Software Engineering Principles Cheatsheet - Part I
 Tuan Tran Van
Tuan Tran Van
Introduction
Software design principles are the foundation of software development. As a software engineer, you can find them in your work tools, languages, frameworks, paradigms, and patterns. They are the core pillars of "good" and "readable" code. Once you understand them, you can see them everywhere.
The skill of seeing and applying them is what distinguishes a good engineer from a bad one. No one framework or tool can help you improve the quality of writing good code without understanding the fundamentals. Moreover, without them, you become a hostage of that tool.
This article isn't the reference guide but rather my try to systemize a list of core principles that need to be refreshed time to time.
Benefits of applying software engineering principles
Embracing software engineering principles offers a multitude of benefits for development teams and organizations.
Enhanced software quality: By adhering to best practices and proven methodologies, teams can deliver software that is reliable, efficient and meets the highest quality standards.
Increased Productivity: Streamlined processes, code reuse, and modular design enable teams to work smarter, not harder, resulting in faster development cycles and a short time to market.
Improved Collaboration: Shared principles and clear guidelines foster effective communication and collaboration among team members, leading to better coordination and faster problem-solving.
Reduced technical debt: Well-structured and maintainable code minimizes technical debt, making it easier to accommodate changes and scale the software over time.
Enhance Agility: Modular and loosely coupled architectures enable teams to respond quickly to changing requirements and adapt the software to evolving business needs.
Cost savings: By catching and fixing issues early, minimizing rework, and improving overall efficiency, organizations can significantly reduce development and maintenance costs.
Applying software engineering principles ultimately empowers the team to build software that delivers lasting value and drives business success.
The list of software engineering principles
You should follow certain principles and tactics to ensure your technical decisions are based on requirements, budgets, timelines, and expectations.
By adhering to these principles, you can stay grounded and facilitate the seamless progress of our project.
Take a look at these software engineering principles to guide you.
