Case for Modular Monolith
 Artur Stępniak
Artur Stępniak
Modular monoliths have fortunately become more popular recently, with many renowned architects and engineers recommending them as the default application architecture. Notably, Sam Newman, a microservices guru, advocates for their use, prompting reconsideration before starting a new project with a distributed architecture.
This article explores when to use a modular monolith and key considerations for designing one. It also serves as a "teaser" for a project I've been working on for a few months - a modular monolith template/starter written in Python.
When modular monolith is valid
Choosing the right architecture can be challenging, especially when one option becomes the season's buzzword, and the internet claims it's the only valid choice. A modular monolith isn't a silver bullet either. Let's examine its benefits, when it suits a project, and when other architectures should be considered.
Benefits of modular monolith
Clear and fast features implementation
The main characteristic of a modular monolith, as the name suggests, is its independent modules (I'll also call them "components" in this post). A key benefit of their autonomy is the speed of introducing new features. There are no complicated, confusing dependencies between different components, making it easier to understand what needs to be done and implement changes quickly.
Plays nicely with Domain Driven Design
Monolith modules correspond to DDD's modules and/or bounded contexts. This means that DDD offers guidance on what modules a given project should have. Both approaches are commonly used in medium to large-sized projects. Coincidence? I don't think so.
Why is this important? Designing system components such as modules, bounded contexts, or aggregates is always challenging. Teams using the DDD approach often employ techniques like Event Storming or User Story Mapping. The outcomes of these techniques help determine how to split the system into modules.
Architecture prepared for migration to microservices
Since the modules of a monolith create transactional and semantic code boundaries, they are natural candidates to become separate services. By having modules communicate with one another via clearly defined interfaces and committing changes within a single module, the monolith operates similarly to microservices. Implementing a monolith in this way ensures that some of the necessary mechanisms for a microservices architecture are already in place.
Why not simply go with microservices?
I've become a big fan of "dull solutions" because they are generally more reliable, easier to maintain, and faster to implement - qualities that businesses typically expect. A modular monolith is one such "dull solution" that, when implemented correctly, also ensures the system can be easily upgraded with new features.
Ease of introducing changes
Modular monolith is best suited for new or refactored projects with a non-trivial domain.
When starting a new project, you know the least about the domain and business context, so it's rarely wise to implement the system with architectures that make changing component boundaries difficult. In distributed systems, synchronizing changes between multiple services is necessary to maintain proper system functionality. In a modular monolith, you can change boundaries in a single commit.
Distributed systems also introduce added complexity in areas such as observability, security, and communication between components. Configuring these tools and debugging related issues can be time-consuming and hard to justify to the business, whereas these challenges are minimal in a monolith architecture.
Non-scalability myth
Microservices, lambdas, and other distributed system architectures have become almost synonymous with "scalable architectures," leading some to believe that monoliths cannot be used for performant, replicated services. This is, of course, not true. You can scale a monolith because it is a service like any other. You can even configure some replicas to handle specific high-traffic requests and create more replicas of those "services."
But it doesn't fit everywhere
Of course, a monolith is not a silver bullet. At some point, other architectures may be more suitable. I would opt for microservices when:
There are so many changes implemented in parallel that testing them takes a lot of time and delays releases. This likely indicates significant organizational growth since the modular monolith was introduced, making it easier, cheaper, and better to change the architecture rather than continuously addressing bottlenecks in the release process.
Some parts of the monolith have very different non-functional requirements, such as scalability, security, or other "-ities." In such cases, it may be better to extract those modules as separate services and use appropriate tools, designs, and infrastructure to meet the specific requirements.
Characteristics of modular monolith
Module responsibility
In the Clean Code approach, every class and function has a clearly defined responsibility. The same applies to modules, though deciding on their boundaries is not an easy task. Do it wrong, and you'll end up with coupled code, making it difficult to implement new functionalities or fixes without changing multiple modules. Do it right, and you'll benefit from fast changes, easier testing, and maintainable code.
