Summarizing Recent Wins for Apache Iceberg Table Format
 Alex Merced
Alex Merced
Apache Iceberg is a table format that allows groups of Parquet files in a data lake to be recognized as database tables. These tables can be easily queried using SQL with various engines or loaded into popular Python dataframe libraries such as Polars, Pandas, Ibis, or SQLFrame. This technology supports an architecture known as the Data Lakehouse, which allows you to use all your favorite tools and platforms against a single copy of your data. This approach eliminates the need to create multiple copies of your data across several tools, reducing costs, consistency issues, and other headaches.
One of the challenges that has held back the widespread adoption of Data Lakehouses is the fear of “picking the wrong format” among the three main formats: Apache Iceberg, Apache Hudi, and Delta Lake. However, several recent events have solidified Apache Iceberg as the industry standard that enterprises can confidently adopt. In this blog, I will discuss some of these significant events to illustrate Apache Iceberg’s current momentum.
Dremio & Nessie adopting the REST Catalog Specification
In the keynote for the 2024 Subsurface conference, it was announced that the Dremio query engine would support the Iceberg REST Catalog specification, enabling it to query Iceberg tables in any catalog that supports this specification. Additionally, it was revealed that Nessie, the open-source catalog originally developed by Dremio, would also adopt the REST Catalog spec, allowing it to be queried by any engine that supports the specification. In previous articles, I have discussed the role of the REST Catalog specification and the evolution of Apache Iceberg catalogs. The increased adoption of the REST Catalog advances Nessie’s growing ecosystem and fosters a greater open Iceberg ecosystem where tools and data can interoperate seamlessly.
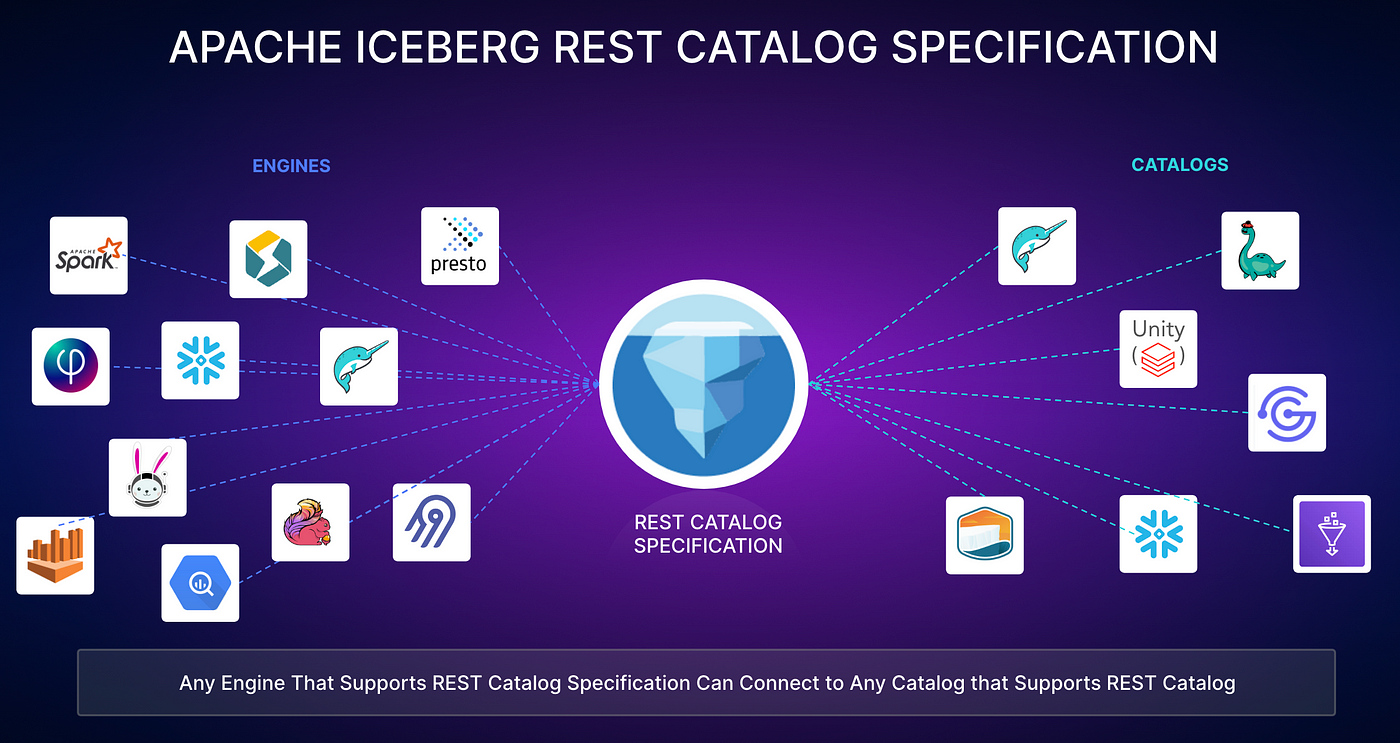
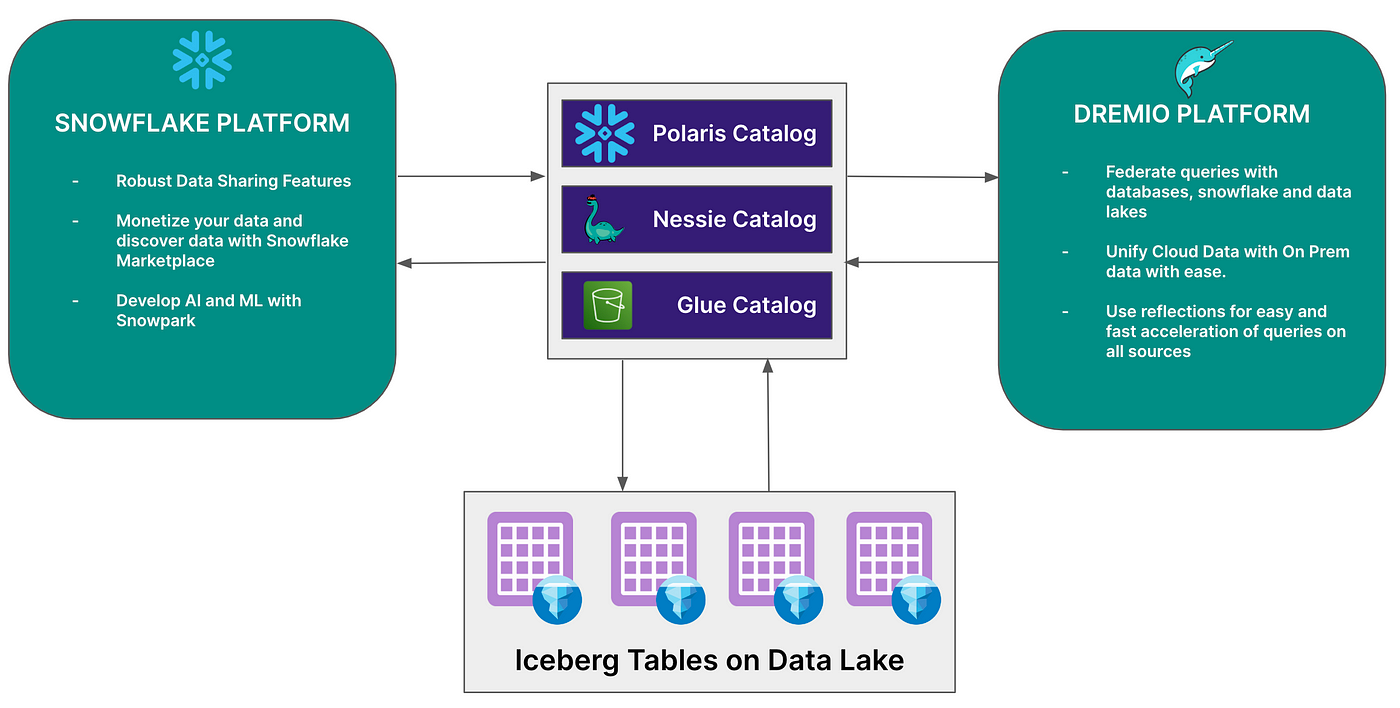
Snowflake Announces the Open Source Polaris Catalog
Earlier this week at the Snowflake Summit, Snowflake announced its continued commitment to being part of an open Apache Iceberg ecosystem with the introduction of a new open-source catalog, Polaris. Polaris will enhance the security and governance of your data while making it portable in an open-source catalog. This catalog will also employ the REST Catalog specification, making it compatible with engines like Dremio, Apache Spark, and others. Additionally, Snowflake demonstrated the use of REST Catalog-conforming catalogs with its externally managed tables feature, showcasing Nessie’s upcoming REST Catalog implementation in the demo. These announcements have solidified a vision where you no longer have to choose between the exceptional features of platforms like Snowflake and Dremio. Instead, you can benefit from both simultaneously on a single copy of your data.