SOLID Principles
The SOLID principles are a set of guidelines for writing high-quality, scalable, and maintainable software.
They were introduced by Robert C. Martin in his 2000 paper “Design Principles and Design Patterns” to help developers write software that is easy to understand, modify, and extend.
These concepts were later built upon by Michael Feathers, who introduced us to the SOLID acronym.
The SOLID acronym stands for:
Single Responsibility Principle (SRP)
Open-Closed Principle (OCP)
Liskov Substitution Principle (LSP)
Interface Segregation Principle (ISP)
Dependency Inversion Principle (DIP)
These principles provide a way for developers to organize their code and create software that is flexible, easy to change, and testable. Applying SOLID principles can lead to code that is more modular, maintainable, and extensible, it can make it easier for developers to work collaboratively on a codebase.
A lot of people, when I ask about SOLID, always remember the first principle(Single Responsibility Principle). But when I ask about another, some people don't remember or find it difficult to explain. AND I UNDERSTAND.
Really, it's difficult to explain, without coding or reminding of the definition of each principle. But in this article, I want to present each principle in an easy way.
Let's begin.
1. S = Single Responsibility Principle (SRP)
"A moudule should be responsible to one, and only one, and actor" -- Wikipedia
Single Responsibility Principle (SRP) is one of the five SOLID principles, which states that each class should have only one responsibility, in order to preserve the meaningful separation of concerns.
This pattern is a solution to a common anti-pattern called "The GOD object" which simply refers to a class or object that holds too many responsibilities, making it easy to understand, test, and maintain.
Following the SRP rule helps make code components reusable, loosely coupled, and easily comprehensible. Let's explore this principle, showcasing an SRP violation and resolution.
Violation
In the following code, The ProductManager class is responsible for both the creation and storage of products, violating the single-responsibility principle.
class ProductManager {
private _products: Product[] = [];
createProduct (name: string, color: Color, size: Size): Product {
return new Product(name, color, size);
}
storeProduct (product: Product): void {
this._products.push(product);
}
getProducts (): Product[] {
return this._products;
}
}