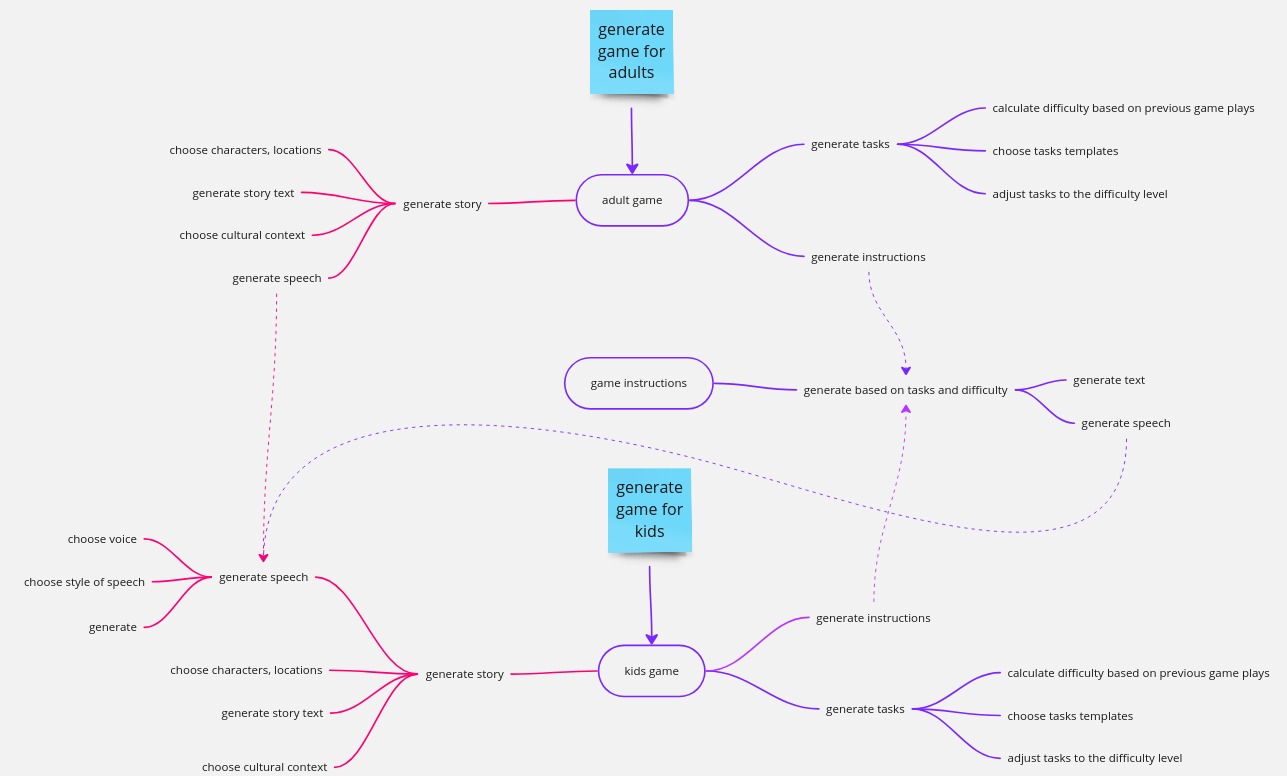
What is right and what's not? Let's check with an example of a system that creates simple games for kids and adults. Each game consists of tasks to accomplish, a background story, and instructions. The story and instructions have both text and speech forms.
Initially, the team implemented this with the following modules: adult game, game instructions, and kids game. While some dependencies between the modules are inevitable, the most problematic one is the "generate speech" function defined in the "kids game" module but used by all modules. This can make the function hard to maintain.
