Quick Introduction to Apache Kafka
 Sandeep Choudhary
Sandeep Choudhary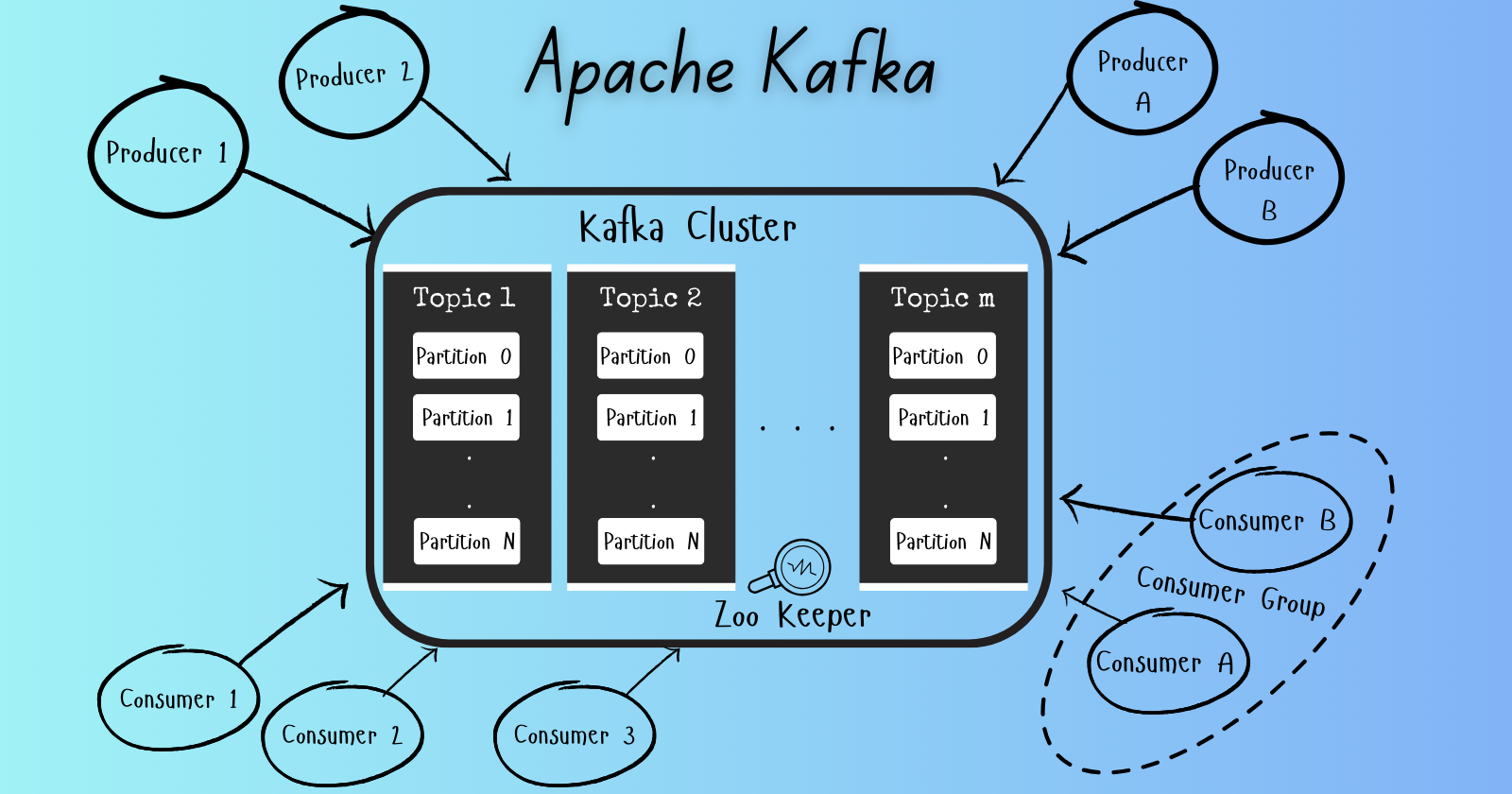
Let’s dive into the fascinating world of Apache Kafka, a distributed event streaming platform that has revolutionised data pipelines, real-time analytics, and mission-critical applications.