const productManager: ProductManager = new ProductManager();
const product: Product = productManager.createProduct('Product 1', Color.BLUE, Size.LARGE);
productManager.storeProduct(product);
const allProducts: Product[] = productManager.getProducts();
Resolution
Separating the handling of product creation and storage into two distinct classes reduces the number of responsibilities of ProductManager class. This approach further modularizes the code and makes it more maintainable.
class ProductManager {
createProduct (name: string, color: Color, size: Size): Product {
return new Product(name, color, size);
}
}
class ProductStorage {
private _products: Product[] = [];
storeProduct (product: Product): void {
this._products.push(product);
}
getProducts (): Product[] {
return this._products;
}
}
//Usage
const productManager: ProductManager = new ProductManager();
const productStorage: ProductStorage = new ProductStorage();
const product: Product = productManager.createProduct("Product 1", Color.BLUE, Size.LARGE);
productStorage.storeProduct(product);
const allProducts: Product[] = productStorage.getProducts();
Another example of violating the Single Responsibility Principle (SRP) in React
Let’s first see what things look like when we violate the SRP in React and write so good enough component.
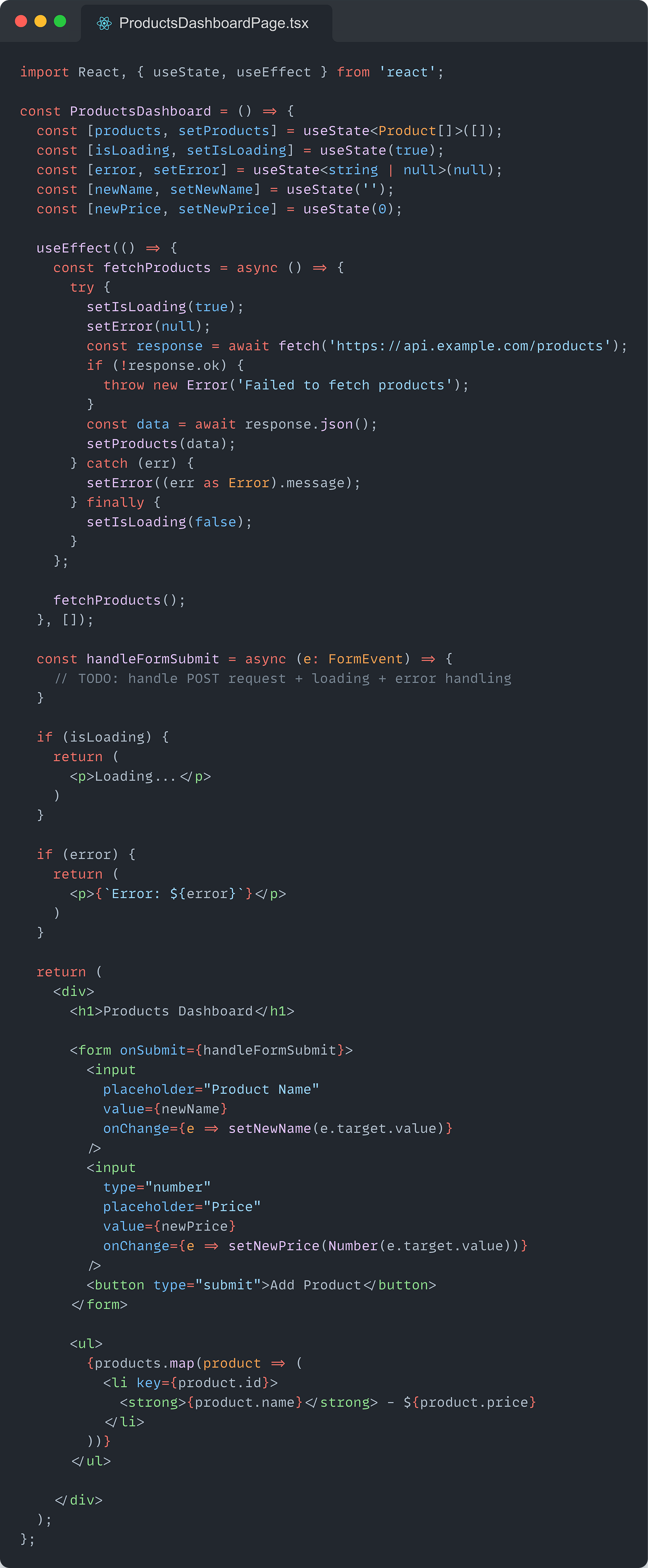
The problem with this component is that it:
Handle data fetching for the products
Manages the loading and error states
Handle the form for adding a new product
Takes care of the display and layout of the products
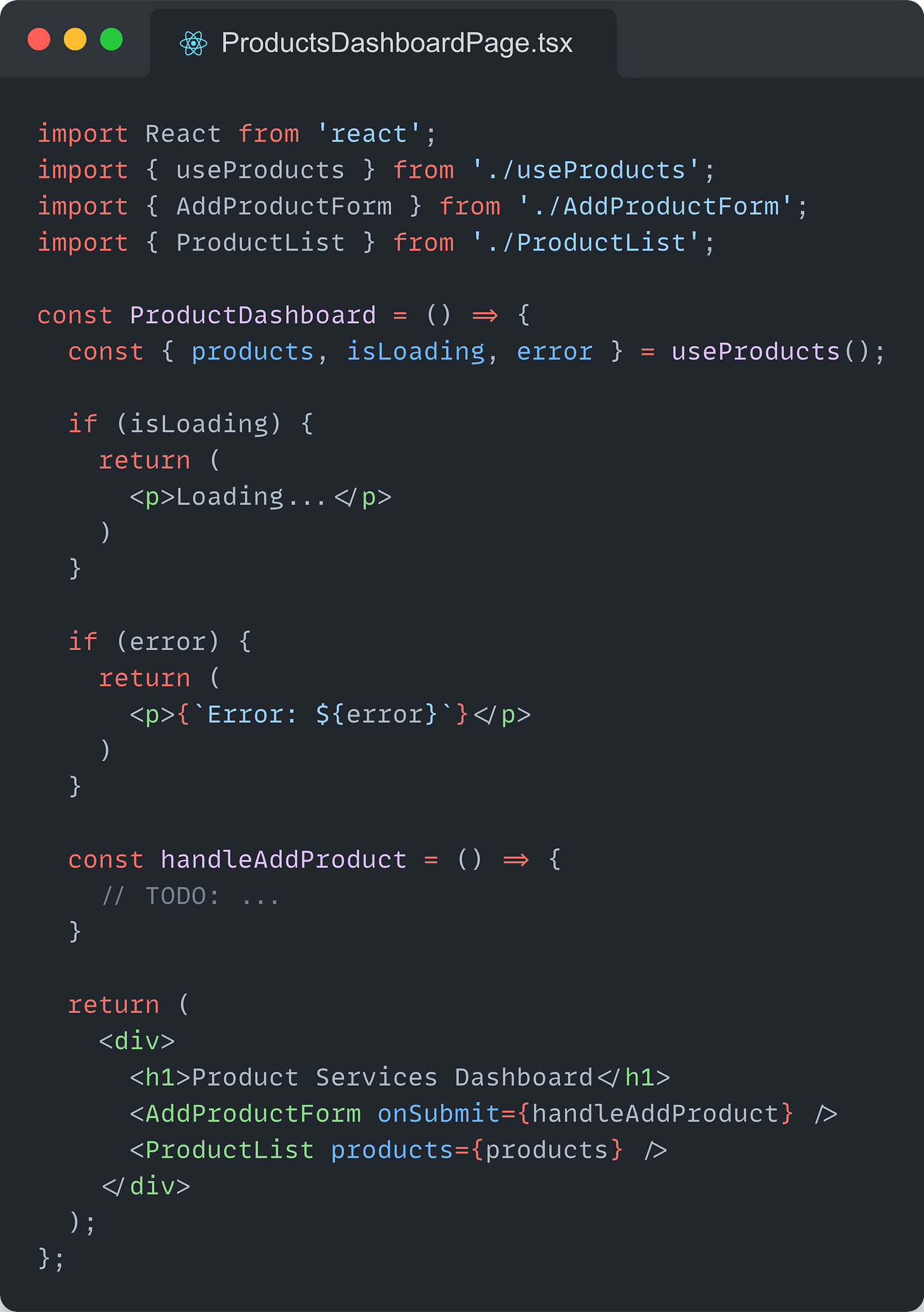
The ProductsDashboard Component has four reasons to change, which make it harder to understand, maintain, debug, test, and reuse.
Write better components by separating concerns
A better alternative is to split all these responsibilities and reasons the component to change into separate, focused components.
Use a custom hook for data fetching, loading, and error handling
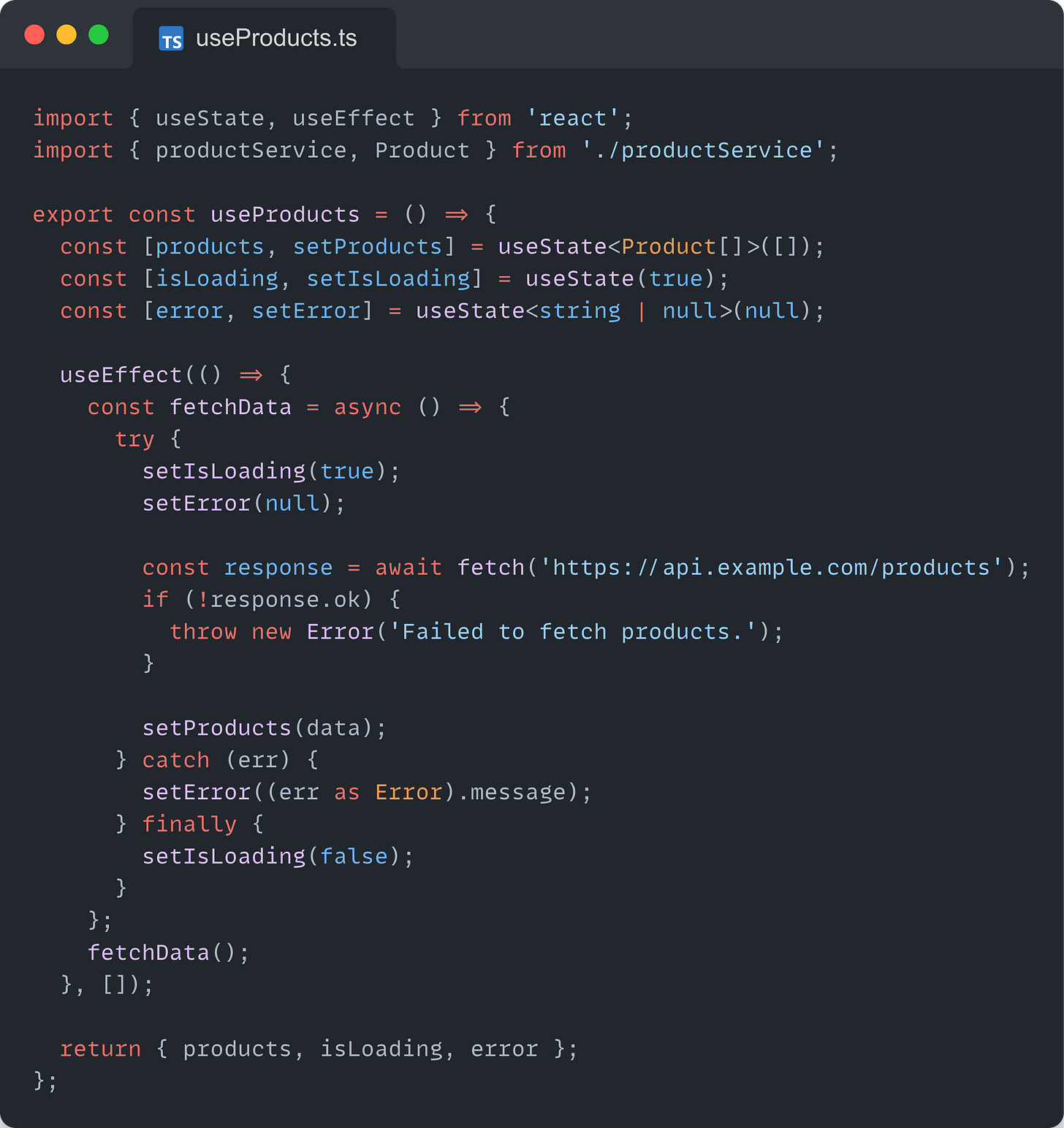
Use a separate component for the form
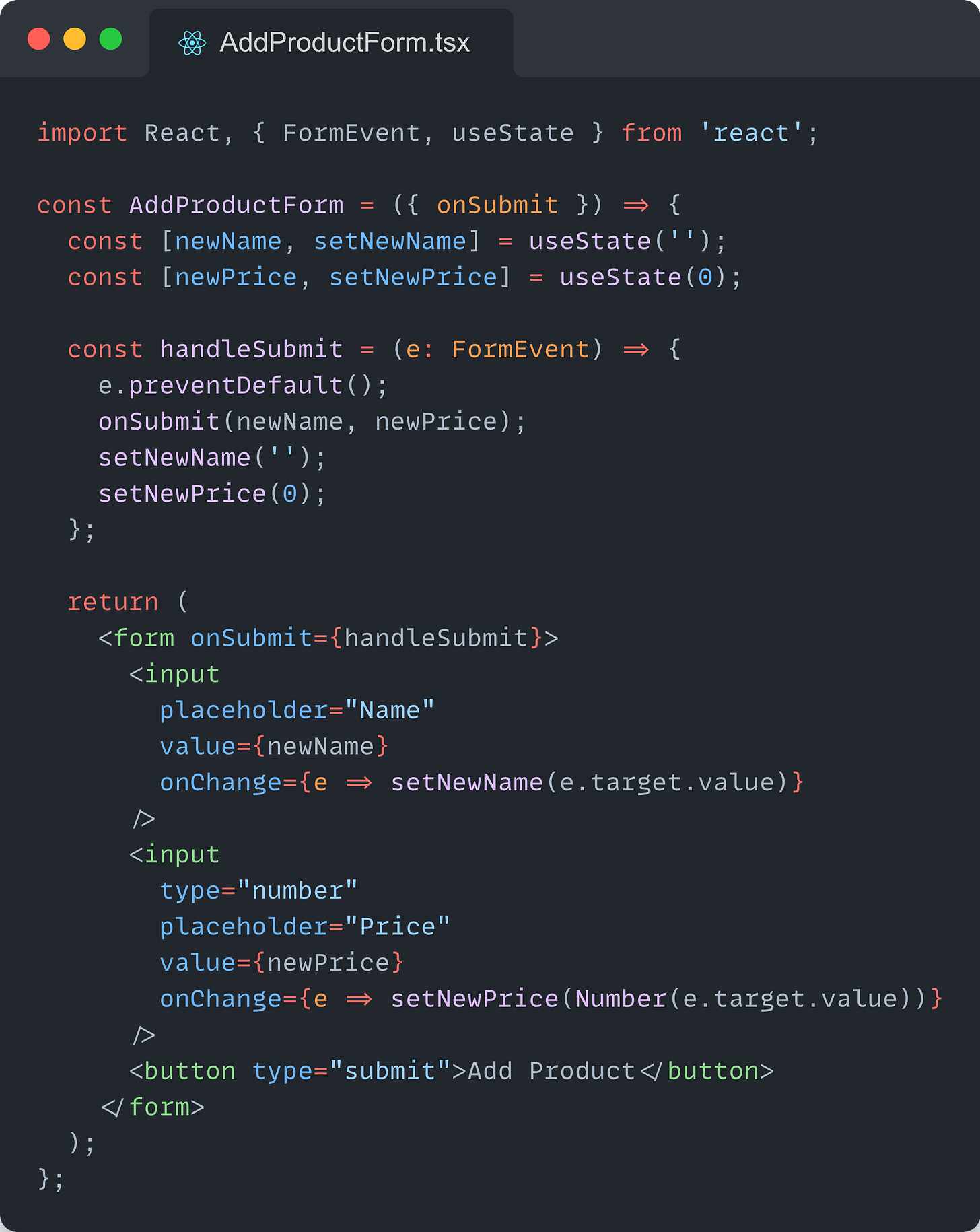
Use a separate component for displaying the products
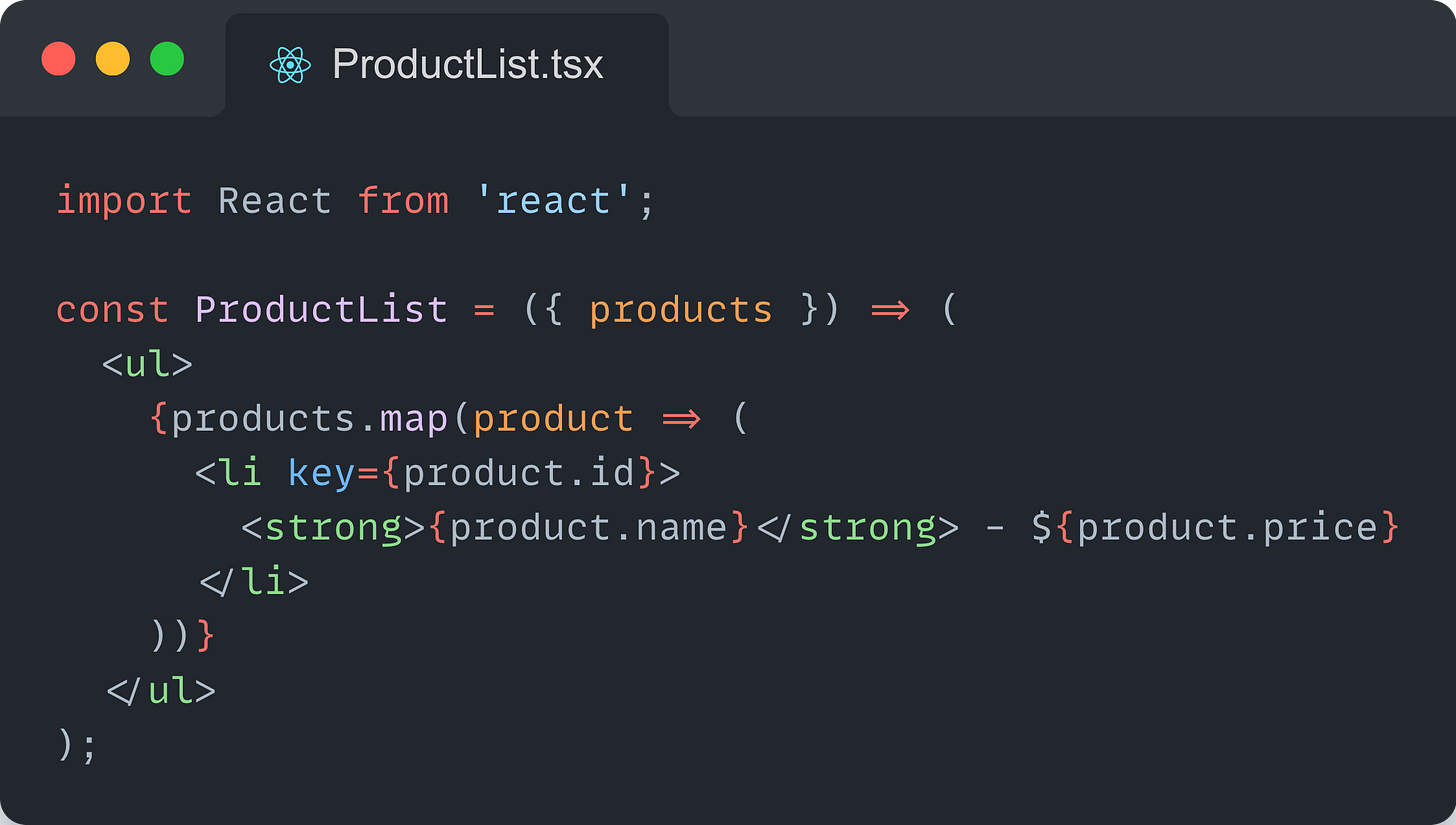
Use a separate component to handle the ProductDashboard’s logic
Key Points
Separate data handling from the user interface
Use custom hooks for data fetching and/or business logic
Write small and focused components, doing only one thing, and do it well
Prefer composing a set of smaller components, instead of writing big ones.
