Understanding Recurrent Neural Networks (RNNs)
 Osen Muntu
Osen Muntu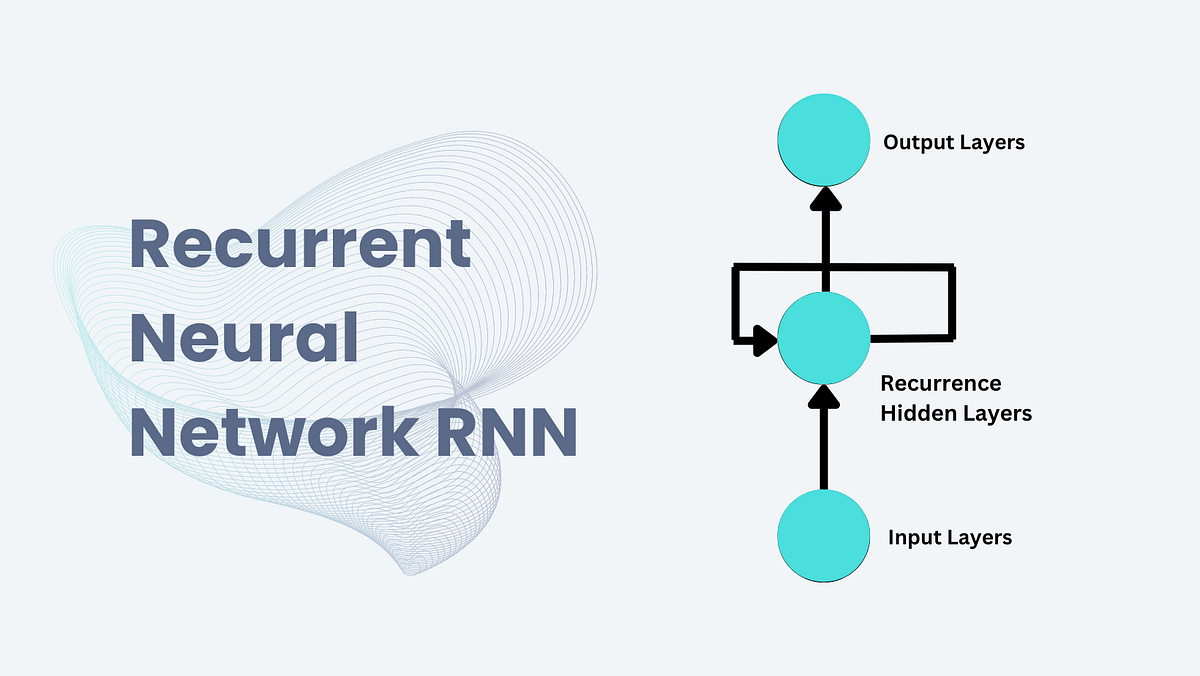
Recurrent Neural Networks (RNNs) are a class of neural networks designed for processing sequential data. Unlike traditional feedforward neural networks (FFNNs), RNNs can handle tasks where the order of data points is important, such as time series analysis and language modeling.
What are Recurrent Neural Networks?
RNNs stand out because of their ability to maintain a 'memory' of previous inputs through recurrent connections among hidden nodes. This feature makes RNNs ideal for handling sequential information.
Key Components and Operation of RNNs
Hidden State
Purpose: The hidden state in an RNN serves as a memory, retaining information from previous inputs in the sequence.
Operation: At each point in the sequence, the hidden state updates itself based on two pieces of information: the current input and the hidden state from the previous time step. This allows the network to keep track of past data while processing new data.
Output
Purpose: The purpose of the output in an RNN is to generate a result at each time step based on the current hidden state.
Operation: The output at each time step is derived from the hidden state at that particular time. This output is then used as the final result for that step in the sequence.
By processing data in this manner, RNNs are well-suited for tasks involving sequential data, where the order and context of the information are crucial for accurate predictions and analysis.
Challenges and Improvements in Training RNNs
Challenges
Training RNNs can be challenging due to issues like vanishing and exploding gradients. These problems arise from the repeated multiplication of gradients during backpropagation through time (BPTT), causing gradients to either shrink to zero (vanish) or grow exponentially (explode).