After refactoring, this might look like the following:
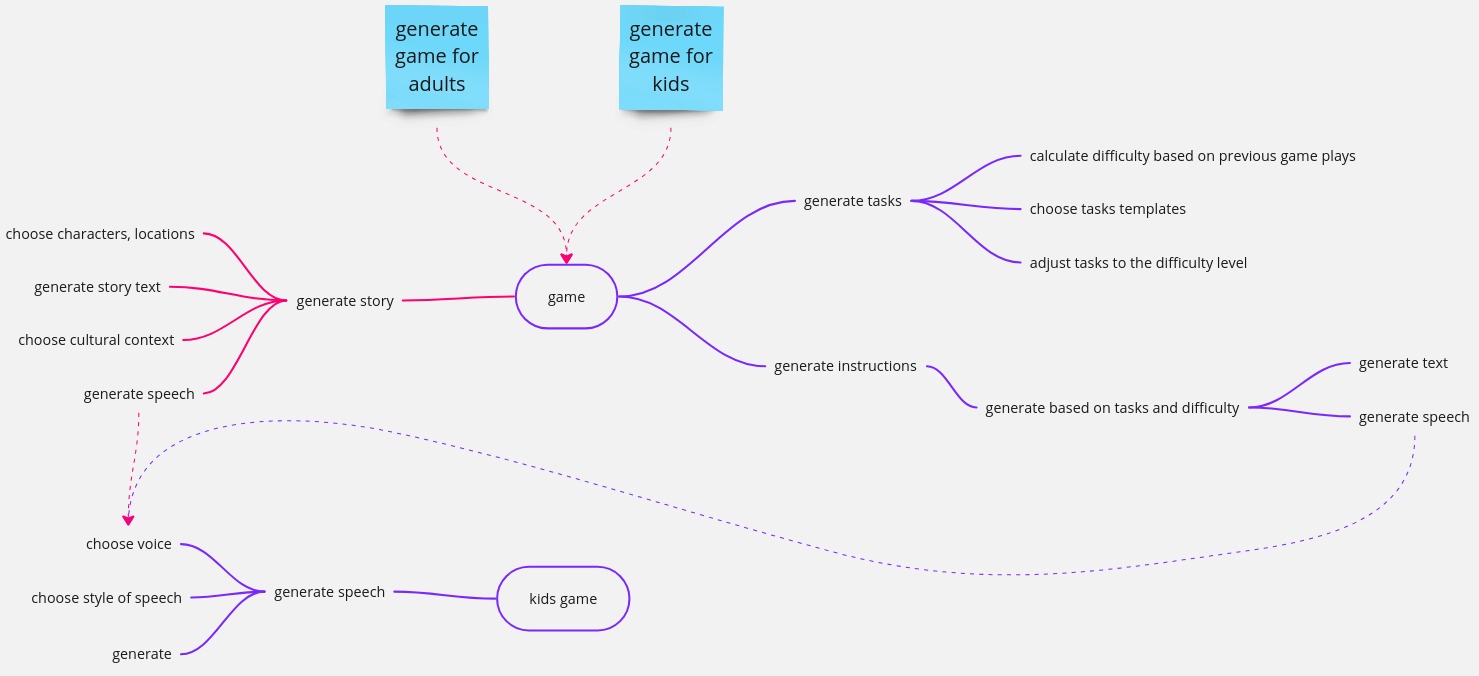
In the case of very simple games, it may be possible to implement the game module's logic with generic code that is parameterized by the player's type. This approach eliminates the need for a separate game instructions module. However, it's still beneficial to separate the text-to-speech functionality into its own module to facilitate easy use by other modules. This way, the speech generation logic remains encapsulated and reusable across different parts of the system.
Module interface
No matter how hard you try, communication between modules becomes inevitable when implementing a system that involves more than CRUD operations. In the example of the Games System, the game module utilizes text-to-speech functionality.
It's crucial for downstream modules to expose interfaces that hide their internal implementation details, allowing upstream modules to only use those endpoints. This decoupling ensures that a calling component does not need adjustment when changes are introduced in a called component.
The choice of interfaces depends on your approach. These may include services, controllers, commands, events, etc. The key is to commit to using only these interfaces for communication between modules, promoting modularization and maintainability.