Organize your components in terms of layers: hooks, guard clauses, main render, smaller components, etc.
2. O = Open-Closed Principle (OCP)
"Software entities (classes, modules, functions, etc.) should be open for extension, but closed for modifications." -- Wikipedia
The Open-Closed Principle (OCP) is all about "write it once, write it well enough to be extensible, and forget about it."
The importance of this principle lies in the fact that a module may change from time to time based on new requirements. In case the module arrives after the module was written, tested, and uploaded to production, modifying this module is usually bad practice, especially when other modules depend on it. In order to prevent this situation, we can use the open-closed principle.
Let's imagine the following example of an Exam class:
type ExamType = {
type: "BLOOD" | "XRay";
};
class ExamApprove {
constructor() {}
approveRequestExam(exam: ExamType): void {
if (exam.type === "BLOOD") {
if (this.verifyConditionsBlood(exam)) {
console.log("Blood Exam Approved");
}
} else if (exam.type === "XRay") {
if (this.verifyConditionsXRay(exam)) {
console.log("XRay Exam Approved!");
}
}
}
verifyConditionsBlood(exam: ExamType): boolean {
return true;
}
verifyConditionsXRay(exam: ExamType): boolean {
return false;
}
}
Yeah, probably you have already seen this code several times. First, we are breaking the first principle, SRP, and making a lot of conditions.
Now imagine if another type of examination appears, for example, an ultrasound. We need to add another method to verify and another condition.
Modifying an existing class to add a new behavior carries a serious risk of introducing bugs into something that was already working.
See that beauty that comes with refactoring the code:
type ExamType = {
type: "BLOOD" | "XRay";
};
interface ExamApprove {
approveRequestExam(exam: NewExamType): void;
verifyConditionExam(exam: NewExamType): boolean;
}
class BloodExamApprove implements ExamApprove {
approveRequestExam(exam: ExamApprove): void {
if (this.verifyConditionExam(exam)) {
console.log("Blood Exam Approved");
}
}
verifyConditionExam(exam: ExamApprove): boolean {
return true;
}
}
class RayXExamApprove implements ExamApprove {
approveRequestExam(exam: ExamApprove): void {
if (this.verifyConditionExam(exam)) {
console.log("RayX Exam Approved");
}
}
verifyConditionExam(exam: NewExamType): boolean {
return true;
}
}
Wow, much better! Now, if another type of examination appears, we just implement the interface ExamApprove . And if another type of verification for the exam comes up, we will only update the interface.
Let’s look at another example of violating the Open-Closed Principle (OCP) in React:
Let’s first look at what things look like when we violate the OCP in React and write so good enough component.
Consider adding variants to a Button.
const Button = ({ variant, ...restProps }) => {
let classes = "border border-transparent rounded-md";
if (variant === "primary") {
classes += " text-white bg-primary-500 ring-primary-300";
} else if (variant === "secondary") {
classes += " text-white bg-secondary-500 ring-secondary-300";
}
return <button className={classes} {...restProps} />;
};
The problem with this component is that:
Adding new variants requires changing the component’s internal logic.
The component needs to know internally about all possible variants.
Each new variant makes the component harder to read, test, and maintain.
Write better components by building Open/Extensible Components
A better alternative is to build open components that could be reused and extended when requirements change, instead of changing their internal implementation.
Here is the refactored example:
type VariantPrefix<T extends string, C extends string> = `${T}-${C}`;
type Colors =
| "primary"
| "secondary"
| "success"
| "danger"
| "warning"
| "info";
type ButtonVariants =
| Colors
| VariantPrefix<"outline", Colors>
| VariantPrefix<"link", Colors>;
const Button = ({ variant, ...restProps }) => {
const {
theme: { button: theme },
} = useTheme();
const classes = theme.variant[variant];
return <button className={classes} {...restProps} />;
};
Now:
Variant styles are managed externally, through a theme, removing the need of the <Button /> component to know internally about the possible variants.
New variants are added inside the theme configuration without modifying the <Button /> component.
The <Button /> component is simplified, which makes it easier to test, read, and maintain.
Theme is a configuration object. It looks something like:
const button: ButtonThemeProps = {
// ...
variant: {
primary: `
text-white bg-primary-500 ring-primary-300
`,
secondary: `
text-white bg-secondary-500 ring-secondary-300
`,
},
// ...
};
The theme configuration object is shared through the built-in React Context API and a custom hook.
3. L = Liskov Substitution Principle (LSP)
"Subtype objects should be substitutable for supertype objects" - Wikipedia
This principle, introduced by Barbara Liskov in 1987, can be a bit complicated to understand from her explanation. Still, no worries, I will provide another explanation and an example to help you understand.
If for each object o1 of type S there is an object o2 of type T such that, for all programs P defined in terms of T, the behavior of P is unchanged when o1 is substituted for o2, then S is a subtype of T.
Barbara Liskov, 1987
You got it, right? Nah, probably not. I didn't understand the first time I read it(nor the next hundred times), but hold on, there's another explanation.
if S is a subtype of T, the objects of type T in a program can be replaces by object of type S without altering the properties of this program.
In other words, a derived class should behave like its base class in all contexts. In simpler terms, if class A is a subtype of class B, you should be able to replace B with A without breaking the behavior of the program.
The importance of the LSP lies in its ability to ensure that the behaviour of the program remains consistent and predictable when substituting objects of different classes. Violating the LSP can lead to unexpected behavior, bugs, and maintainability issues.
Let's take an example:
Imagine you have a university and two types of students. Student and Postgraduate Student.
class Student {
constructor(public name: string) {}
study(): void {
console.log(`${this.name} is studying`);
}
deliverTCC() {
/** Problem: Post graduate Students don't delivery TCC */
}
}
class PostGraduatedStudent extends Student {
study(): void {
console.log(`${this.name} is studying and searching`);
}
}
You have a problem here, we are extending of Student, but the PostGraduatedStudent don't need to deliver a TCC. He only studies and searches.
How can we resolve this problem? Simple! Let's create a class Student and separate the students of graduation and post-graduation.
class Student {
constructor(public name: string) {}
study(): void {
console.log(`${this.name} is studying`);
}
}
class StudentGraduation extends Student {
study(): void {
console.log(`${this.name} is studying`);
}
deliverTCC() {}
}
class StudentPosGraduation extends Student {
study(): void {
console.log(`${this.name} is studying and searching`);
}
}
Now we have a better way to approach separating their respective responsibilities. The name of this principle can be scary but its principle is simple.
4. I = Interface Segregation Principle (ISP)
"No code should be force to depends on method it does not use" -- Wikipedia
The Interface Segregation Principle (ISP) focuses on designing interfaces that are specific to their clients' needs. It states that no client should be forced to depend on methods it does not use.
The principle suggests that instead of creating a large interface that covers all the possible methods, it's better to create smaller, more focused interfaces for specific use cases.
By applying this principle, software systems can be built much more flexible, easy-to-understand, and easy-to-refactor manner. Let's take a look at an example:
Let's imagine a scenario with a Seller and a Receptionist of a shop. Both the seller and the receptionist have a salary, but only the seller has a commission.
Let's see the problem:
interface Employee {
salary(): number;
generateCommission(): void;
}
class Seller implements Employee {
salary(): number {
return 1000;
}
generateCommission(): void {
console.log("Generating Commission");
}
}
class Receptionist implements Employee {
salary(): number {
return 1000;
}
generateCommission(): void {
/** Problem: Receptionist don't have commission */
}
}
Both implement the Employee interface, but the receptionist doesn't have a commission. So we are forced to implement a method that never it will never be used.
