The Kubernetes Resume Challenge: Extra credit
 David WOGLO
David WOGLO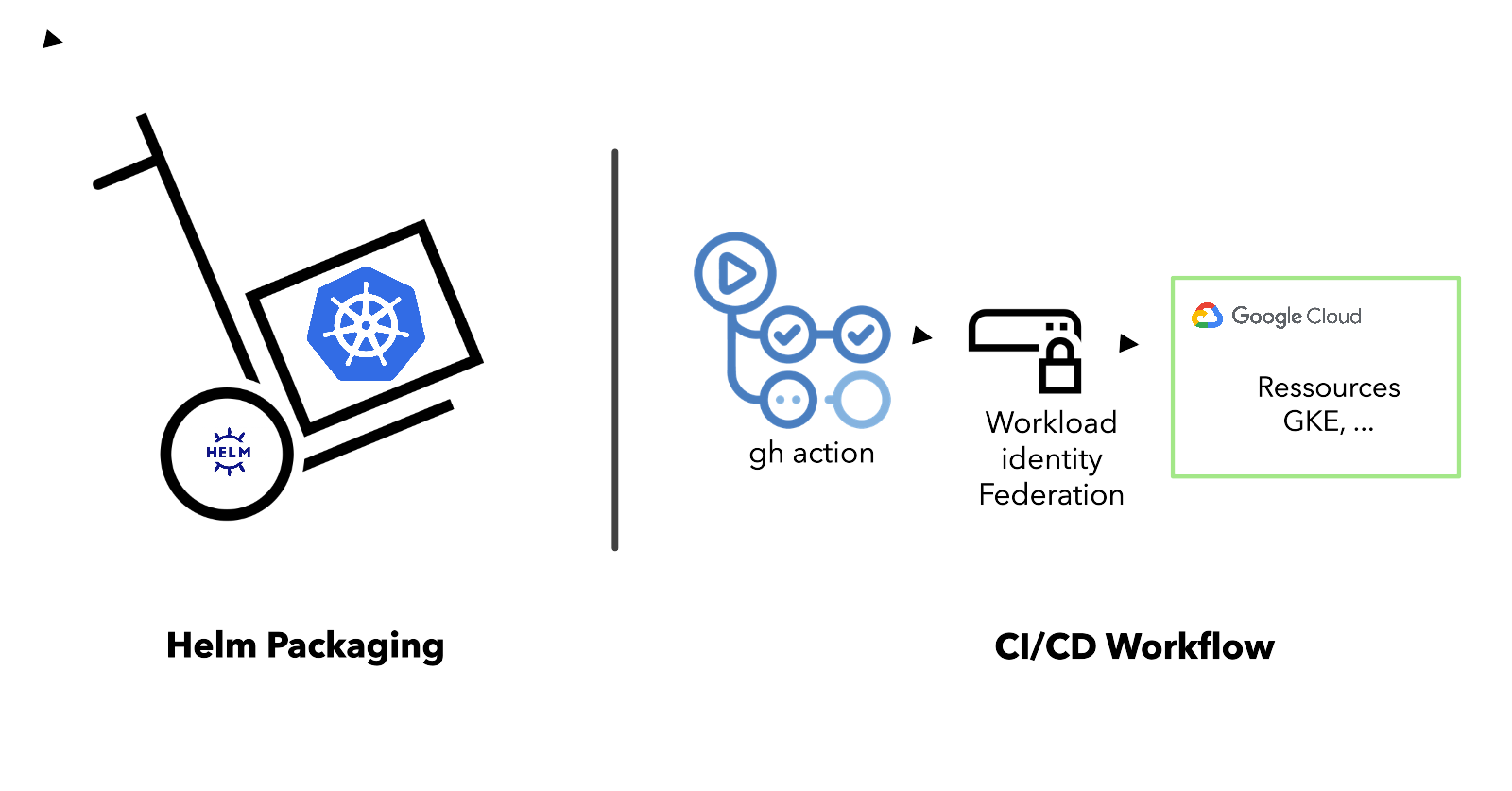
Well, it's been a while since the first part of this article before I'm releasing this last part today. Simply because I've been a bit busy lately, but also because I knew nothing about Helm , all I knew about Helm was that it is is used to package Kubernetes applications, that's all. So this break time, apart from the different things I had to do, I took it to learn Helm in fact, the concept behind it, how to use it, etc.
As you already know, to stay true to the spirit of the challenge and to keep it challenging, this article will not be a detailed step-by-step implementation guide, but rather a post about steps, decisions made, and how challenges were overcome. You can still refer to the documentation on github for something more or less technical, but it is still highly recommended to do everything from scratch to learn properly.