Transactional boundary
Deciding whether a module should define its transactional boundary requires careful analysis, as it can introduce complexities into your system. If each module commits only the data it manages, then the system:
Is more error-prone, as upstream modules still commit their changes even if downstream processing is buggy.
Has better performance, as downstream request handling may occur in the background.
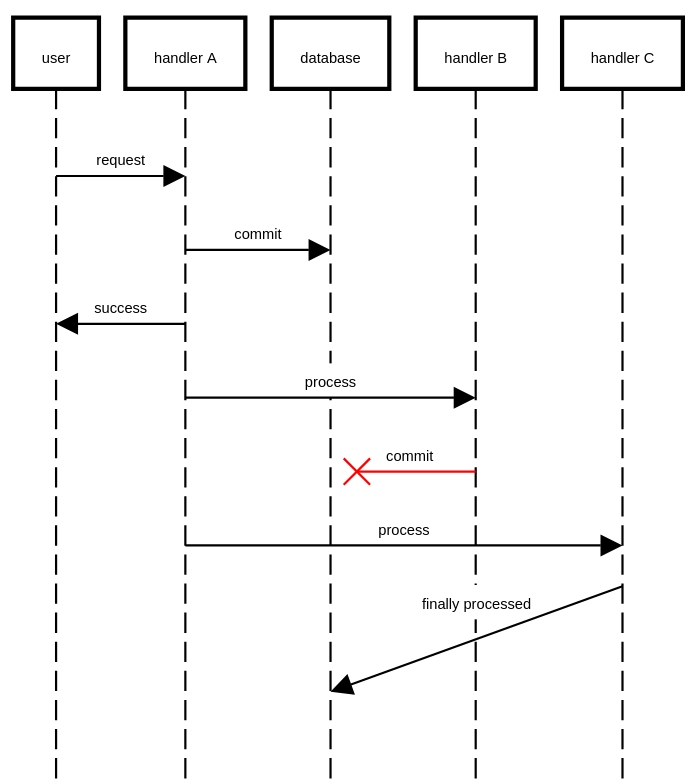
- Combines the above two characteristics: fewer entities are committed in a single transaction, increasing the probability of conflict-free transactions and eliminating the need for retries or other handling mechanisms to process the request.
To benefit from the mentioned traits, you need to make communication between modules more intricate:
Ensuring System Consistency: Addressing system consistency in case of downstream errors is crucial. While upstream processing may succeed even if downstream modules fail, it leaves the system in an inconsistent state that needs handling. Implementing a proper mechanism is essential. This could involve retrying processing, fixing bugs, or finding alternative solutions.
Handling "Only Once Processing": Dealing with the issue of "only once processing" is vital. Suppose a request is processed by a handler that triggers multiple downstream processors, some of which succeed while others fail. To address this:
Ensure all handlers are idempotent to safely retry downstream operations. While it's often feasible to make a processor idempotent, assuming all can be safely retried poses risks.
Retry only the handlers that failed. This is a non-trivial problem but can be addressed using patterns such as the inbox and outbox patterns. These patterns help manage the state and retry logic for failed operations, ensuring that only the necessary handlers are retried.
As you can see, module-bounded transactions can provide profound benefits but at the cost of more complex system. I'd say it's important to discuss the value of the advantages with business people to decide if it's worth complicating the design and maintenance.
It's essential to remember that the decision to separate transactions isn't all-or-nothing. You can isolate transactions in product-critical modules while sharing them in other components. However, transitioning from a shared transaction to separate ones can be challenging, especially if your code lacks clearly defined interfaces.
In the upcoming posts, I'll detail how I tackled various challenges in my hobby modular monolith project. Stay tuned, and feel free to post any comments or questions until then!
Subscribe to my newsletter
Read articles from Artur Stępniak directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Artur Stępniak
Artur Stępniak
My name is Artur Stępniak. I focus on achieving business goals with help of my technical expertise. I started my professional software development journey in 2010 with C++ embedded system development and after a few years transitioned to Python. I’ve been different kinds of lead since 2012.