So the solution:
interface Employee {
salary(): number;
}
interface Commissionable {
generateCommission(): void;
}
class Seller implements Employee, Commissionable {
salary(): number {
return 1000;
}
generateCommission(): void {
console.log("Generating Commission");
}
}
class Receptionist implements Employee {
salary(): number {
return 1000;
}
}
Easy beasy! Now we have two interfaces! The employer class and the commissionable interface. Now, only the Seller will implement the two interfaces where it will have the commission. The receptionist doesn't only implement the employee. So the Receptionist shouldn't be forced to implement a method that will never be used.
5. D = Dependency Inversion Principle (DIP)
"One entity should be depend on abstractions, not concretions" -- Wikipedia
The Dependency Inversion Principle(DIP) is the final SOLID principle with a focus on reducing coupling between low-level modules (e.g., data reading/writing) with high-level modules(that perform the key operations) by using abstractions.
DIP is crucial for designing software that is resilient to change, modular, and easy to update.
DIP KEY Guidelines are:
High-level modules should not depend on low-level modules. Both should depend on abstractions. This means that the functionality of the application should not rely on specific implementations, in order to make the system more flexible and easy to update or replace low-level implementations.
Abstractions should not depend on details. Details should depend on abstractions. This encourages the design to focus on what operations are actually needed rather than on how those operations are implemented.
Violation
Let's take a look at an example that showcases a Dependency Inversion Principle (DIP) violation:
MessageProcessor (high-level module) is tightly coupled and directly dependent on the FileLogger (low-level) module, violating the principle because it does not depend on the abstraction layer, but rather on a concrete class implementation.
Bonus: There is also a violation of the Open-Closed Principle (OCP). If we would like to change the logging mechanism to write to a database instead of to a file, we would forced to directly modify the MessagesProcessor function.
import fs from 'fs';
// Low Level Module
class FileLogger {
logMessage(message: string): void {
fs.writeFileSync('somefile.txt', message);
}
}
// High Level Module
class MessageProcessor {
// DIP Violation: This high-level module is is tightly coupled with the low-level module (FileLogger), making the system less flexible and harder to maintain or extend.
private logger = new FileLogger();
processMessage(message: string): void {
this.logger.logMessage(message);
}
}
Resolution:
The following refactored code represents the change needed to be made in order to adhere to the Dependency Inversion Principle(DIP). In contrast to the previous example, when the high-level class MessageProcessor held the private property of the concrete low-level class FileLogger, it now instead holds private property of the type Logger - The interface that represents the abstraction layer.
The better approach reduces dependencies between classes, thus making code much more scalable and maintainable.
Declarations:
import fs from 'fs';
// Abstraction Layer
interface Logger {
logMessage(message: string): void;
}
// Low Level Module #1
class FileLogger implements Logger {
logMessage(message: string): void {
fs.writeFileSync('somefile.txt', message);
}
}
// Low Level Module #2
class ConsoleLogger implements Logger {
logMessage(message: string): void {
console.log(message);
}
}
// High Level Module
class MessageProcessor {
// Resolved: The high level module is now loosely coupled with the low level logger modules.
private _logger: Logger;
constructor (logger: Logger) {
this._logger = logger;
}
processMessage (message: string): void {
this._logger.logMessage(message);
}
}
//Usage
const fileLogger = new FileLogger();
const consoleLogger = new ConsoleLogger();
// Now the logging mechanism can be easily replaced
const messageProcessor = new MessageProcessor(consoleLogger);
messageProcessor.processMessage('Hello');
DIP Before and After:
DRY ( Don't Repeat Yourself)
DRY (don't repeat yourself), also known as DIE(duplication as evil), states that you shouldn't duplicate information or knowledge across your codebase.
"Every piece of knowledge must have a single, unambiguous, authoritative, representation within a system" — Andy Hunt and Dave Thomas, The Pragmatic Programmer.
The benefit of reducing code repetition is the simplicity of changing and maintaining it. If you duplicate your logic in several places and then find a bug, you are likely to forget to change it in one of the places, which will lead to different behavior with seemingly identical functionality. Instead, find a repetitive functionality, abstract it in the form of a procedure, class, etc, give it a meaningful name, and use it when needed. This advocates a single point of change and minimizes the breaking of unrelated functionality.
Let's take a product page from a simple E-commerce application, for example. We expect to see a list of products for sale. We can break down a page into smaller, reusable components.
// ProductCard.js
import React from 'react';
const ProductCard = ({ product }) => {
return (
<div>
<h2>{product.name}</h2>
<p>Price: ${product.price}</p>
<p>Description: {product.description}</p>
</div>
);
};
export default ProductCard;
// ProductList.js
import React, { useState } from 'react';
import ProductCard from './ProductCard';
const ProductList = () => {
const [products, setProducts] = useState([
{ id: 1, name: 'Product 1', price: 9.99, description: 'Description 1' },
{ id: 2, name: 'Product 2', price: 19.99, description: 'Description 2' },
// ...
]);
return (
<div>
{products.map((product) => (
<ProductCard key={product.id} product={product} />
))}
</div>
);
};
export default ProductList;
In this example, we see that by segregating the logic concerning a product into the ProductCard component, we can reuse it in the map functionality in the ProductList component and avoid duplicated code for every product item on the List page.
YAGNI (You Aren't Gonna Need It)
When you design a solution to the problem, you are thinking about how to adapt it to the current system better and how to make it extensible for possible feature requirements. In the second case, the design to build a premature feature for the sought better extensibility is usually wrong: even if you now think that this will reduce the cost of integration, then maintenance and debugging of such code may not be obvious and unnecessarily complicated. Thus, you violate the previous principle by reducing the redundant complexity of the solution to the current problem. Also, don't forget there's a good chance that your presumed functionality may not be needed in the future, and then you are just wasting resources.
Here's a detailed look at how to apply YAGNI in practice:
Example: Without YAGNI
Imagine you are building a profile component. You might be tempted to add features for future requirements that are not currently needed, such as handling different themes or adding complex animations:
// UserProfile.tsx
import React from 'react';
interface User {
name: string;
email: string;
phone: string;
// Future feature: theme
theme?: 'light' | 'dark';
// Future feature: animations
enableAnimations?: boolean;
}
const UserProfile: React.FC<{ user: User }> = ({ user }) => {
// Apply theme (not needed right now)
const themeClass = user.theme === 'dark' ? 'dark-theme' : 'light-theme';
return (
<div className={`user-profile ${themeClass}`}>
<h2>{user.name}</h2>
<p>Email: {user.email}</p>
<p>Phone: {user.phone}</p>
{/* Future feature: animations */}
{user.enableAnimations && <div className="animations">Animations here</div>}
</div>
);
};
export default UserProfile;
Example: With YAGNI
Now let's refactor the code to follow the YAGNI principle by removing unnecessary features and focusing only on the current requirements:
// UserProfile.tsx
import React from 'react';
interface User {
name: string;
email: string;
phone: string;
}
const UserProfile: React.FC<{ user: User }> = ({ user }) => (
<div className="user-profile">
<h2>{user.name}</h2>
<p>Email: {user.email}</p>
<p>Phone: {user.phone}</p>
</div>
);
export default UserProfile;
That is what YAGNI or "You Aren't Gonna Need It" is all about. Don't get it wrong; you should think about what will be with your solution in the future, but only add code when you actually need it.
KISS (Keep It Simple, Stupid)
The first on my list of important software engineering principles is KISS. It is an acronym for "Keep It Simple, Stupid".
Software systems work best when they are kept simple. Avoiding unnecessary complexity will make your system more robust, easier to understand, easier to reason, and easier to extend.
It's so obvious. But we, engineers, often tend to complicate things. We use those fancy language features that no one knows about and feel proud of. We introduce countless dependencies in our projects for every simple thing, and end up in dependency hell. We create endless microservices for every simple thing.
Remember that whenever you add a new dependency to your project, start using a new fancy framework, or create a new microservice, you are introducing additional complexity to your system. You need to think whether that complexity is worth it or not.
Let's look at 2 implementations of a Counter component.