What is Apache Kafka?
Apache Kafka is an open-source, distributed event streaming platform designed to handle high-throughput, real-time data streams. It was originally developed at LinkedIn to handle mass amounts of data and is now used by over 80% of the Fortune 100. It enables seamless communication between various components of a system, making it a powerful tool for building event-driven applications. Here are some key points about Kafka:
Publish-Subscribe Model
Kafka follows the publish-subscribe model, where producers publish messages to topics, and consumers subscribe to those topics to receive the messages.
Topics act as channels through which data flows.
Core Capabilities
High Throughput: Kafka can deliver messages at network-limited throughput with low latencies (as low as 2ms).
Scalability: Production clusters can scale up to thousands of brokers, handle trillions of messages per day, and manage petabytes of data across hundreds of thousands of partitions.
Permanent Storage: Kafka stores streams of data safely in a distributed, fault-tolerant cluster.
High Availability: Clusters can stretch efficiently over availability zones or connect separate clusters across geographic regions.
Ecosystem
Built-in Stream Processing: Kafka supports stream processing with features like joins, aggregations, filters, and transformations using event-time and exactly-once processing.
Connectors: Kafka’s Connect interface integrates with hundreds of event sources and sinks, including databases (e.g., Postgres), messaging systems (e.g., JMS), cloud storage (e.g., AWS S3), and more.
Client Libraries: Developers can read, write, and process Kafka streams in various programming languages.
Large Open Source Ecosystem: Leverage a wide array of community-driven tools and libraries.
Trust and Ease of Use
Kafka ensures guaranteed ordering, zero message loss, and efficient exactly-once processing for mission-critical use cases.
Thousands of organisations, from internet giants to car manufacturers to stock exchanges, trust Kafka for their data streaming needs.
The vast user community actively contributes to its development and provides rich online resources.
Key services provided by Apache Kafka
Persistent storage for storing massive volumes of events in a fault-tolerant and durable way for as long as you want. This ensures that data is not lost and can be retrieved when needed.
A message bus capable of throughput reaching millions of messages every second.
Redundant storage of massive data volumes for durability and fault tolerance.
Parallel processing of huge amounts of streaming data.
Key APIs provided by Apache Kafka
Producer API enables developers to create their own producers that write data to Kafka topics. It is a Kafka client that publishes records to the Kafka cluster. The producer is thread-safe and sharing a single producer instance across threads will generally be faster than having multiple instances
Consumer API of Apache Kafka is a client application that subscribes to (reads and processes) events. It enables developers to create their own consumers to read data from Kafka topics. The consumer maintains TCP connections to the necessary brokers to fetch data.
Streams API is a powerful, lightweight library provided by Apache Kafka for building real-time, scalable, and fault-tolerant stream processing applications. It allows developers to process and analyse data stored in Kafka topics using simple, high-level operations such as filtering, transforming, and aggregating data
Connector API is offered as part of Kafka that allows for the building and running of reusable data import/export connectors. These connectors can consume (read) or produce (write) streams of events from and to external systems and applications that integrate with Kafka. Connectors can be used to import data from external systems into Kafka topics and export data from Kafka topics into external systems.
Use Cases for Kafka
Real-Time Analytics
Kafka ingests data from various sources (logs, sensors, databases) and enables real-time analysis for business insights.
Companies use Kafka to monitor website traffic, analyse user behaviour, and detect anomalies.
Log Aggregation
Kafka centralises logs from different services, making debugging and troubleshooting easier.
Developers can query logs efficiently and retain historical data.
Event Sourcing
Kafka stores all changes to an application’s state as a stream of events.
This approach allows reconstructing the application’s state at any point in time.
Microservices Communication
Kafka acts as a communication backbone for microservices.
Services can publish events (e.g., user registration) and other services can consume them.
Internet of Things (IoT)
Kafka handles massive amounts of sensor data generated by IoT devices.
It ensures reliable data ingestion and real-time processing.
In summary, Apache Kafka empowers developers to build robust, scalable, and real-time applications. Whether you’re handling financial transactions, monitoring social media trends, or analysing sensor data, Kafka is a powerful ally in the world of data streaming.
Subscribe to my newsletter
Read articles from Sandeep Choudhary directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by