Exploring the Best 5 AI Algorithms and Their Applications
 Lakshay Dhoundiyal
Lakshay Dhoundiyal
Artificial Intelligence (AI) is revolutionizing how we interact with technology, making it smarter and more intuitive. This transformation is occurring due to these powerful algorithms that enable machines to learn from data and make informed decisions. In this blog, we will explore the top 5 AI algorithms that are shaping various industries today including their practical applications and easy-to-understand code examples to demonstrate how these algorithms work in real-world scenarios.
Linear Regression
Linear regression is a simple yet powerful algorithm used for predicting numerical values. For example, it can predict housing prices based on features like size, location, and number of bedrooms.
Below is the Example Code :
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Sample data: Size of house (in square feet) and price (in $1000s)
X = np.array([[1400], [1600], [1700], [1875], [1100], [1550], [2350], [2450], [1425], [1700]])
y = np.array([245, 312, 279, 308, 199, 219, 405, 324, 319, 255])
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Plot the results
plt.scatter(X, y, color='blue')
plt.plot(X, model.predict(X), color='red')
plt.xlabel('Size of House (square feet)')
plt.ylabel('Price ($1000s)')
plt.title('House Prices Prediction using Linear Regression')
plt.show()
Output :
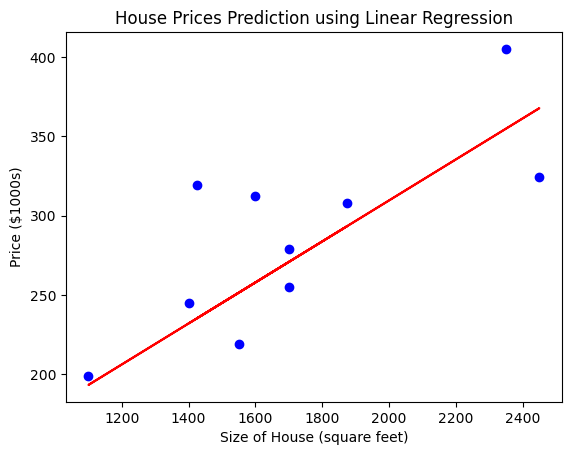
Applications :
Business & Finance: Sales forecasting, stock market analysis, customer lifetime value prediction.
Science & Engineering: Medical diagnosis, scientific research, engineering design.
Social Sciences & Education: Academic performance prediction, social science research.
Other Applications: Real estate price prediction, weather forecasting, climate change analysis.
Decision Trees
Decision trees are used for both classification and regression tasks. They are particularly useful for segmenting customers based on their characteristics to target marketing efforts.
Below is the Example Code :
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
from sklearn import tree
# Sample data: Features (age, income, gender) and target (segment)
data = {'Age': [25, 45, 35, 50, 23, 44, 36, 52, 48, 34],
'Income': [50000, 100000, 75000, 120000, 40000, 110000, 75000, 130000, 90000, 65000],
'Gender': [0, 1, 0, 1, 0, 1, 0, 1, 1, 0],
'Segment': [1, 0, 1, 0, 1, 0, 1, 0, 0, 1]}
df = pd.DataFrame(data)
X = df[['Age', 'Income', 'Gender']]
y = df['Segment']
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train the model
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
print(classification_report(y_test, y_pred))
# Plot the tree
plt.figure(figsize=(12,8))
tree.plot_tree(model, feature_names=['Age', 'Income', 'Gender'], class_names=['Segment 0', 'Segment 1'], filled=True)
plt.show()
Output :
![A decision tree diagram with a root node labeled "Gender <= 0.5" with gini = 0.469, samples = 8, value = [3, 5], and class = Segment 1. It splits into two child nodes: the left child node with gini = 0.0, samples = 5, value = [0, 5], and class = Segment 1, and the right child node with gini = 0.0, samples = 3, value = [3, 0], and class = Segment 0.](https://cdn.hashnode.com/res/hashnode/image/upload/v1718176785658/1875bd6b-9126-4a32-9d64-5641454c453a.png)
Applications :
Finance: Loan approval, fraud detection
Healthcare: Disease diagnosis support, treatment recommendation suggestions
Marketing: Customer segmentation, customer churn prediction
Retail: Product recommendation, inventory management optimization
Cybersecurity: Threat detection
Law Enforcement: Crime prediction
K-Means Clustering
K-Means clustering is a popular unsupervised learning algorithm used for grouping similar data points. In image compression, it reduces the number of colors in an image.