// Complex Counter
import React, { useState, useEffect } from 'react';
import { debounce } from 'lodash';
const ComplexCounter = () => {
const [count, setCount] = useState(0);
const [clicked, setClicked] = useState(false);
const [error, setError] = useState(null);
useEffect(() => {
if (clicked) {
setCount(prev => prev + 1)
setClicked(false)
}
}, [clicked, setClicked]);
const handleClick = (clicked: boolean) => {
setClicked(!clicked);
};
return (
<div>
<p>Count: {count}</p>
<button onClick={() => handleClick(clicked)}>Increment</button>
</div>
);
};
export default ComplexCounter;
// Simple Counter
import React, { useState } from 'react';
const SimpleCounter = () => {
const [count, setCount] = useState(0);
const handleClick = () => {
setCount(count + 1);
};
return (
<div>
<p>Count: {count}</p>
<button onClick={handleClick}>Increment</button>
</div>
);
};
export default SimpleCounter;
We see that the ComplexCounter implementation is harder to understand and maintain and more prone to errors.
It introduced an unnecessary state variable for a clicked and a useEffect hook.
SOC (Separation Of Concerns)
The Separation Of Concern (SOC) principle suggests breaking the system into smaller parts depending on its concerns. A "concern" in that meaning implies a distinctive feature of a system.
For example, if you are modeling a domain, each object can be treated as a special concern. In a layered system, each layer has its own care. In a microservice architecture, each service has its own purpose. This list can continue indefinitely.
The main thing to take out from the SoC is:
Identify the system concerns.
Divide the system into separate parts that solve these concerns independently of each other.
Connect these parts through a well-defined interface.
In this fashion, the separation of concerns is very similar to the abstraction principle. The result of adhering to SoC is easy to understand, modular, reusable, built on stable interfaces, and testable code.
LoD (Law Of Demeter)
The Law Of Demeter (LoD), sometimes referred to as the principle of least knowledge, advises against talking to "strangers". Because LoD is usually considered with OOP, a "stranger" in that context means any object that is not directly associated with the current one.
The benefit of using Demeter's Law is maintainability, expressed by avoiding immediate contact between unrelated objects.
As a result, when you interact with an object and one of the following scenarios is not met, you violate this principle:
When the object is the current instance of a class (accessed via this)
When the object is a part of a class
When the object is passed to a method through the parameters
When the object is instantiated inside a method
When the object is globally available
To give an example, let's consider a situation when a customer wants to make a deposit into a bank account. We might end up here having three classes - Wallet, Customer, and Bank.
class Wallet {
private decimal balance;
public decimal getBalance() {
return balance;
}
public void addMoney(decimal amount) {
balance += amount
}
public void withdrawMoney(decimal amount) {
balance -= amount
}
}
class Customer {
public Wallet wallet;
Customer() {
wallet = new Wallet();
}
}
class Bank {
public void makeDeposit(Customer customer, decimal amount) {
Wallet customerWallet = customer.wallet;
if (customerWallet.getBalance() >= amount) {
customerWallet.withdrawMoney(amount);
//...
} else {
//...
}
}
}
You can see the violation of the Demeter Law in the makeDeposit method. Accessing a customer wallet in terms of LoD is right(although it's a strange behavior from a logic perspective). But here, a bank object invokes the getBalance and withdrawMoney from the customerWallet object, thus talking to the stranger (wallet), instead of a friend (customer).
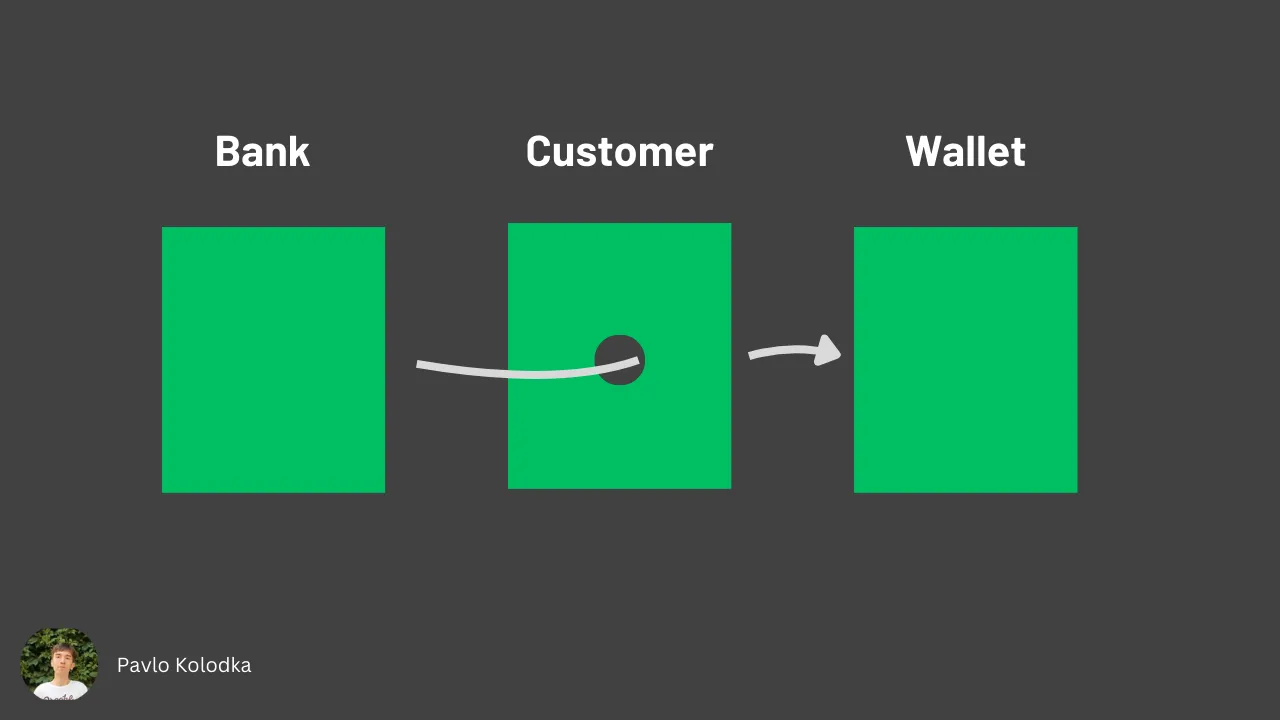
Here is how to fix it:
class Wallet {
private decimal balance;
public decimal getBalance() {
return balance;
}
public boolean canWithdraw(decimal amount) {
return balance >= amount;
}
public boolean addMoney(decimal amount) {
balance += amount
}
public boolean withdrawMoney(decimal amount) {
if (canWithdraw(amount)) {
balance -= amount;
}
}
}
class Customer {
private Wallet wallet;
Customer() {
wallet = new Wallet();
}
public boolean makePayment(decimal amount) {
return wallet.withdrawMoney(amount);
}
}
class Bank {
public void makeDeposit(Customer customer, decimal amount) {
boolean paymentSuccessful = customer.makePayment(amount);
if (paymentSuccessful) {
//...
} else {
//...
}
}
}
Now, all interaction with a customer wallet is going through the customer object. This abstraction favors loose coupling, easy changing of the logic inside the Wallet and Customer classes (a bank object shouldn't worry about the customer's internal representation), and testing.
