowing a goroutine to perform a limited number of writes without needing simultaneous reads. This can help manage concurrency more effectively. Here's an overview:
To create a buffered channel, specify its capacity during instantiation:
var dataStream chan interface{}
dataStream = make(chan interface{}, 4)
In this example, dataStream is a buffered channel with a capacity of four, meaning it can hold up to four values before blocking any additional writes.
Buffered channels
allow up to
nwrites (wherenis the capacity) even if no reads are performed.block when they reach their capacity. For example, a buffered channel with a capacity of four will block on the fifth write if no reads have occurred.
Unbuffered channels
essentially buffered channels with a capacity of zero.
block immediately on a write if no read is waiting.
Example: An unbuffered channel and a buffered channel with zero capacity behave equivalently:
a := make(chan int)
b := make(chan int, 0)
Both a and b are channels with a capacity of zero, meaning any write operation will block until a corresponding read occurs.
Buffered channels act as an in-memory FIFO queue, allowing concurrent processes to communicate efficiently.
Writes block if the channel is full,
reads block if the channel is empty,
similar to unbuffered channels but with different preconditions based on capacity.
Put channels in the right context
Assign channel ownership: it's as being a goroutine that instantiates, writes, and closes a channel.
Unidirectional channel declarations allow us to distinguish between goroutines that own channels and the ones that utilize them.
owners have a write-access using (chan or chan<-).
utilizers have a read-only (<-chan).
Assign responsibilities to goroutines that own channels like So :
Instantiate the channel.
Perform writes, or pass ownership to another goroutine.
Close the channel.
Encapsulate the previous three things in this list using a closure function
expose them via a reader channel.
an example to help clarify these concepts, Let’s create a goroutine that owns a channel and a consumer that handles blocking and closing of a channel:
chanOwner := func() <-chan int {
resultStream := make(chan int, 5) // instantiate a buffered channel
go func() { // goroutine encapsulated within the surrounding function
defer close(resultStream) // ensure channel will closed once
for i := 0; i <= 5; i++ {
resultStream <- i // goroutine performs writes
}
}()
return resultStream // return a read-only channel
}
resultStream := chanOwner()
for result := range resultStream {
fmt.Printf("Received: %d\n", result)
}
fmt.Println("Done receiving!")
_______________________________________
This produces:
Received: 0
Received: 1
Received: 2
Received: 3
Received: 4
Received: 5
Done receiving!
Select Statement
The select statement is the glue that binds channels together; compose channels together in a program to form larger abstractions.
Select enables flexible and efficient non-blocking channel communication. By
Allowing a goroutine to wait on multiple channel operations simultaneously
handle non-blocking cases,
implement timeouts,
having a default values
Select operates like a switch statement but for channels. All channel operations within a select block are considered simultaneously. If multiple channels are ready, one is chosen at random to proceed.
Simple Example:
var c1, c2 <-chan interface{}
var c3 chan<- interface{}
select {
case <-c1:
// Handle c1 read
case <-c2:
// Handle c2 read
case c3 <- struct{}{}:
// Handle c3 write
}
Channel Reads and Writes: Reads from channels that are populated or closed, and writes to channels that are not at capacity, will proceed immediately.
Blocking: If no channels are ready, the
selectstatement blocks until one becomes ready.
How the select Statement Works
The select statement evaluates all channel operations simultaneously to determine if any are ready :
Reads: reads From Channels that are populated or closed.
Writes: write to Channels that are not at capacity.
If none are ready,
selectblocks until one becomes ready.
Example
start := time.Now()
c := make(chan interface{})
go func() {
time.Sleep(5 * time.Second)
close(c)
}()
fmt.Println("Blocking on read...")
select {
case <-c:
fmt.Printf("Unblocked %v later.\n", time.Since(start))
}
__________________
This produces:
Blocking on read...
Unblocked 5.000170047s later.
Setup: A channel
cis created and closed after 5 seconds in a goroutine.Blocking Read: The
selectstatement waits forcto become ready (i.e., closed).
This demonstrates the select statement blocking until the channel operation can proceed, in this case, until the channel c is closed after 5 seconds. This approach efficiently handles waiting for multiple channel operations.
Q: What happens when multiple channels have something to read?
Go runtime will perform a pseudo-random uniform selection over the set of case statements. That means each case has an equal chance of being selected as all the others.
c1 := make(chan interface{}); close(c1)
c2 := make(chan interface{}); close(c2)
var c1Count, c2Count int
for i := 1000; i >= 0; i-- {
select {
case <-c1:
c1Count++
case <-c2:
c2Count++
}
}
fmt.Printf("c1Count: %d\nc2Count: %d\n", c1Count, c2Count)
___________________________
This produces:
c1Count: 505
c2Count: 496
Explanation
In 1,000 iterations, the
selectstatement read fromc1andc2approximately equally.This is due to the Go runtime performing a pseudo-random uniform selection among the ready channels.
Key Points
Pseudo-Random Selection: Ensures fair selection among ready channels.
Equal Weighting: Each channel has an equal chance of being selected, promoting average-case efficiency.
The Go runtime cannot infer the specific intent behind the select statement's channel groupings, so it uses random selection to ensure balanced performance across various scenarios. This approach helps Go programs using select to perform reliably in the average case.
Handling Timeouts
Q: what happens if there are never any channels that become ready?
If there’s nothing useful you can do when all the channels are blocked, but you also can’t block forever, you may want to time out.
var c <-chan int
select {
case <-c:
// This case will never unblock because c is a nil channel.
case <-time.After(1 * time.Second):
fmt.Println("Timed out.")
