Real-world ML: Contrastive Learning, The Power of Grasping the Data Essence
 Juan Carlos Olamendy
Juan Carlos Olamendy
Imagine trying to identify a rare disease with just a few x-ray images. The high cost of labeling and the scarcity of data make this task daunting.
I got you! I faced a similar situation trying to train a model for anomaly detection.
Now, picture a model that can not only grasp the subtle differences between healthy and diseased tissues but also enhance its accuracy over time without needing vast amounts of labeled data.
Welcome to the world of contrastive learning.
This method taps into the essence of what makes things similar or different, transforming the way we solve problems in fields like computer vision and natural language processing.
By the end of this article, you'll understand how contrastive learning works and see the code for real world example that you can adapt to your own scenario.
Keep reading to discover the secrets behind this powerful AI technique and how it can elevate your machine learning models to new heights.
Understanding Contrastive Learning
Contrastive learning aims to learn useful representations of data by leveraging the inherent similarities and differences between samples.
The core idea is simple yet powerful: similar data points (positive pairs) should be closer together in the representation space, while dissimilar points (negative pairs) should be farther apart.
By doing so, the model learns to capture the essential features and patterns that distinguish different types of data, allowing it to generalize well to new, unseen examples.
The Key Components of Contrastive Learning
To understand how contrastive learning works, let's break it down into its key components:
Similarity and Dissimilarity
At the heart of contrastive learning lies the notion of similarity and dissimilarity.
Positive pairs consist of similar data points, while negative pairs comprise dissimilar ones.
The model learns to distinguish between these pairs and adjusts the representations accordingly.
The goal of contrastive learning is to learn a representation space where positive pairs are close together, and negative pairs are far apart.
This process involves defining a contrastive loss function that minimizes the distance between positive pairs and maximizes the distance between negative pairs.
Contrastive Loss Function
The contrastive loss function is crucial for the success of contrastive learning.
This function measures the difference between the representations of positive and negative pairs.
Common forms of contrastive loss include the InfoNCE loss, used in methods like SimCLR and MoCo.
By optimizing this loss function, the model learns to bring similar data points closer and push dissimilar ones apart.
Representation Learning
One of the primary goals of contrastive learning is to learn useful representations of the input data.
By optimizing the contrastive loss, the model captures essential features and patterns that distinguish similar data points from dissimilar ones.
These learned representations can be used for various downstream tasks, such as classification, clustering, and retrieval.
In essence, contrastive learning transforms raw data into a high-dimensional space where relationships between data points are preserved meaningfully.
Encoder Architecture
The encoder architecture in contrastive learning maps the input data to a lower-dimensional representation space.
This encoder can be a deep neural network, such as a convolutional neural network (CNN) for images or a transformer for sequences.
The encoder is trained to extract meaningful features from the input data, playing a crucial role in the success of contrastive learning.
Contrastive Learning in Action
To see contrastive learning in action, let's consider a few examples:
Example 1: Image Recognition for Wildlife Monitoring
Suppose we have a wildlife monitoring system that aims to identify and classify different species of animals captured in camera trap images.
We can use contrastive learning to learn rich representations of these images.
To create positive pairs, we can use different images of the same species, ensuring that the model learns to recognize the essential features that define each species.
For negative pairs, we can use images of different species, allowing the model to learn the distinctions between them.
By optimizing the contrastive loss function, the model will learn a representation space where images of the same species are clustered together, and images of different species are well-separated.
Example 2: Audio Processing for Speaker Verification
In the context of speaker verification, the goal is to confirm a speaker's identity based on their voice.
Contrastive learning can be applied to learn robust representations of speaker voices.
Positive pairs can be created using different audio clips from the same speaker, while negative pairs can be formed using clips from different speakers.
By training the model with a contrastive loss function, it will learn to capture the unique characteristics of each speaker's voice, enabling accurate speaker verification.
Example 3: Text Analysis for Paraphrase Detection
Contrastive learning can also be applied to natural language processing tasks, such as paraphrase detection, where the goal is to identify sentences that convey the same meaning.
Positive pairs can be created using different paraphrases of the same sentence, while negative pairs can be formed using sentences with different meanings.
