Instance-Based and Model-Based : How They Differ in Machine Learning
 Kshitij Shresth
Kshitij Shresth
Machine learning models, like humans, learn in two main ways: by memorizing and by generalizing. These approaches are known as instance-based learning and model-based learning. Understanding these methods helps us see how different types of machine learning models work and make predictions.
Instance Based
![What is Instance-Based Learning?. [ML0to100] — S1E11 | by Sanidhya Agrawal | Medium](https://miro.medium.com/v2/resize:fit:638/1*rxBUhOROIAbmSQ7EkK7RSQ.png)
In instance-based learning, the model does not explicitly learn from the training data. Instead, it stores the data as it is and uses it during the prediction phase. The model makes predictions by measuring the similarity between new data points and the stored training instances. This approach is often referred to as "lazy learning" because the pattern discovery process is postponed until a query is made.
K-Nearest Neighbors (KNN): This algorithm finds the 'k' most similar data points to the query point and makes predictions based on the majority class among these neighbors.
Radial Basis Function Networks: These use a combination of radial basis functions to approximate the target function based on the distance from stored data points.
Kernel Methods: These methods, used in algorithms like Support Vector Machines rely on kernel functions to measure the similarity between data points.
It's easy to implement and adaptable to changes without retraining. Requires more storage as deleting the "training" data would lead to inaccuracy.
Model Based Learning
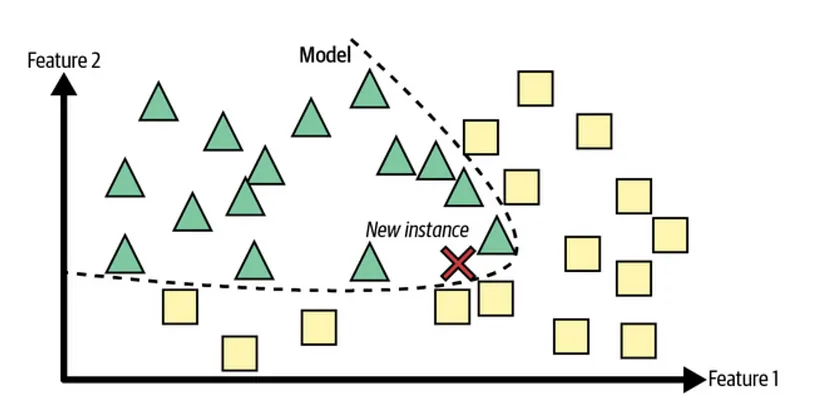
Model-based learning, on the other hand, involves creating a model from the training data using mathematical functions. This model extracts the underlying principles and relationships. Once trained, the model can make predictions without needing the original training data, as it uses the learned decision boundaries or functions.
Linear and Logistic Regression: These models create a linear decision boundary to classify or predict outcomes based on input features.
Decision Trees: These models use a tree-like structure to make decisions based on feature values, creating clear decision paths.
Neural Networks: These complex models use layers of interconnected nodes to learn non-linear relationships in data.
Once trained, the model requires less storage and makes predictions quickly, training data can also be deleted if the model is good enough. It's parameter tuning may be computationally expensive and may be prone to overfitting.
Real-World Applications
Instance-based learning algorithms are useful in recommendation systems, such as those used by streaming services like Netflix. When a user rates a few movies, the system can quickly find similar users and recommend movies based on their preferences without needing to retrain the entire model.
Model-based learning is widely used in various industries. In finance linear regression models predict stock prices based on historical data. In healthcare, neural networks help in diagnosing diseases from medical images. Decision trees are often employed in credit scoring to assess the risk of loan applicants.
Conclusion
Both instance-based and model-based learning have their unique strengths and weaknesses. Instance-based methods excel in flexibility and ease of use but at the cost of storage and prediction efficiency. Model-based methods, while more complex to train, offer faster predictions and lower storage requirements once the model is finalized. The choice between these approaches depends on the specific requirements of the task, such as the size of the dataset, the need for real-time predictions, and the computational resources available.
By understanding these two paradigms, engineer can better choose and design machine learning solutions tailored to their specific needs. Additionally, hybrid approaches can be employed to leverage the strengths of both methods, creating more robust and efficient models.
Subscribe to my newsletter
Read articles from Kshitij Shresth directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kshitij Shresth
Kshitij Shresth
hi.