Databricks Buys Tabular
Another groundbreaking announcement this week was the billion-dollar acquisition of Tabular by Databricks. Tabular, an enterprise Iceberg company founded by the creators of Apache Iceberg — Ryan Blue, Dan Weeks, and Jason Reid — offers a catalog that optimizes data behind the scenes using practices and automations developed at Netflix, where Iceberg was initially created. This acquisition is significant as it signals Databricks’ greater acceptance that Apache Iceberg has become the standard for data lake table formats, despite their stake in the prevalence of Delta Lake.
While other formats like Delta Lake and Hudi are not going away, their proponents have acknowledged Apache Iceberg’s growing prominence by creating translation layers such as Delta Lake’s “UNIformat” and Apache XTable, a metadata translation project initiated by Onehouse, the company founded by the creators of Apache Hudi. With Databricks purchasing Tabular and integrating its engineering team and functionality into the existing Unity Catalog, it is clear that Databricks has recognized the necessity of making Apache Iceberg a first-class citizen on their platform alongside Delta Lake.

Microsoft Fabric Adds Apache Iceberg Support
Microsoft has been a key partner in the growth of Databricks and Delta Lake, allowing Databricks to offer their product as a first-party service on Azure. Over time, Microsoft decided to provide their own product to fill the same space, resulting in the creation of Microsoft Fabric. This platform enables existing Databricks customers to create Spark Notebooks and work with Delta Lake tables within a Microsoft-native service. Microsoft even incorporated an optimized Spark engine, utilizing many emerging Spark engine replacement technologies, to offer a faster Spark notebook experience as an alternative to Databricks on the Azure platform.
Recently, Microsoft partnered with Snowflake to add OneLake to Fabric, a service that allows datasets on Fabric to be used as Delta Lake and Iceberg datasets, facilitated by Apache XTable. This partnership is another example of large industry players, who previously only had first-party support for Delta Lake, recognizing the need to add first-party support for Apache Iceberg to keep up with industry trends.

Apache Iceberg: The Definitive Guide best selling new release
As one final signal of Apache Iceberg’s momentum, the new O’Reilly book, “Apache Iceberg: The Definitive Guide,” is a best-selling new release on Amazon, highlighting the growing interest in this topic. Full disclosure, I am one of the authors of the book. You can get a free PDF of the book here and order a physical copy here.
Conclusion
The recent announcements and industry movements underscore the rapid adoption and growing prominence of Apache Iceberg as a leading table format in the data ecosystem. From Dremio’s support for the Iceberg REST Catalog specification to Snowflake’s introduction of Polaris, and Databricks’ significant acquisition of Tabular, it’s clear that major players are embracing Iceberg’s open and flexible architecture. Microsoft’s integration of OneLake with Fabric further emphasizes the industry’s shift towards supporting both Delta Lake and Iceberg to meet evolving data needs. These developments, along with the success of “Apache Iceberg: The Definitive Guide,” signal a bright future for Apache Iceberg as it continues to drive innovation and interoperability across data platforms.
LIST OF EXERCISES TO GET HANDS ON WITH APACHE ICEBERG
Exercises to Get Hands-on with Apache Iceberg on Your Laptop
Subscribe to my newsletter
Read articles from Alex Merced directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Alex Merced
Alex Merced
Alex Merced is a developer advocate at Dremio with experience as a developer and instructor. His professional journey includes roles at GenEd Systems, Crossfield Digital, CampusGuard, and General Assembly. He co-authored "Apache Iceberg: The Definitive Guide" published by O'Reilly and has spoken at notable events such as Data Day Texas and Data Council. Alex is passionate about technology, sharing his expertise through blogs, videos, podcasts like Datanation and Web Dev 101, and contributions to the JavaScript and Python communities with libraries like SencilloDB and CoquitoJS. Find all youtube channels, podcasts, blogs, etc. at AlexMerced.com