So, the remaining steps were the extra credit: Package Everything in Helm, Implement Persistent Storage, and Implement CI/CD Pipeline. Let's see how I tackled them.
Package Everything in Helm
As I mentioned earlier, at this stage my challenge was clear: I HAD TO LEARN HELM, not just what was needed for the challenge but also to go a bit into the details, in order to get a global and deep understanding of the thing in order to know how to effectively guide my choices in the implementation.
My Helm directory is therefore presented as follows:
Basicly at the root we have the files:
values.yamlis a file in a Helm chart directory that allows you to set the values of configurable parameters in your Helm chart. It's a way to provide default configuration values for a chart. These values can be overridden by users during the installation of the chart or when upgrading a release.chart.yamlis a mandatory file in a Helm chart directory. It contains basic information about the chart.And the
'templates'directory contains files that will generate Kubernetes manifest files when the chart is installed. It contains the actual Kubernetes manifests with placeholders that will be populated by the values set in the values.yaml file, if these values are not overwritten during installation or upgrade.
You can visit the official Helm documentation to go into depth, or quickly understand the concepts with this TWN tutorial.
Implement Persistent Storage
The goal here is to persist the data stored in the database and the changes made, so that if the deployments are deleted or redeployed, the data is still available.
To achieve this, I needed to create a Kubernetes PersistentVolumeClaim resource and associate it with the database deployment to mount the database's data storage location (/var/lib/mysql). This is where the database data and the data loaded by the initialization script are stored.
While this can be done without much hassle in an interactive or manual way (e.g., using kubectl apply), the challenge arises when installing with Helm. For the data to be loaded onto this persistent volume, the PVC must be deployed first. Otherwise, there will be errors and the pods will be stuck and won't reach the Ready state. To address this, I utilized a Helm feature called Helm hooks.
Helm hooks are a mechanism to intervene at certain points in a release's lifecycle. They allow you to provide Helm with instructions to perform specific operations based on Helm's lifecycle events, such as install, upgrade, delete, etc. I leveraged this in my case to specify that this PersistentVolumeClaim should be created before the Helm chart is installed or upgraded.
...
metadata:
name: mariadb-pvc
annotations:
"helm.sh/hook": pre-install,pre-upgrade
"helm.sh/hook-weight": "0"
...
"helm.sh/hook": pre-install,pre-upgrademeans that this resource will be managed separately from the rest of the chart's resources. It will be created before the rest of the chart's resources during an install or upgrade."helm.sh/hook-weight": "0"is used to control the execution order of hooks. Hooks with lower weights will be executed before hooks with higher weights. In this case, the PersistentVolumeClaim will be one of the first resources created, as it has a weight of 0.
Implement CI/CD Pipeline
Let's talk about the most fun part, shall we? The roller coaster of CI/CD, haha! Those endless failed jobs before finally seeing a glimmer of hope in the form of a green status, which was only achieved by painstakingly commenting out parts of the workflow file to troubleshoot each step individually. And then, as soon as one step is fixed, the red errors start popping up again, and the cycle repeats until all the steps are fixed and we have a functional pipeline. (It's quite exhilarating, really.)
Enough of that. When setting up this pipeline with GitHub Actions, I wanted to adopt a new Google Cloud security feature to authenticate my workflow when it accesses GCP resources. Previously, we used service account keys, which, if compromised, could put our GCP resources at risk. This is because with service account keys, there's no way to verify who or what is using the keys. So, anyone can access the resources if they get their hands on the keys.

To address this, Google Cloud has introduced Workload Identity Federation, a more secure way to grant access to GCP resources from outside GCP. Workload Identity Federation allows you to authenticate the entity that will use the service account to access the resources. And in this case, the tokens generated are not long-lived but rather short-lived, just for the duration of the operation. So, even if the token is leaked, it will not be valid for accessing GCP resources.
For setting up Workload Identity Federation, refer to this.
Project's Github repository
Subscribe to my newsletter
Read articles from David WOGLO directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
David WOGLO
David WOGLO
I am a cloud and DevOps engineer with a passion for learning . I have hands on in designing, deploying, and managing cloud-based applications and infrastructure, and I am proficient in automating and streamlining DevOps processes using CI/CD pipelines.. My skills extends to multi-cloud environments, leveraging my architectural skills to seamlessly integrate various cloud platforms. If you are interested in working with me or learning more about me, please feel free to contact me via email or LinkedIn.