Getting Started with Spring AI and Ollama: A Quick Guide to Using Microsoft Phi3 Language Models
 Virendra Oswal
Virendra Oswal
Introduction
In the realm of artificial intelligence (AI) and machine learning (ML), Python has long been the language of choice due to its simplicity and the vast array of libraries and frameworks available. However, Java developers are not left behind. The Spring Framework ecosystem now offers a robust and versatile environment for AI and ML development, making it an excellent alternative for those who prefer Java.
Microsoft's Phi-3 series of small language models (SLMs) is gaining popularity due to its amazing capabilities and low cost.
But how do you use this potential in your projects? This article focuses on leveraging Phi-3 with Ollama and Spring AI, a strong combo for developers looking to utilize the capabilities of SLMs in resource-constrained contexts. Its emphasis on safety and high-quality training data promotes responsible growth.
We'll examine how Ollama, a user-friendly framework for deploying machine learning models, simplifies Phi-3 integration. Additionally, Spring AI's expertise in designing and managing ML applications will be discussed, giving a well-rounded way to incorporate Phi-3 into your workflow.
What are SLMs?
SLMs specialize in a given job or topic. They tackle tasks requiring accurate language understanding, such as sentiment analysis, text categorization, and named entity identification.
Consider an SLM a highly skilled archivist capable of methodically sorting and organizing material in a given field.
LLMs aim for wide comprehension and information on a variety of topics. They thrive in open-ended activities, developing unique language structures, and providing complete responses to complicated topics.
SLMs need fewer computing resources and may be used on devices with limited capabilities. This leads to faster training periods and cost-effectiveness.
Pre-requisites
JDK17+
Maven Build Tool
Install and Run Microsoft Phi3 LLM Locally
Make sure to have Ollama installed locally before proceeding. Download and install as per your OS locally.
Phi3 is a family of powerful, small language models (SLMs) with groundbreaking performance at low cost and low latency.
It's very useful for LLMs or so-called SLMs to run locally due to fewer resource requirements. The cutoff date for Phi3 training data is October 2023.
Download and run Phi3 locally via Ollama by running below command
ollama run phi3
This might take based on your network to download around 2.5GB of a model if not downloaded already before running it locally.
Once installed, we can quickly verify if the model is working fine or installed correctly by asking a simple prompt like the below via REST API by executing the below command
curl http://localhost:11434/api/chat -d '{
"model": "phi3",
"messages": [
{
"role": "user",
"content": "why is the sky blue?"
}
],
"stream": false
}'
Response for the above cURL command
{
"model":"phi3",
"created_at":"2024-06-10T07:24:49.2660741Z",
"message":{
"role":"assistant",
"content":" The sky appears blue to us due to a phenomenon called Rayleigh scattering. This process occurs when sunlight enters Earth's atmosphere and interacts with air molecules, which are much smaller than the wavelength of visible light. \n\nSunlight consists of various colors that correspond to different wavelengths (red, orange, yellow, green, blue, indigo, and violet), arranged in a continuous spectrum from one color to another. When sunlight passes through Earth's atmosphere, the shorter-wavelength light (blue and violet) is scattered more than longer-wavelength colors like red or orange due to their smaller size compared to other particles present in the air.\n\nHowever, our eyes are more sensitive to blue light compared to violet, so we perceive the sky as being predominantly blue rather than violet during daylight hours. Additionally, some of the shorter-wavelength light (violet and blue) is absorbed by ozone in Earth's upper atmosphere before it reaches our eyes.\n\nAs a result of Rayleigh scattering, which causes blue light to be scattered more efficiently than other colors, we see the sky as predominantly blue during daytime hours when sunlight passes through our atmosphere. At sunrise and sunset, the angle between the observer's line of sight and the Sun is larger, causing light to pass through a greater thickness of Earth's atmosphere. This results in shorter-wavelength colors being scattered out before they reach our eyes, which makes the sky appear more red or orange during these times."
},
"done_reason":"stop",
"done":true,
"total_duration":9347791300,
"load_duration":2616446700,
"prompt_eval_count":10,
"prompt_eval_duration":82266000,
"eval_count":339,
"eval_duration":6646472000
}
Voila! We can chat with our model Phi3 running locally.