The model will learn to map paraphrases to similar representations in the learned space, making it easier to detect them.
The Power of Contrastive Learning
Contrastive learning has several advantages that make it a powerful tool in machine learning:
Unsupervised Learning: Contrastive learning can be applied in an unsupervised setting, where the model learns from unlabeled data. This is particularly useful when labeled data is scarce or expensive to obtain.
Generalization: By learning meaningful representations, contrastive learning models can generalize well to new, unseen data. The learned features capture the underlying patterns and structures of the data, rather than memorizing specific examples.
Transferability: The representations learned through contrastive learning can be transferred to various downstream tasks. This means that a model trained on a large, diverse dataset can be fine-tuned for specific applications with minimal additional training.
Robustness: Contrastive learning models are often more robust to noise and variations in the input data. By focusing on the similarities and differences between samples, the model learns to ignore irrelevant details and capture the essential features.
Challenges and Considerations
While contrastive learning is a powerful technique, there are some challenges and considerations to keep in mind:
Negative Pair Selection: The choice of negative pairs is crucial for the success of contrastive learning. Selecting informative and diverse negative pairs can improve the model's performance, while poor selection can lead to suboptimal results.
Computational Cost: Contrastive learning often requires training on large datasets and can be computationally expensive, especially when dealing with high-dimensional data like images or videos.
Hyperparameter Tuning: The performance of contrastive learning models can be sensitive to hyperparameters such as the temperature in the contrastive loss function, the batch size, and the learning rate. Careful tuning is necessary to achieve optimal results.
Implementation Example
Let's classify digits from the MNIST dataset.
