Docker Volumes
 Haaris Sayyed
Haaris Sayyed
Introduction
By default all files created inside a container are stored on a writable container layer. This means that:
The data doesn't persist when that container no longer exists, and it can be difficult to get the data out of the container if another process needs it.
A container's writable layer is tightly coupled to the host machine where the container is running. You can't easily move the data somewhere else.
Writing into a container's writable layer requires a storage driver to manage the filesystem. The storage driver provides a union filesystem, using the Linux kernel. This extra abstraction reduces performance as compared to using data volumes, which write directly to the host filesystem.
Docker has two options for containers to store files on the host machine, so that the files are persisted even after the container stops: volumes, and bind mounts.
An easy way to visualize the difference among volumes and bind mounts is to think about where the data lives on the Docker host.
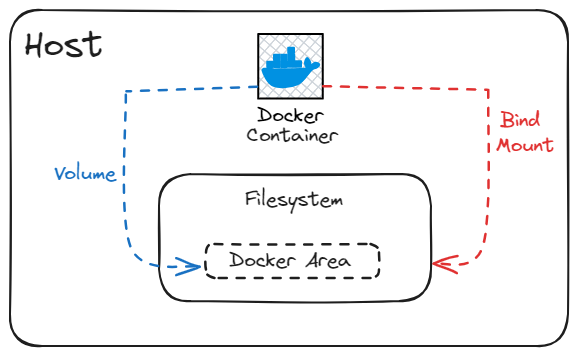
Volumes are stored in a part of the host filesystem which is managed by Docker (
/var/lib/docker/volumes/on Linux). Non-Docker processes should not modify this part of the filesystem. Volumes are the best way to persist data in Docker.Bind mounts may be stored anywhere on the host system. They may even be important system files or directories. Non-Docker processes on the Docker host or a Docker container can modify them at any time.
Docker Volumes
Docker Volumes are a mechanism to persist data generated and used by Docker containers. While Docker containers are ephemeral by nature, meaning they are designed to be transient and easily recreated, Docker Volumes provide a way to retain data outside the container’s lifecycle. This ensures that data is not lost when containers are stopped, removed, or recreated.
When you create a volume, it's stored within a directory on the Docker host. When you mount the volume into a container, this directory is what's mounted into the container. This is similar to the way that bind mounts work, except that volumes are managed by Docker and are isolated from the core functionality of the host machine.
Types of Docker Volumes
Named Volumes: These volumes are managed by Docker and can be shared and reused among multiple containers. They are created and named by the user and are stored in a default location managed by Docker.
Anonymous Volumes: These are similar to named volumes but are not explicitly named by the user. They are useful for temporary storage that is still persisted beyond the container's life but does not need to be referenced by name.
Host Volumes (Bind Mounts): These volumes map a specific directory or file on the host system to a directory or file in the container. This provides direct access to the host’s filesystem and is useful for scenarios where you need to share code or configuration files between the host and the container.
Why Use Docker Volumes?
1. Persistence of Data
The most compelling reason to use Docker Volumes is data persistence. When a container is removed, any data stored within the container’s filesystem is lost. By using volumes, data can be stored persistently and be made available across container restarts and recreations.
2. Data Sharing
Volumes allow for easy data sharing between containers. For instance, if you have multiple containers that need access to the same data, you can mount the same volume to all of them, facilitating seamless data sharing.
3. Separation of Concerns
Volumes enable a clear separation between the application’s code and its data. This separation allows developers to focus on building and running the application without worrying about data management. It also simplifies backups and data migration processes.
4. Performance
Docker Volumes offer better performance compared to bind mounts. Volumes are managed by Docker and are optimized for use with containers, often leading to improved I/O performance. Additionally, Docker volumes can be stored on different storage backends, providing flexibility in performance tuning.
5. Portability
Using volumes enhances the portability of your containers. When you move containers between different environments (e.g., development, testing, production), volumes can help ensure that the necessary data moves with them, maintaining consistency across these environments.
How to Use Docker Volumes
Creating and Using Named Volumes
To create a named volume, use the following command:

To use this volume in a container, you can mount it using the -v or --mount flag:

Using Anonymous Volumes
You can create an anonymous volume by simply specifying a path without a name:

Using Host Volumes
To bind mount a host directory to a container, use the following command:

Inspecting Volumes
To inspect a volume and get detailed information about it, use:

Removing Volumes
To remove a volume that is no longer needed, use:

Best Practices for Using Docker Volumes
Use Named Volumes for Persistent Data: For data that needs to persist beyond the life of a container, always use named volumes.
Avoid Storing Sensitive Data: Be cautious about storing sensitive data in volumes, especially if you are using host volumes. Ensure proper access controls and encryption.
Regular Backups: Regularly back up your volumes, especially for critical data. Docker does not provide native backup tools, so use external tools or scripts to handle this.
Monitor Volume Usage: Keep an eye on the disk usage of your volumes to avoid running out of space, which can lead to application failures.
Using Docker Volumes with a Simple Ubuntu Image Container
Scenario
You want to run a simple Ubuntu container and ensure that some data generated inside the container is persisted even if the container stops or is removed. This can be useful for various tasks, such as development, testing, or running scripts that generate important output files.
Objectives
Persist Data: Ensure that data created inside the Ubuntu container is persisted.
Enable Data Sharing: Allow easy sharing of data between the host and the container.
Steps
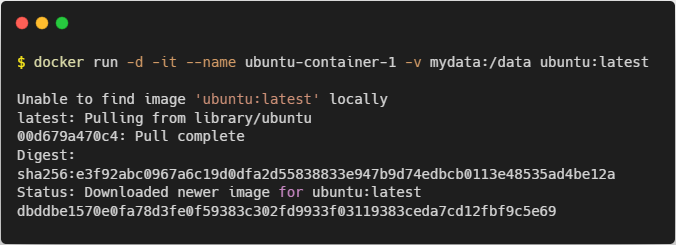
1. Create and Run the Container with a Volume
2. Use the Container
Execute commands inside the running Ubuntu container to create some data in the /data directory:

Once inside the container, create a file in the /data directory:

Exit the container:

3. Verify Data Persistence
To verify that data is persisted:
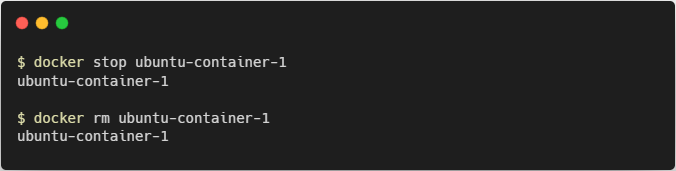
Stop and remove the Ubuntu container:
Recreate another container and run with the same volume:

Check the contents of the
/datadirectory to verify that the data persists:
We can see that we are getting the file contents that we generated and persisted using first container which indicates that volumes enables data storage and data sharing among different containers.
Conclusion
Docker Volumes are a powerful feature that brings flexibility and resilience to containerized applications. By understanding and effectively using volumes, you can ensure data persistence, enhance performance, and facilitate easier data management. Whether you’re running a single container or orchestrating a complex microservices architecture, Docker Volumes are an indispensable tool in your Docker toolkit.
Subscribe to my newsletter
Read articles from Haaris Sayyed directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by