Spring AI - LLM Integration
Let bootstrap Spring Application quickly via Spring IO Initialzr to pull in required dependency as below
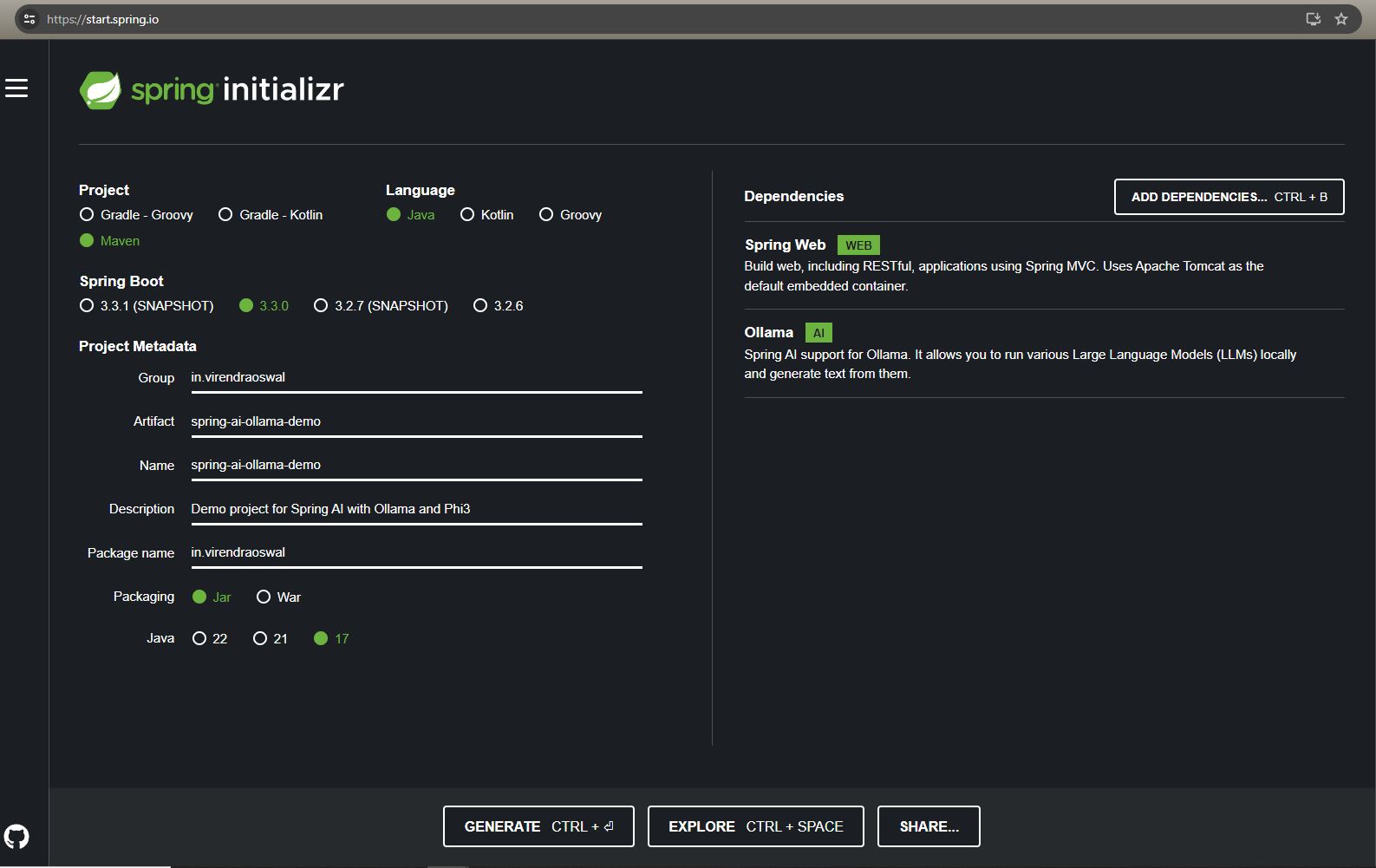
We just need two dependencies for our demonstration
Spring Web Starter: To talk to our LLM Model over HTTP wrapper Spring AI.
Ollama Starter: Client APIs to chat with the model being served via Ollama.
Now the setup is done, we will start talking to our locally running LLM in this case Phi3.
We will use Spring Auto Configuration to bootstrap most of the things, however, we will be using ChatClient API to talk to our model.
The ChatClient offers a fluent API for communicating with an AI Model. It supports both a synchronous and reactive programming model.
We will create ChatClient API using ChatClient.Builder which is autoconfigured via the starter project we added as a dependency earlier in the article.
Most configuration properties can be used with default values but we will override the model to use the property as below
spring.ai.ollama.chat.options.model=phi3
By default, the value of the model is mistral.
