Understanding Salting Technique in Spark
 Ajay Veerabomma
Ajay Veerabomma
Apache Spark is a powerful open-source distributed computing system known for its speed, ease of use, and sophisticated analytics capabilities. It is widely used for big data processing and analytics due to its ability to handle large-scale data across a cluster of machines. However, like any other distributed computing system, Spark faces challenges that can affect its performance. One such challenge is data skew, where some partitions of data are significantly larger than others. This imbalance can lead to inefficient resource utilization and slow down the entire data processing pipeline.
Data skew can occur in various scenarios, such as during group by operations or joins, where certain keys are much more frequent than others. This uneven distribution of data can cause some tasks to take much longer to complete, creating bottlenecks in the processing workflow. To address this issue, one effective method is the salting technique. Salting involves adding a random value to the keys of the skewed data to distribute it more evenly across the partitions.
In this blog post, we'll delve into the concept of salting in detail. We'll discuss what salting is, the situations in which it is most beneficial, and the reasons why it can significantly enhance performance. Additionally, we'll provide a step-by-step guide on how to implement salting in Apache Spark, particularly focusing on scenarios involving group by operations and skewed joins. By the end of this post, you'll have a comprehensive understanding of how to use salting to mitigate data skew and optimize your Spark applications for better performance.
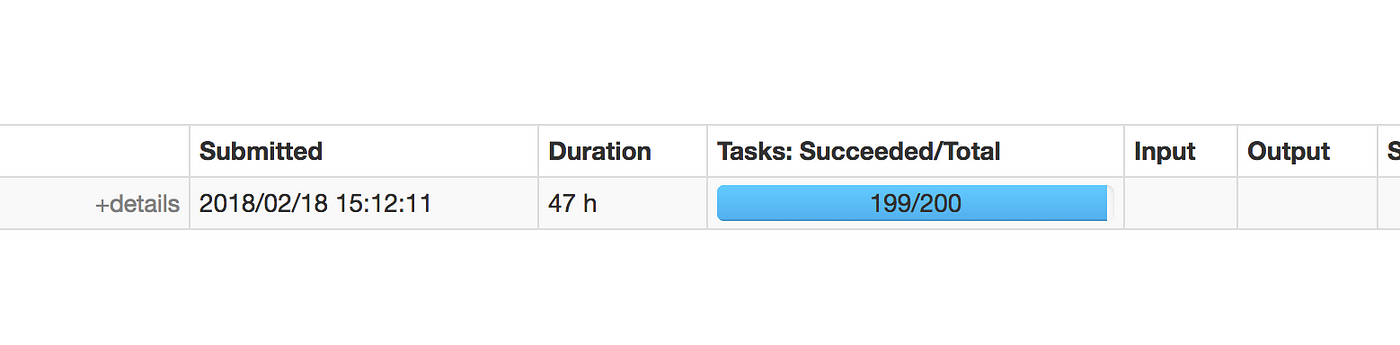
Have you ever encountered a situation where 199 out of 200 tasks complete quickly, but the last task takes an exceptionally long time to finish? This common issue can be frustrating, especially when you're eagerly waiting for all tasks to complete. This scenario often occurs due to data skew, where one task is overloaded with a disproportionate amount of data compared to the others. As a result, this single task becomes a bottleneck, delaying the entire process. Understanding and addressing this problem is crucial for optimizing your data processing workflows and ensuring efficient resource utilization.
To solve such scenarios, we need to have a deep understanding of the internals of Apache Spark and how our data is distributed among the executors. First, it's important to grasp how Spark partitions data and assigns these partitions to different executors. Each executor processes a subset of the data, and ideally, this data should be evenly distributed to ensure that all executors finish their tasks around the same time. However, in cases of data skew, some partitions end up with significantly more data than others, causing certain executors to take much longer to complete their tasks.
To address this, we can use techniques such as salting, which involves adding a random value to the keys of our data to distribute it more evenly across partitions. By doing so, we can mitigate the effects of data skew and ensure a more balanced workload among executors. This process requires a good understanding of the data's structure and the specific operations being performed, such as group by operations or joins, which are particularly prone to skew.
Implementing salting involves several steps, including identifying the skewed keys, generating salt values, and applying these salts to redistribute the data. By carefully following these steps and monitoring the performance of your Spark jobs, you can significantly improve the efficiency and speed of your data processing workflows. This detailed approach not only helps in solving the immediate issue of data skew but also enhances the overall performance and scalability of your Spark applications.
When is Salting Used?
Salting is particularly useful in situations where data skew causes certain partitions to become much larger than others. This is common in operations like group by or joins where the distribution of keys is uneven. Data skew can lead to significant performance degradation as some nodes in the cluster handle much more data than others, leading to inefficient use of resources and longer execution times.
What Does Salting Do?
Salting helps to mitigate data skew by artificially creating more keys to distribute the data more evenly across partitions. This is done by adding a random or hash-based salt value to the key, which helps to spread out the data more uniformly across the partitions. This technique can be applied in various scenarios, including group by operations and skew joins.