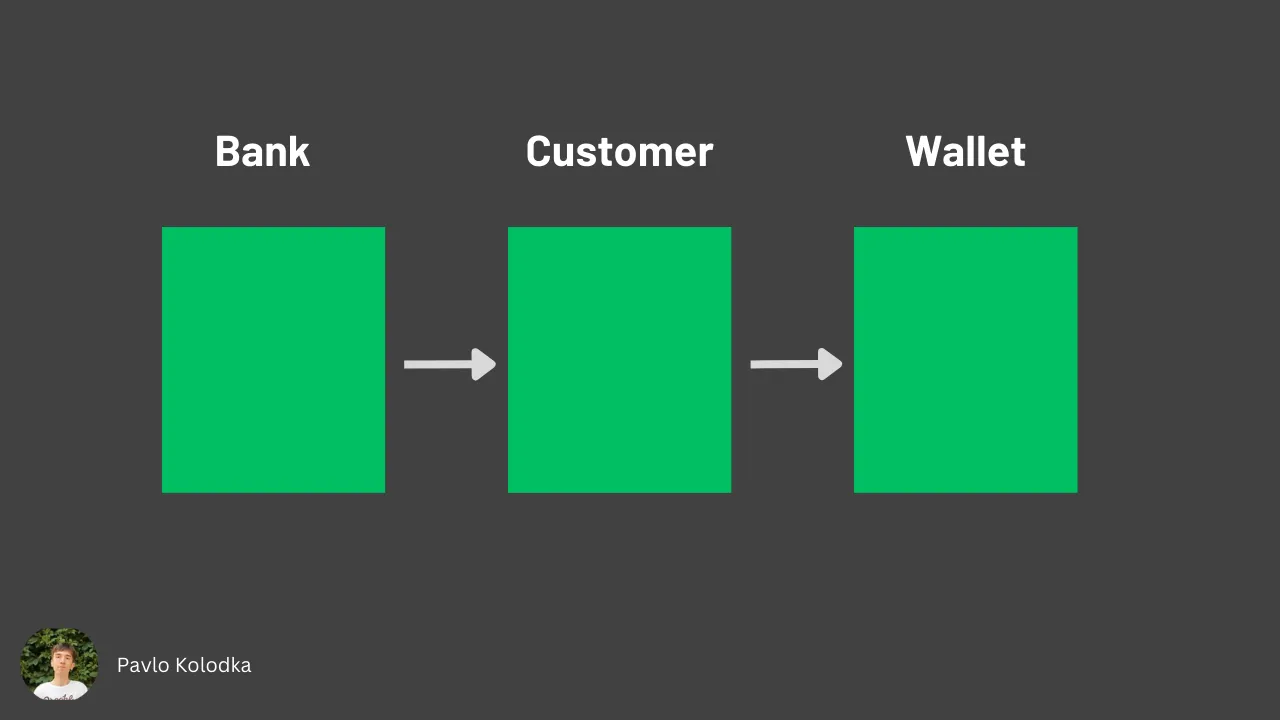
Generally, you can say that LoD fails when there are more than two dots applied to one object, like object.friend.stanger instead of object.friend.
\=> The article is lengthy, and we still have several important principles to cover. See you in Part II.
Locality of Behavior (LoB) in Software
For many years now, there is been talk of “principles” of software engineering, and how adherence/defiance to them makes/breaks a piece of software.
However, I don’t think it’s that simple. Thinking of them as principles means that they are non-negotiable, and it’s always the right thing to follow them. On the other hand, thinking of them as techniques opens you up to considering applying them only where it makes sense and improves things.
When a certain technique gets applied in the right context, it can bring a lot of value and make your code platform better and be easier to read, understand, and maintain. Conversely, when a technique is applied in the wrong context, without a full understanding of why it’s unsuitable, the effect on your code can be very detrimental.
There is no silver bullet. No “principle“ has it all and will always make your code better, apart from the simple “be sensible about it“, which isn’t a principle one learns by reading about it in a book. It’s something you attain with years of practice and learning from mentors.
With that being said, there's this cool "new" kid on the block called "Locality of Behavior" (LoB). It can be defined as follows:
The behaviour of a unit of code should be as obvious as possible by looking only at that unit of code
This points back to a quote from a book by Richard P. Gabriel, which states that:
The primary feature for easy maintenance is locality: Locality is that characteristic of source code that enables a developer to understand that source by looking at only small portion of it.
The value of this idea increases in the context of large applications that host a lot of components. Usually, what developers do in order to make this application easier to maintain is that they split the components into their own modules. This can quickly lead to you having to jump multiple times in order to understand what a small piece of code does. This is commonly referred to as the Separation of Concerns (SoC).
If you successfully manage to bring that scattered code closer together, this will increase your productivity, reduce frustrations, and improve your satisfaction with your work.
The goal is that if you need to understand or modify some behaviour in the system, you will find most, if not all, of the functionality easily, in a single place, and will be able to understand it quickly.
There are a few things one can consider that will make the conflict between LoB and SoC less impactful:
When your system and its code are rather simple, it’s usually better to be able to see everything at once
as the code for a particular component or service grows more complex, at some point it is very useful to be able to understand business logic in isolation, without it being tangled with other concerns
following the above two, you can start with something simple and when it becomes harder to understand and follow, start separating those concerns in a way that makes it easier to understand
when you split these concerns to separate files do your best to keep them close together, so it’s still easy to understand the whole thing by looking at a single package instead of having to jump to multiple different places while keeping the whole thing into perspective
Dogmatic adherence to any of the two is naturally the wrong approach. Do what feels sensible in your current situation, so that you can make the most of what these "principles" have to offer you.
Correctly applying LoB to your system will, in turn, also increase the cohesion and decrease the coupling of your code, which is a strongly preferable characteristic of your codebase.
First Principles Thinking

First principle thinking can be helpful for solving complex problems because it allows you to break down the complex problem into its core elements and then systematically build up a solution from there. This can be a more effective approach than trying to solve a problem using preconceived notions or by making assumption about the problem based on your past experiences.
It is used in computer science, engineering, and physics, but there are also problems that can be drawn for first principles thinking for any industry.
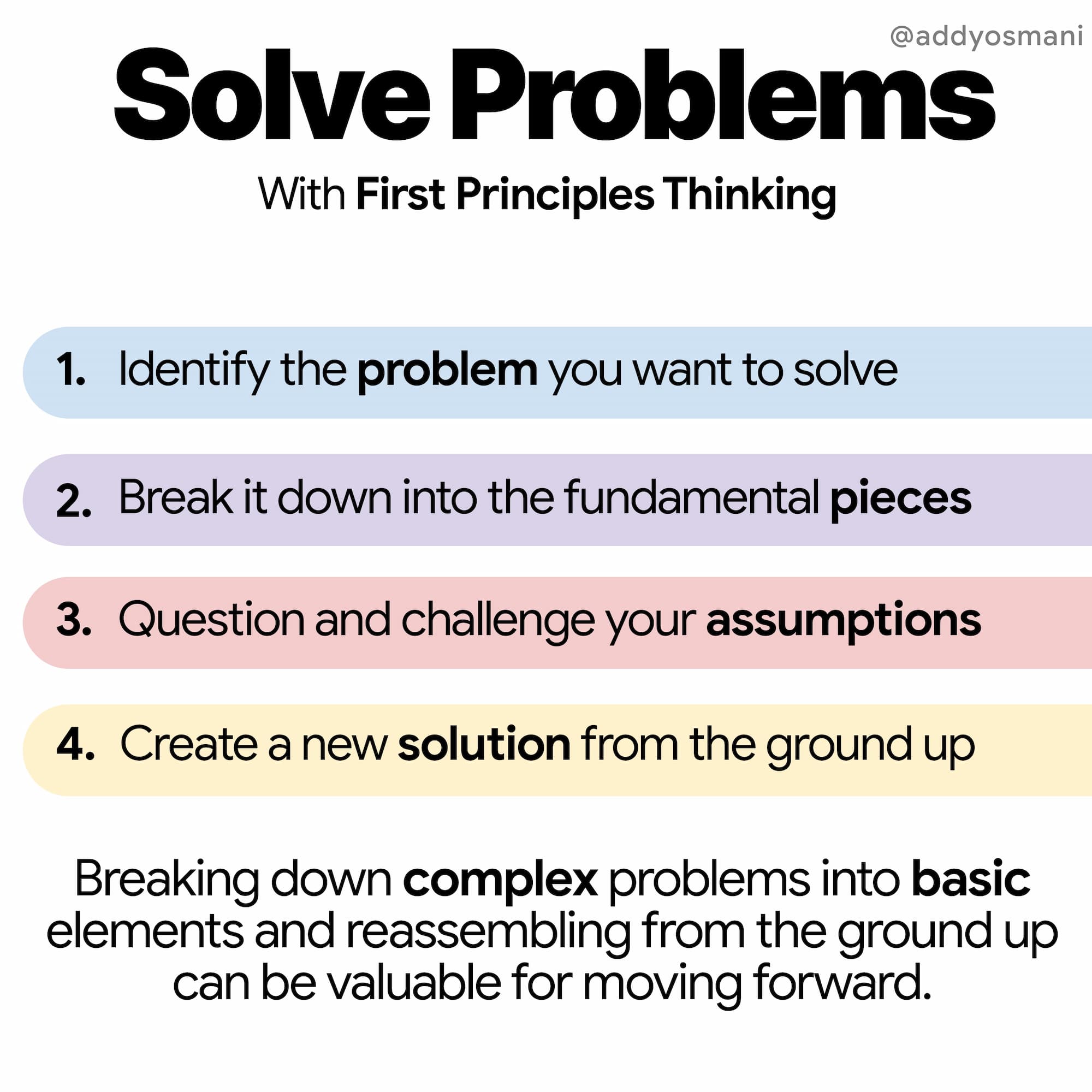
At a high level, there are roughly 4 steps to applying first principles:
Identify the problem you want to solve
Break it down into the fundamental pieces
Question and challenge your assumptions
Create a new solution from the ground up
What does “First Principle“ Mean?