If you are hosting Ollama inference API on another port you can update the below property
spring.ai.ollama.base-url=<ollama-host-and-port>
By default, it's set to localhost:11434, which is the default value for Ollama.
This basic bootstrap is enough to talk with our Phi3 model.
Let's make a call to our controller which internally uses the Chat API client to connect to the Phi3 LLM model and return a response
ChatController.java
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
class ChatController {
private final ChatClient chatClient;
public ChatController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@PostMapping("/generate")
String generation(@RequestBody String input) {
return this.chatClient.prompt().user(input).call().content();
}
}
We are basically declaring a POST method that takes user input and chats with the model deployed locally via Ollama and serves the content back to the user.
Now that the application is UP without any issues, let's send a chat request to our model as below. We will be using Postman to send requests in this case
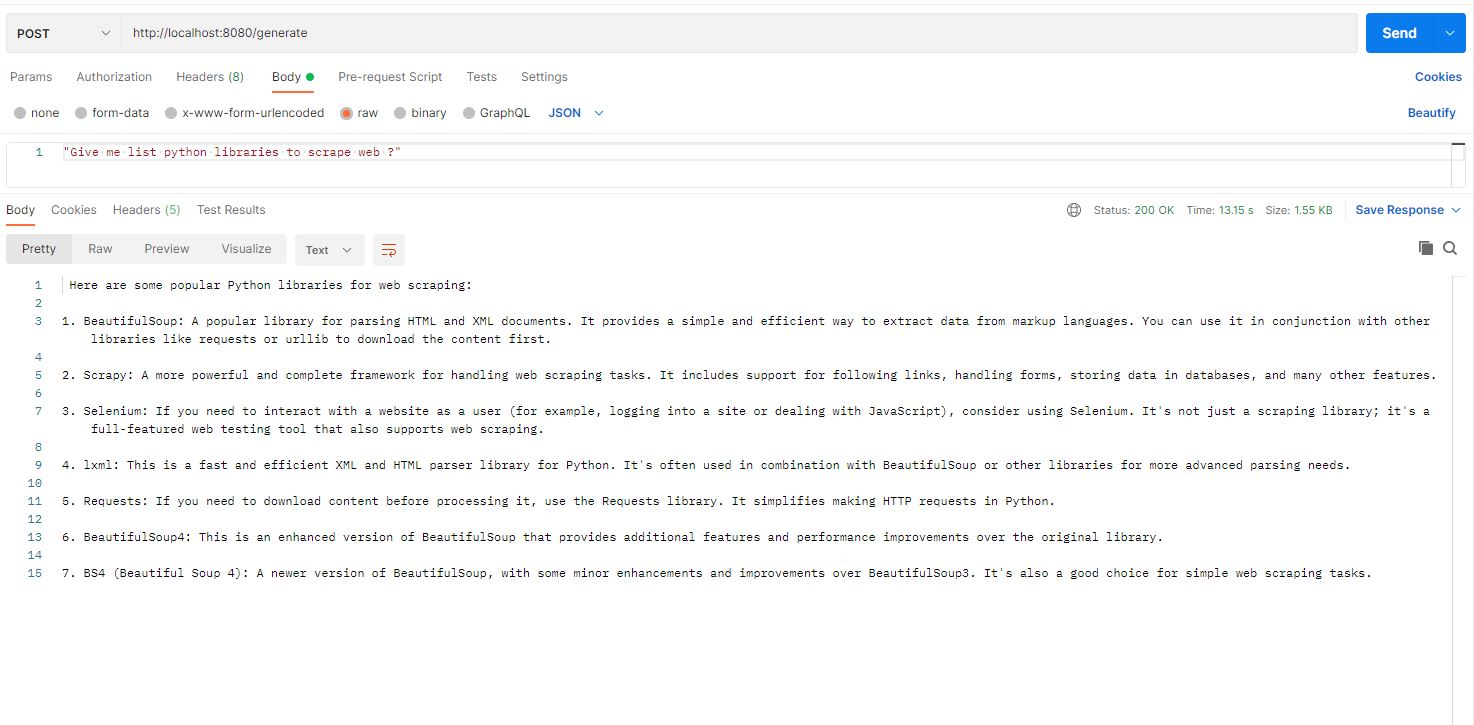
Voila! We can see how if we ask the prompt below we get the proper expected response.