Working Example: Salting in Group By Scenario
Let's consider a scenario where we have a dataset of user actions, and we want to count the actions per user. If some users have significantly more actions than others, this can lead to data skew.
Original Code Without Salting:
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("SaltingExample").getOrCreate()
import spark.implicits._
val data = Seq(
("user1", "click"),
("user2", "click"),
("user1", "purchase"),
// ... more data
).toDF("user", "action")
val groupedData = data.groupBy("user").count()
groupedData.show()
In scenarios where data is highly skewed at the user level, such as in a dataset where user1 has 100 records and user2 has only 10 records, the internal distribution of data among the executors can become unbalanced. If we have 5 executors available, this skew might result in user1's data being processed by executor 1, user2's data by executor 2, and the remaining 3 executors staying idle. This leads to inefficient use of resources and reduced parallelism, as not all executors are utilized effectively.
To address this issue and enhance parallelism, we can apply the salting technique. Salting helps by adding a random or hash-based salt value to the keys, which distributes the records more evenly across all executors. This ensures that the workload is spread out, allowing each executor to process a portion of the data, rather than some executors being overloaded while others remain idle.
Applying Salting:
import org.apache.spark.sql.functions._
val saltedData = data.withColumn("salt", monotonically_increasing_id() % 10)
val saltedKey = concat($"user", lit("_"), $"salt")
val saltedGroupedData = saltedData.groupBy(saltedKey).count()
// Remove salt and aggregate counts
val finalResult = saltedGroupedData.withColumn("user", split($"saltedKey", "_")(0))
.groupBy("user")
.agg(sum("count").as("total_count"))
finalResult.show()
In this example, we add a salt value to the user key, distribute the data more evenly, and then remove the salt value after grouping and counting.
Working Example: Salting in Skew Join Scenario
In join operations, data skew can cause one node to handle most of the data, leading to performance bottlenecks. Salting can also be applied to skew joins to distribute the join keys more evenly.
Original Code Without Salting:
val largeTable = // some large DataFrame
val smallTable = // some small DataFrame
val joinedData = largeTable.join(smallTable, "key")
joinedData.show()
Applying Salting:
val saltSize = 10
val saltedLargeTable = largeTable.withColumn("salt", monotonically_increasing_id() % saltSize)
val saltedLargeKey = concat($"key", lit("_"), $"salt")
val saltedSmallTable = smallTable.withColumn("salt", explode(lit((0 until saltSize).toArray)))
val saltedSmallKey = concat($"key", lit("_"), $"salt")
val saltedJoinedData = saltedLargeTable.join(saltedSmallTable, saltedLargeKey)
saltedJoinedData.show()
In this example, we add salt values to the keys of both tables and perform the join on the salted keys. This distributes the data more evenly and improves performance.
wonder how does that happen?
Original Tables:
largeTable: Has a key
value.smallTable: Contains matching keys for join operations.
Salting Process:
In the
largeTable, the keys are modified by appending a salt number, resulting in keys likevalue_1,value_2, etc.This breaks down the large dataset into smaller chunks based on the salt value, distributing them more evenly.
Replication of Small Table:
- The
smallTableis duplicated for each salt value, so there are multiple versions (e.g.,smallTable1,smallTable2), each containing the same data but with different salt suffixes.
- The
Join Operation:
The join operation matches each salted key from the
largeTablewith the corresponding entry in the duplicatedsmallTable.This ensures that the join is balanced across all partitions, allowing better use of computational resources and reducing the risk of performance bottlenecks.
Original Datasets:
Dataset1 Dataset2
-------- --------
apple apple
orange orange
apple
Post-Salting Datasets:
Dataset1 Dataset2
-------- --------
apple_1 apple_1
orange_1 orange_1
apple_2 apple_2
orange_2 (ignored)
Join happens on :
apple_1 -> apple_1
orange_1 -> orange_1
apple_2 -> apple_2
When to Use Salting and Why?
Salting is particularly useful in scenarios where data skew is causing performance issues, such as in group by operations or joins with highly uneven key distributions. It helps to distribute the data more evenly across the cluster, leading to better resource utilization and faster execution times.
Why Use Salting Over Repartition?
While repartitioning can also help distribute data more evenly, it does not address the root cause of data skew—uneven key distribution. Repartitioning simply redistributes existing partitions, which can still lead to skew if the keys themselves are unevenly distributed. Salting, on the other hand, directly tackles the problem by altering the keys themselves to ensure a more even distribution.
Key Points:
Repartitioning: Useful for general data distribution, but may not solve key-based skew.
Salting: Specifically targets key-based skew by altering the keys, providing a more targeted solution for skewed data.
Conclusion
Salting is a powerful technique in Spark to handle data skew, especially in group by and join operations. By adding a salt value to keys, we can distribute data more evenly across the cluster, leading to better performance and resource utilization. While repartitioning can help with general data distribution, salting provides a more targeted solution for key-based skew. Understanding and implementing salting can significantly enhance the performance of your Spark applications, especially in scenarios with highly skewed data.
Subscribe to my newsletter
Read articles from Ajay Veerabomma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by