A first principle is a starting point or assumption that you use to build your argument. First principles thinking refers to the process of breaking a problem down into its fundamental parts and working through each part in order until you reach an answer.
First principles thinking differs from other problem-solving techniques because it allows you to focus on the most important elements of the problem without getting distracted by extraneous details or secondhand information. By following this approach, you will be able to reach solutions more quickly and confidently than if you skipped certain steps of your reasoning process.
First Principles Thinking is a way of analyzing complex problems by looking at the root causes.
History of First Principles Thinking
The concept of First Principles has a long history in philosophy and science. It can be traced back to the ancient Greek philosopher Aristotle, who argued that all knowledge and understanding must be derived from first principles. In his writings, Aristotle emphasized the importance of starting with self-evident truths or axioms and using logical reasoning to deduce more complex ideas.
The concept of first principles has continued to be influential in the development of modern scientific and philosophical thought. In the 17th and 18th centuries, philosophers such as René Descartes and Immanuel Kant also emphasized the importance of starting with first principles and using reason to deduce knowledge and understanding.
In the 20th century, physicist Richard Feynman popularized the use of the Feynman technique, which involves breaking down a concept or problem into its fundamental principles in order to better understand and solve it.
Step 1: Identify the problem you want to solve and break it down into the fundamental pieces.
First Principle Thinking starts with identifying the most important parts of a problem and then breaking them down into their component parts.
Identify the most important parts of your problem
Break each part down into its component parts, then identify how each part relates to the whole.
Repeat this process until you have broken everything down as far as you can go.
Step 2: Ask Why?
Once you have broken down the issue into its constituent parts, it’s time to ask why. Asking why five times is a useful way of identifying the root cause of a given problem or outcome by getting to its source. When you ask “Why?“ each time and keep digging deeper and deeper, you can eventually get to the heart of any problem or outcome, even if it seems like there are multiple causes at play.

To illustrate how it works, let’s look at an example. You may feel like your team isn’t working effectively because they are not communicating well with one another. However, after asking yourself why 5 times (and using your imagination), we might come up with something like this:
Why? We aren’t communicating well because we haven’t established clear expectations for what information needs to be shared across departments.
Why? Because the company hasn’t set up rigorous processes for sharing information across departments.
Why? Leaders may not know how important it is for employees to share information freely within their departmental teams.
on so on.
Step 3: Challenge your Assumptions
Assumptions are the foundation on which you build your solution. They can be either right or wrong, but they’re always based on facts that you know to be true at this point in time. If your assumptions are correct, then they should lead you to a good solution; if they’re incorrect, then they may cause issues later on down the line.
Assumptions can be categorized into three groups:
Market Assumptions (about the market itself)
Problem Assumptions (about the problem itself)
Solution Assumptions (about your proposed solution and its components)
People's Assumptions (about people involved in achieving success).
Step 4: Create a new solution from the ground up by focusing on your goal
The next step is to focus on your goal. The first step was to identify the problem, and the second step was to gather information about what needs to be done in order to solve it. Now is the time when you need to direct your focus toward the end result of solving that problem.
In practice, this means:
Don’t get distracted by details unless they’re pertinent to solving your problem(s) and achieving your goals
Stay focused on achieving those goals and don’t worry about what might happen along the way
Applying First Principles for Software Projects
First principles thinking can help with software development in several ways. Some specific ways in which this approach can be beneficial include:
It helps to clarify the problem or challenge that the software is intended to solve by breaking it down into its fundamental principles and identifying the key requirements and objectives.
It provides a basis for making informed design and development decisions by using the identified principles to guide the selection of technologies, architectures, and design patterns.
It helps to identify and address gaps or inconsistencies in the understanding of the problem by using the principles to evaluate the robustness and effectiveness of the solution.
Here are two examples of applying first principles thinking to the questions you can ask when developing products:
Designing a commerce application
Product questions:
Why does the user need this app? To quickly find and purchase an item because they need it.
Why do they need us to reduce the number of steps in the checkout process? They want to save time. One-click checkout may help.
Why do they need us to support reviews? This helps build trust in the items they are buying and can help them decide to purchase faster.
Engineering questions:
What are the minimum requirements for these features? A search box and a way to filter results and product pages, category pages, and a way to checkout.
Which technologies can we use to build this? The commerce platform already has an API for searching, filtering, and displaying results. Maybe a basic UI in CSS+JS on top of this is enough.
How do our users interact with each other? They can leave product reviews, which are visible to everyone in the system. We probably need to support creating/managing reviews.
Building a social network app: Questions
Why does the user need this app? A user wants to find other people with similar interests and then connect with them. They can search profiles, read public information about a person, and leave comments on their profile.
Why do users need to interact with each other? They want to send messages or leave comments that are visible on their profile page.
What is our data model? Users have profiles, and they can add photos to their profiles. How are we going to represent users in the system? A user will have a name, an email address (which we can use for messaging), as well as some other basic information like age or gender.
Downsides to thinking in first principles
Some of the downsides to thinking in first principles are that it can be hard to do, especially if we’re not used to thinking that way. It also requires us to be open-minded and willing to invest time and energy into understanding the problem from all angles so we don’t miss anything important.
It’s time-consuming because we have to keep breaking down problems into smaller and smaller components until we reach their basic building blocks.
It can be difficult to know when to stop - if our goal is to find the most efficient way of doing something (such as making a car), then it may not matter if there are other ways of achieving that goal that would require less energy or fewer resources (perhaps some other manufacturer has figured out how to make cars more cheaply, but they just don’t want us to know about it).
You find that one or more of your beliefs is not well-founded.
How first principles thinking fails is also worth reading.
That said, these are not reasons to stop applying first principles thinking. They just mean that we have to be careful when applying it and make sure that we don’t let ourselves get carried away with our own ideas or assumptions.
References
https://www.callicoder.com/software-development-principles/
https://dev.to/lukeskw/solid-principles-theyre-rock-solid-for-good-reason-31hn
https://dev.to/idanref/solid-the-5-golden-rules-to-level-up-your-coding-skills-2p82?ref=dailydev
https://dev.to/kevin-uehara/solid-the-simple-way-to-understand-47im?context=digest
https://medium.com/dailyjs/applying-solid-principles-in-react-14905d9c5377
https://github.com/mehdihadeli/awesome-software-architecture/tree/main
https://deviq.com/principles/principles-overview
https://addyosmani.com/blog/first-principles-thinking-software-engineers/?ref=dailydev
https://thetshaped.dev/p/open-closed-principle-ocp-in-react-write-extensible-components?ref=dailydev
https://thetshaped.dev/p/single-responsibility-principle-srp-in-react-write-focused-components
https://www.linkedin.com/pulse/locality-behavior-lob-software-hristo-naydenov-3zmvf/
Subscribe to my newsletter
Read articles from Tuan Tran Van directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tuan Tran Van
Tuan Tran Van
I am a developer creating open-source projects and writing about web development, side projects, and productivity.