We will try with one more, this time to generate some Python code as below
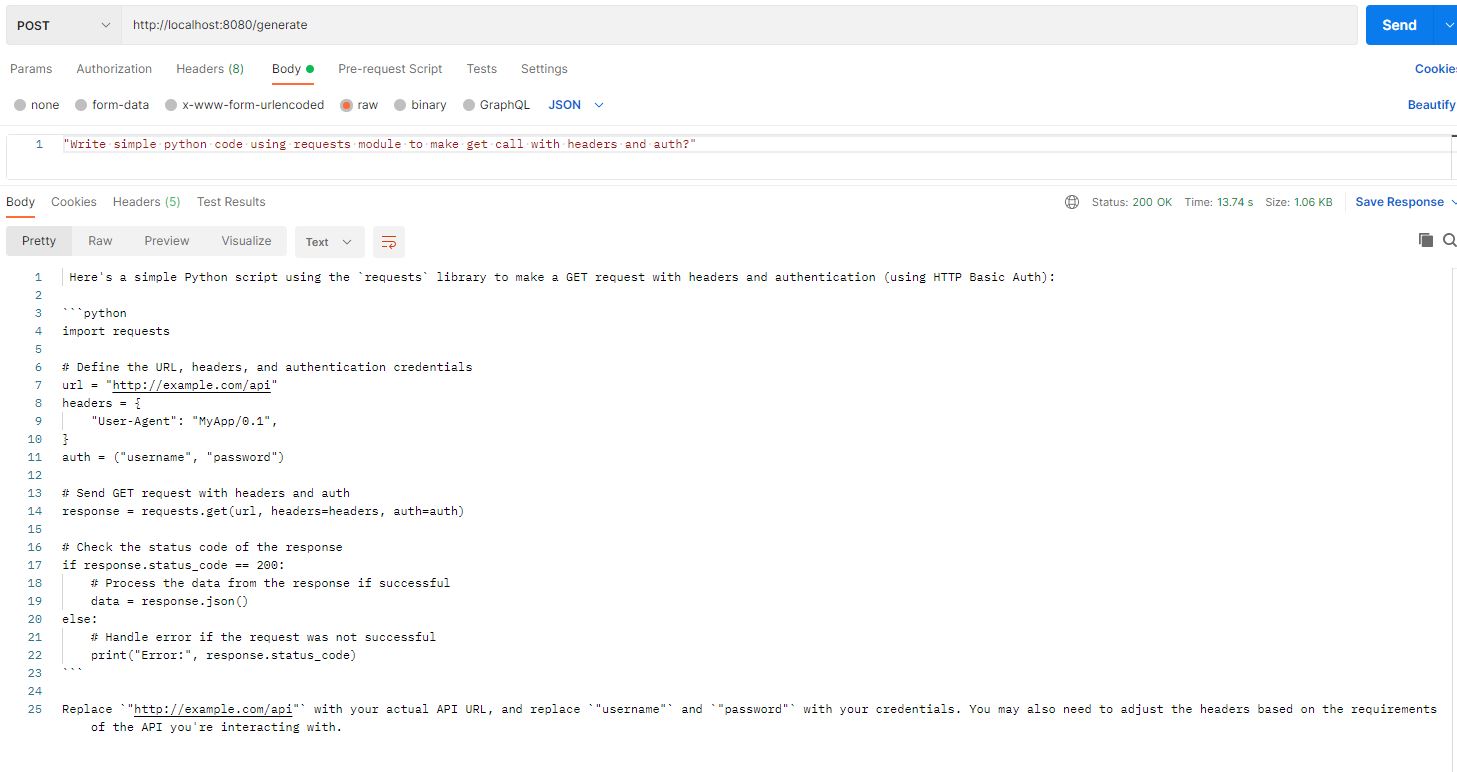
Voila, we are having our own small ChatGPT running locally with no restrictions on API calls or free of cost.
This was a basic example of how to use LLM with Spring ecosystem with Spring AI starter libraries.
In upcoming articles, we will look at how to leverage Prompt Engineering and Retrieval Augmented Generation (RAG) with Spring AI.
Resources
Thank you for reading, If you have reached it so far, please like the article, It will encourage me to write more such articles. Do share your valuable suggestions, I appreciate your honest feedback and suggestions!
Subscribe to my newsletter
Read articles from Virendra Oswal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Virendra Oswal
Virendra Oswal
I am a Full Stack developer, will be posting about development related to all facets of Software Development cycle from Frontend, Backend, Devops. Goal is to share knowledge about Product development in simple ways.