}
ds
Using the default Clause
The select statement can also include a default clause, which allows the program to perform an action if no channels are ready:
start := time.Now()
var c1, c2 <-chan int
select {
case <-c1:
case <-c2:
default:
fmt.Printf("In default after %v\n\n", time.Since(start))
}
This allows the select block to exit immediately without blocking.
For-Select Loop
default clause allows you to exit a select block without blocking. Usually, you’ll see a default clause used in conjunction with a for-select loop. This allows a goroutine to make progress on work while waiting for another goroutine to report a result. Here’s an example of that:
done := make(chan interface{})
go func() {
time.Sleep(5*time.Second)
close(done)
}()
workCounter := 0
loop:
for {
select {
case <-done:
break loop
default:
}
// Simulate work
workCounter++
time.Sleep(1*time.Second)
}
fmt.Printf("Achieved %v cycles of work before signalled to stop.\n", workCounter)
__________________________________
This produces:
Achieved 5 cycles of work before signalled to stop.
loop continues to perform work and checks periodically if it should stop, based on the done channel.
Sync Package
sync package provides low-level primitives for synchronizing memory access in concurrent programs. let’s begin taking a look at the various primitives the sync package exposes.
WaitGroup
It allows you to wait for a group of goroutines (concurrent functions) to finish their execution.
Use cases:
When you don't need the results from each goroutine.
When you have another way to collect the results (like storing them in a shared variable).
Here’s a basic example of using a WaitGroup to wait for goroutines to complete:
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("1st goroutine sleeping...")
time.Sleep(1)
}()
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("2nd goroutine sleeping...")
time.Sleep(2)
}()
wg.Wait() // blocking untill all goroutine finish
fmt.Println("All goroutines complete.")
First call Add with an argument of 1 to indicate that one goroutine is beginning. Then call Done using the defer keyword to ensure that before we exit the goroutine’s closure, we indicate to the WaitGroup that we’ve exited. Then call Wait, which will block the main goroutine until all goroutines have indicated they have exited.
This produces:
2nd goroutine sleeping...
1st goroutine sleeping...
All goroutines complete.
Mutex and RWMutex
they handle concurrency through memory access synchronization, Mutex stands for “mutual exclusion” and is a way to guard critical sections of your program. a critical section *is an area of your program that requires exclusive access to a shared resource*.
Mutexes ensure only one goroutine can access a critical section (shared resource) at a time to prevent race conditions.
Example of two goroutines that are attempting to increment and decrement a common value; they use a Mutex to synchronize access:
var count int
var lock sync.Mutex
increment := func() {
lock.Lock()
defer lock.Unlock()
count++
fmt.Printf("Incrementing: %d\n", count)
}
decrement := func() {
lock.Lock()
defer lock.Unlock()
count--
fmt.Printf("Decrementing: %d\n", count)
}
// Increment
var wg sync.WaitGroup
for i := 0; i <= 5; i++ {
wg.Add(1)
go func() {
defer wg.Done()
increment()
}()
}
// Decrement
for i := 0; i <= 5; i++ {
wg.Add(1)
go func() {
defer wg.Done()
decrement()
}()
}
wg.Wait()
fmt.Println("WaitGroup complete.")
This produces:
Decrementing: -1
Incrementing: 0
Decrementing: -1
Incrementing: 0
Decrementing: -1
Decrementing: -2
Decrementing: -3
Incrementing: -2
Decrementing: -3
Incrementing: -2
Incrementing: -1
Incrementing: 0
WaitGroup complete.
It's crucial to always call Unlock within a defer statement to avoid deadlocks. Entering and exiting critical sections reflect a bottleneck in your program, so aim to minimize the time spent within them. One strategy is to reduce the size of the critical section using RWMutexes, which are better suited for scenarios where multiple goroutines might read the shared data but only a few modify it.
through RWMutexes, You can request a lock for reading, in which case you will be granted access unless the lock is being held for writing. This means that an arbitrary number of readers can hold a reader lock so long as nothing else is holding a writer lock.
Here's a comparison between sync.Mutex and sync.RWMutex in Golang in a tabular format:
| Feature/Aspect | sync.Mutex | sync.RWMutex |
| Type | Mutual Exclusion Lock | Read-Write Mutual Exclusion Lock |
| Primary Use | Ensures only one goroutine can access the critical section at a time | Allows multiple readers or one writer to access the critical section |
| Lock Types | Lock and Unlock | RLock, RUnlock, Lock, and Unlock |
| Read Concurrency | Not concurrent, only one goroutine can access | Concurrent, multiple goroutines can access in read-only mode |
| Write Concurrency | Not concurrent, only one goroutine can access | Not concurrent, only one goroutine can access in write mode |
| Lock Overhead | Low | Slightly higher due to maintaining reader counts |
| Usage Scenario | When you need simple mutual exclusion for critical sections | When you have frequent reads and infrequent writes |
| Performance | Faster for pure write-heavy scenarios | Better performance for read-heavy scenarios |
| Complexity | Simple to use and understand | Slightly more complex due to dual locking mechanisms |
Key Points
sync.Mutex:Simple mutual exclusion.
Suitable for scenarios with frequent writes or where reads and writes are equally frequent.
Only one goroutine can hold the lock at any given time.
sync.RWMutex:Read-write mutual exclusion.
Allows multiple goroutines to read simultaneously but only one to write.
Ideal for scenarios with many read operations and fewer write operations.
Provides
RLockandRUnlockmethods for read-only access, andLockandUnlockmethods for write access.
Subscribe to my newsletter
Read articles from Basel Rabia directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Basel Rabia
Basel Rabia
Hi, I'm Basel Rabia, a Backend Web Developer , Passionate and always doing my best with the aim of improving operational functionality, interested in Laravel, Node.js, NoSQL, Golang