Below is the Example Code :
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from skimage import io
# Load the image
image = io.imread('path_to_image.jpg')
image = image / 255.0 # Normalize to 0-1 range
# Reshape the image to a 2D array of pixels
pixels = image.reshape(-1, 3)
# Apply K-Means clustering
kmeans = KMeans(n_clusters=16)
kmeans.fit(pixels)
new_colors = kmeans.cluster_centers_[kmeans.labels_]
# Reshape the result back to the original image shape
compressed_image = new_colors.reshape(image.shape)
# Display the compressed image
plt.imshow(compressed_image)
plt.title('Compressed Image with K-Means Clustering')
plt.show()
Output :
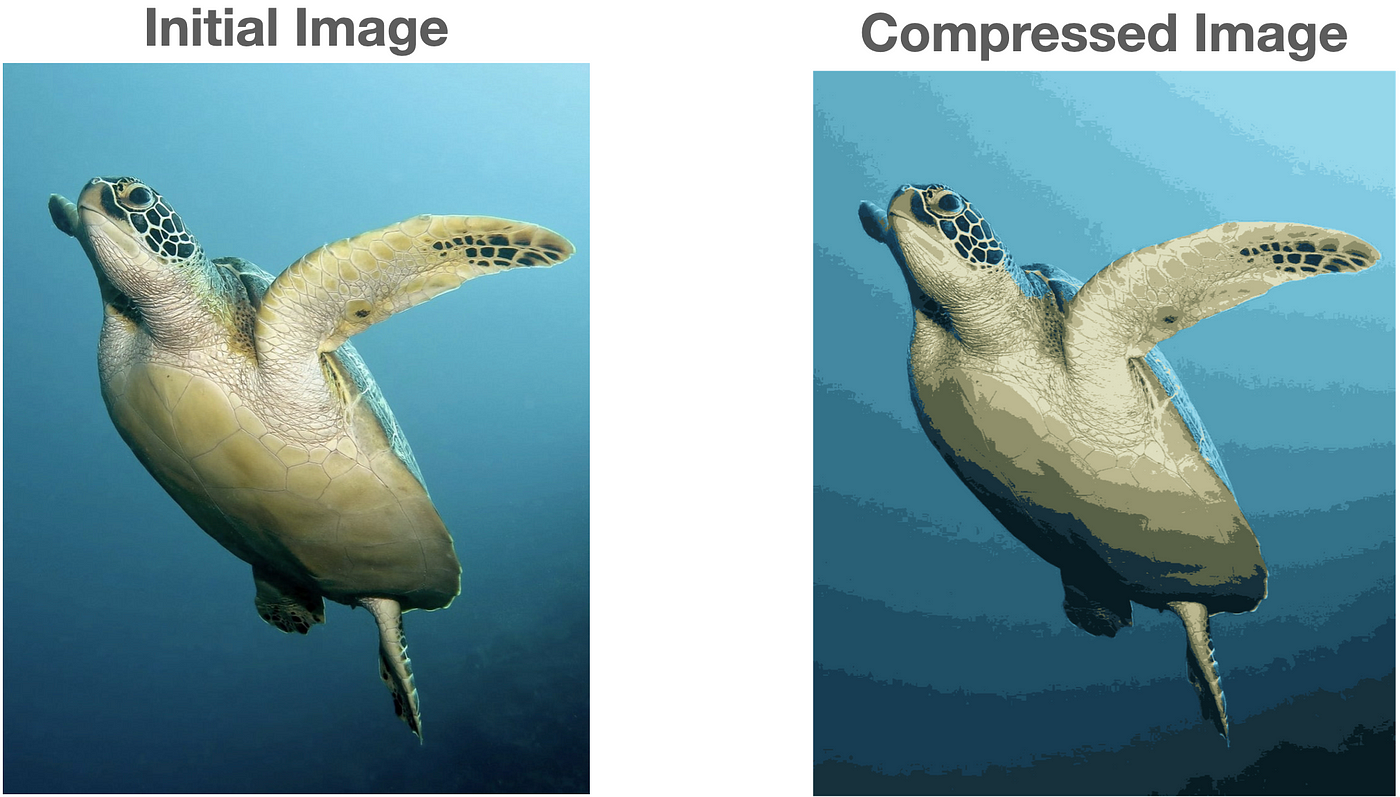
Applications :
Image Segmentation: Segment images into meaningful regions, like separating foreground objects from the background in a photo.
Document Clustering: Group documents with similar topics or themes for efficient information retrieval and analysis.
Market Research: Identify clusters of consumers with similar preferences to understand market trends and target specific demographics.
Anomaly Detection: Detect data points that fall outside of expected clusters, which might indicate fraudulent activity or outliers in sensor data.