Improvements: Long Short-Term Memory (LSTM)
To address these issues, Hochreiter and Schmidhuber introduced Long Short-Term Memory (LSTM) networks. LSTMs incorporate memory cells and gates to regulate the flow of information, enabling them to learn long-term dependencies.
Key Components of LSTM
Input Gate:
Purpose: Controls how much of the new information from the current input should be added to the memory cell.
Mathematics:
$$[ i_t = \sigma(W_{ix} x_t + W_{ih} h_{t-1} + b_i) ]$$
Forget Gate:
Purpose: Controls how much of the information from the previous memory cell should be retained.
Mathematics:
$$[ f_t = \sigma(W_{fx} x_t + W_{fh} h_{t-1} + b_f) ]$$
Output Gate:
Purpose: Controls how much of the information in the memory cell should be used to compute the new hidden state.
Mathematics:
$$[ o_t = \sigma(W_{ox} x_t + W_{oh} h_{t-1} + b_o) ]$$
Memory Cell:
Purpose: Maintains information over long sequences.
Mathematics:
$$[ c_t = f_t \odot c_{t-1} + i_t \odot \phi(W_{gx} x_t + W_{gh} h_{t-1} + b_g) ]$$
Hidden State:
Mathematics:
$$[ h_t = o_t \odot \phi(c_t) ]$$
Implementing RNN and LSTM in TensorFlow
RNN Implementation
import tensorflow as tf
from tensorflow.keras import layers, models
def create_rnn(input_shape, num_classes):
model = models.Sequential()
model.add(layers.SimpleRNN(64, activation='relu', input_shape=input_shape))
model.add(layers.Dense(num_classes, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# Example usage with a dummy dataset
import numpy as np
x_train = np.random.rand(1000, 10, 8) # 1000 samples, 10 timesteps, 8 features
y_train = np.random.randint(0, 2, 1000) # 1000 labels (binary classification)
rnn_model = create_rnn((10, 8), 2)
rnn_model.fit(x_train, y_train, epochs=5, batch_size=64)
LSTM Implementation
import tensorflow as tf
from tensorflow.keras import layers, models
def create_lstm(input_shape, num_classes):
model = models.Sequential()
model.add(layers.LSTM(64, activation='relu', input_shape=input_shape))
model.add(layers.Dense(num_classes, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# Example usage with a dummy dataset
import numpy as np
x_train = np.random.rand(1000, 10, 8) # 1000 samples, 10 timesteps, 8 features
y_train = np.random.randint(0, 2, 1000) # 1000 labels (binary classification)
lstm_model = create_lstm((10, 8), 2)
lstm_model.fit(x_train, y_train, epochs=5, batch_size=64)
Use Cases of RNNs
RNNs are widely used in various applications, including but not limited to:
Natural Language Processing (NLP): Tasks such as language modeling, text generation, sentiment analysis, and machine translation.
Time Series Prediction: Forecasting stock prices, weather conditions, and other time-dependent data.
Speech Recognition: Converting spoken language into text.
Music Generation: Creating new music sequences based on learned patterns.
Video Analysis: Understanding and processing sequential video data.
Advances Beyond RNNs
Despite their success, RNNs, including LSTMs, have limitations in capturing long-term dependencies and parallelizing computations. To address these, newer models such as Gated Recurrent Units (GRUs) and Transformer architectures have been developed. Transformers, in particular, have gained popularity due to their ability to handle long-range dependencies and parallelize training, leading to significant improvements in NLP tasks.
Conclusion
RNNs are a powerful class of neural networks for sequential data, providing the foundation for many advancements in deep learning. Their ability to maintain memory of past inputs and adapt to sequential patterns makes them indispensable for various applications in modern AI.
Subscribe to my newsletter
Read articles from Osen Muntu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Osen Muntu
Osen Muntu
Osen Muntu, AI Engineer and Flutter Developer, passionate about artificial intelligence and mobile app development. With expertise in machine learning, deep learning, natural language processing, computer vision, and Flutter, I dedicate myself to building intelligent systems and creating beautiful, functional apps. Through my blog, I share my knowledge and experiences, offering insights into AI trends, development tips, and tutorials to inspire and educate fellow tech enthusiasts. Let's connect and drive innovation together!