Gene Expression Analysis: Cluster genes with similar expression patterns to understand biological processes and identify potential drug targets.
Recommendation Systems: Group users with similar preferences to recommend products, movies, or music they might enjoy.
Social Network Analysis: Identify communities within social networks based on user interactions and connections.
Support Vector Machines (SVM)
Support Vector Machines are powerful for classification tasks. They are widely used in text classification problems like detecting spam emails.
Below is the Example Code :
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
# Sample data: Emails and labels (spam or not spam)
emails = ["Free money!!!", "Hi, how are you?", "Win a new car now!", "Let's schedule a meeting.", "Cheap meds online!"]
labels = [1, 0, 1, 0, 1]
# Convert text data to TF-IDF features
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(emails)
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2, random_state=42)
# Train the model
model = SVC()
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluate the model
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
print(classification_report(y_test, y_pred))
Output :
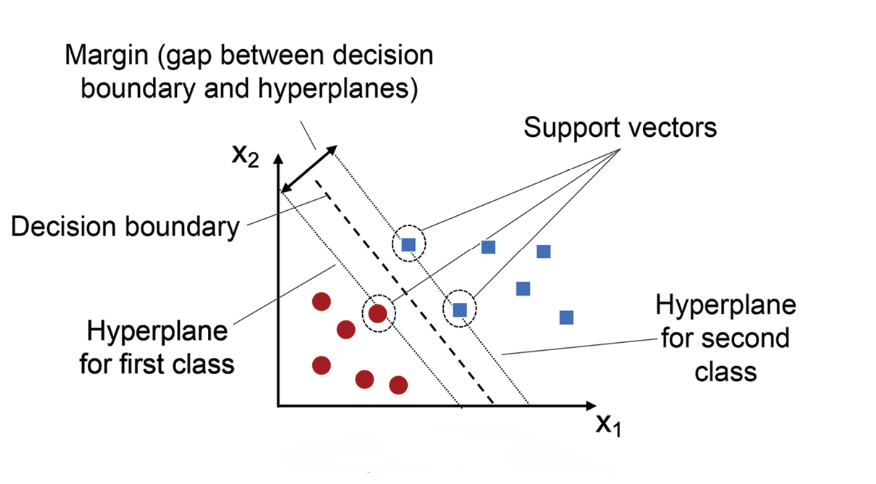
Applications :
SVMs detect fraudulent credit card transactions, protecting financial systems.
SVMs analyze handwriting samples for accurate character recognition.
SVMs identify tumors in medical scans for early disease detection.
SVMs classify sentiment in text analysis, gauging audience opinions.
SVMs predict stock market trends to inform investment decisions.
Neural Networks
Neural networks, especially deep learning models, excel at recognizing patterns in complex data. They are the backbone of image and speech recognition systems.
Below is the Example Code :
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.utils import to_categorical
# Load the dataset
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# Preprocess the data
X_train = X_train / 255.0
X_test = X_test / 255.0
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# Build the model
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
# Compile the model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(X_train, y_train, epochs=5, batch_size=32, validation_split=0.2)
# Evaluate the model
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Accuracy: {accuracy}")
# Predict on a sample
sample = X_test[0].reshape(1, 28, 28)
prediction = model.predict(sample)
print(f"Predicted digit: {prediction.argmax()}")
Output :
Applications :
Neural networks power self-driving cars by recognizing objects and navigating roads.
It translates languages in real time, breaking down communication barriers.
It generates realistic images and art, pushing the boundaries of creativity.
It personalizes search results based on user history and preferences.
It recommends products you might like, influencing online shopping experiences.
It composes music that mimics different styles and genres.
It analyzes stock markets to predict future trends, though not a guaranteed forecast.
Neural networks create chatbots that answer questions and simulate conversations.
AI algorithms are the building blocks of modern intelligent systems. From predicting housing prices with Linear Regression to recognizing handwritten digits with Neural Networks, these algorithms have diverse applications that improve our daily lives and drive innovation across sectors. Understanding these algorithms and how to implement them is crucial for leveraging the full potential of AI. As technology continues to evolve, staying informed about the foundational tools will empower you to create more effective and efficient solutions.
Subscribe to my newsletter
Read articles from Lakshay Dhoundiyal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Lakshay Dhoundiyal
Lakshay Dhoundiyal
Being an Electronics graduate and an India Book of Records holder, I bring a unique blend of expertise to the tech realm. My passion lies in full-stack development and ethical hacking, where I continuously strive to innovate and secure digital landscapes. At Hashnode, I aim to share my insights, experiences, and discoveries through tech blogs.