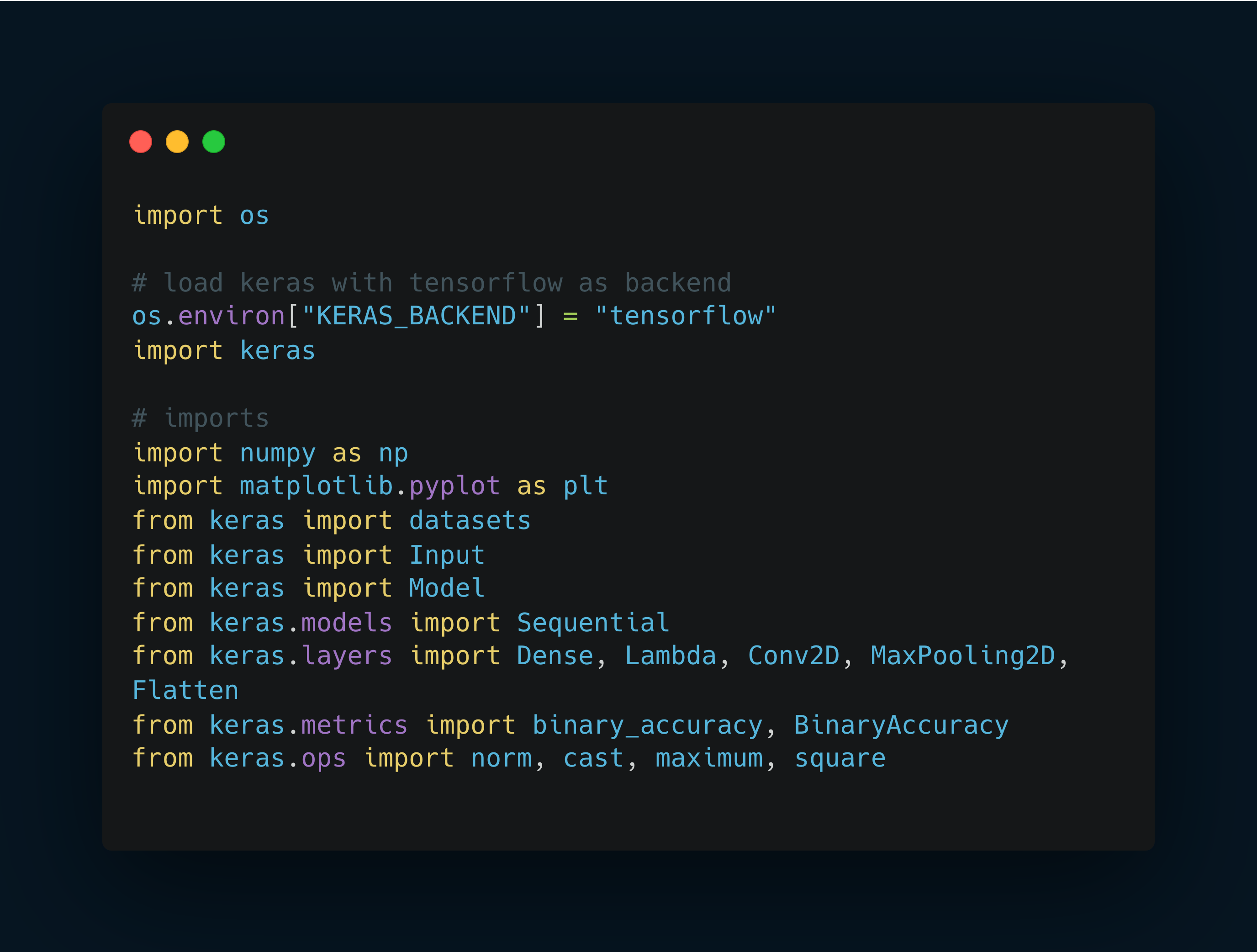
Set up the environment
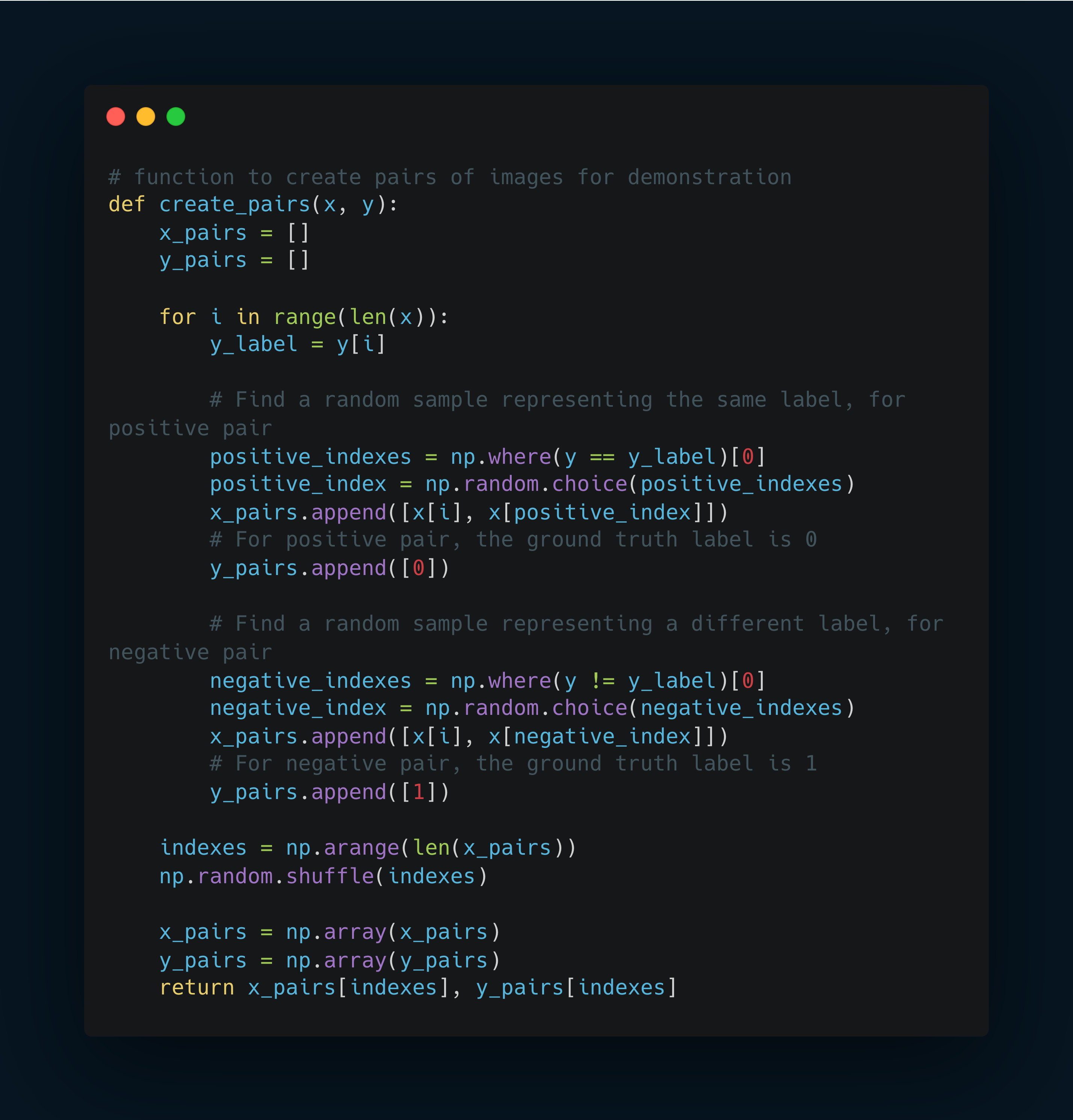
Define the function that generated pairs
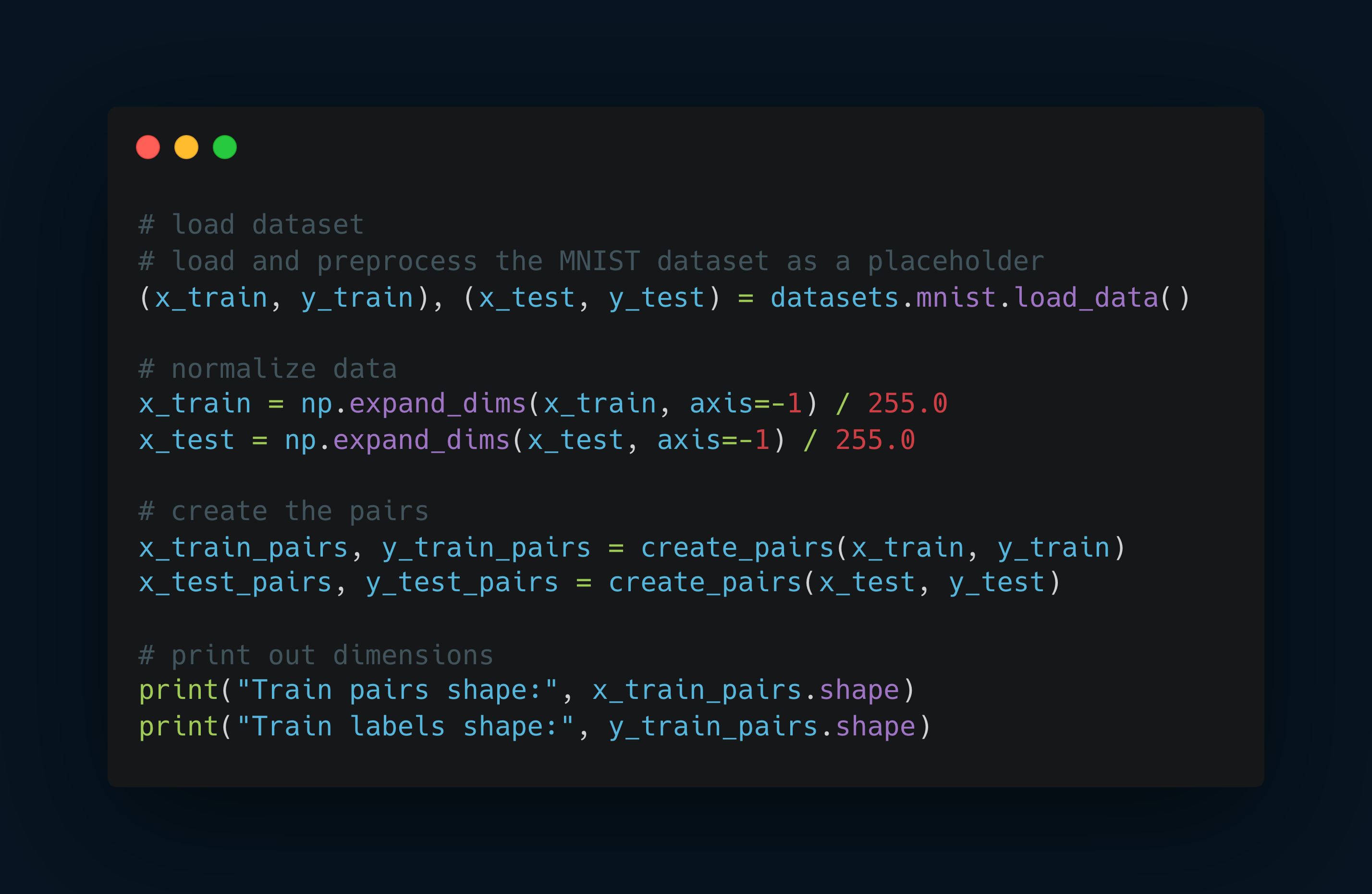
Loading and Preprocessing Data
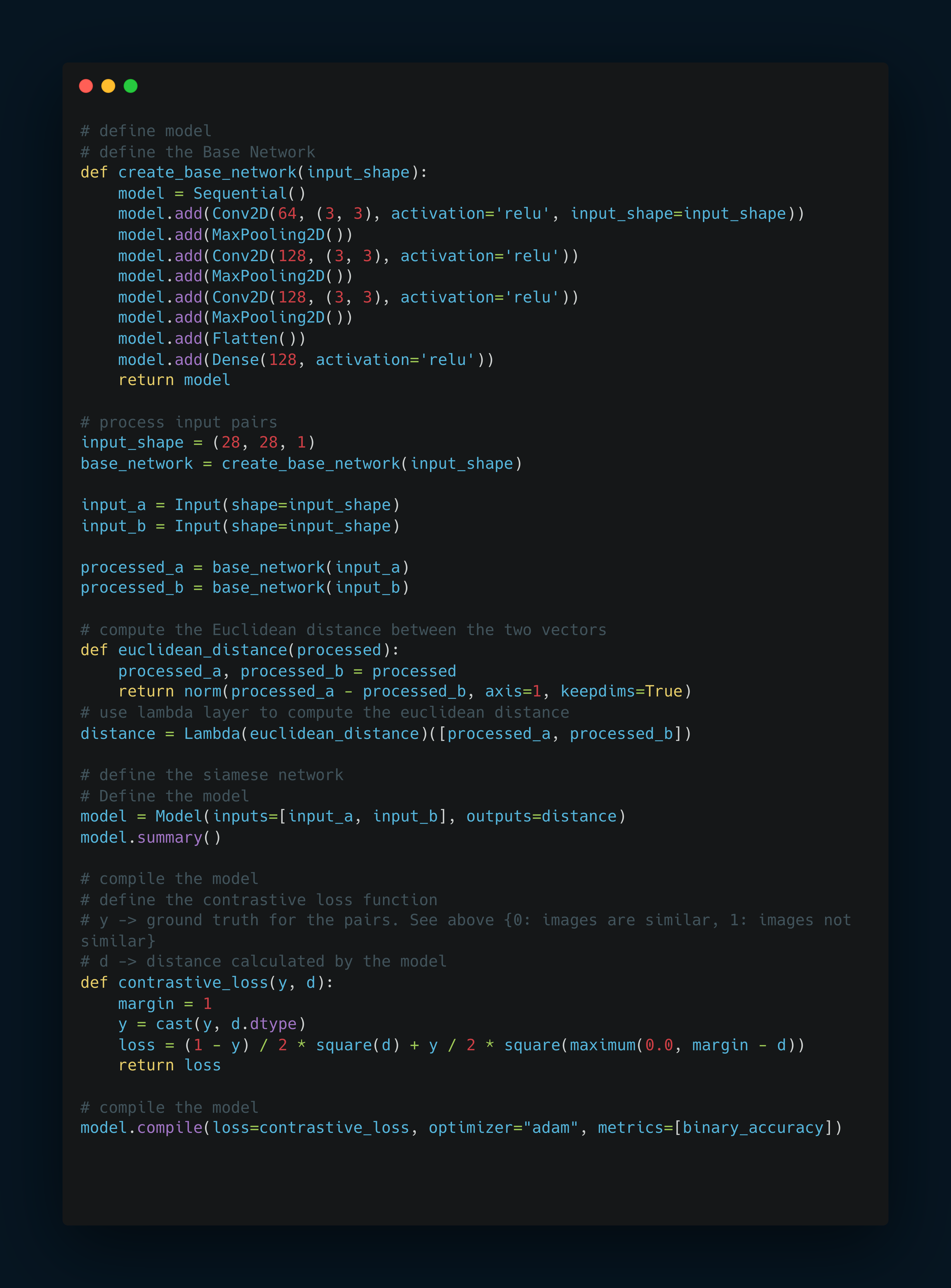
Define the Siamese network
Train the model
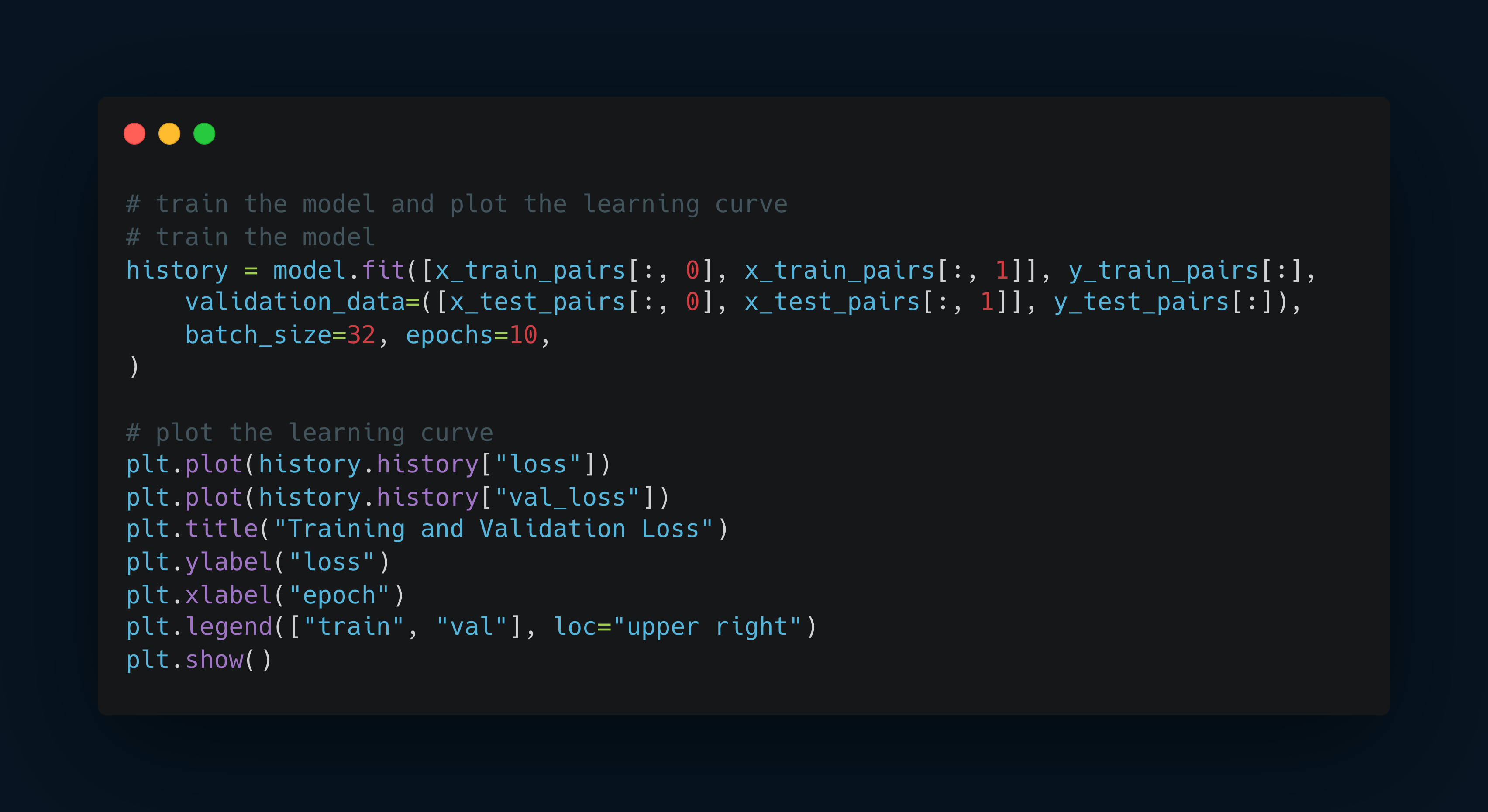
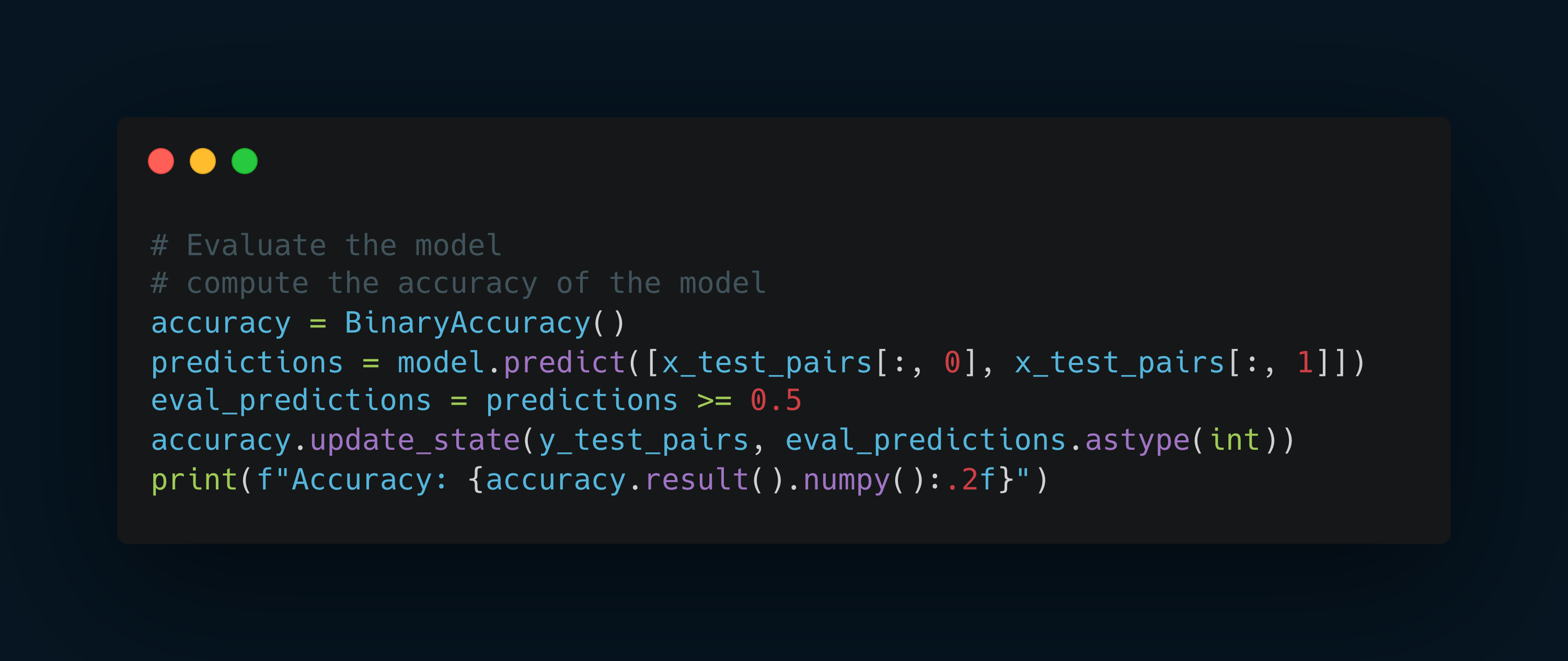
Evaluate the model
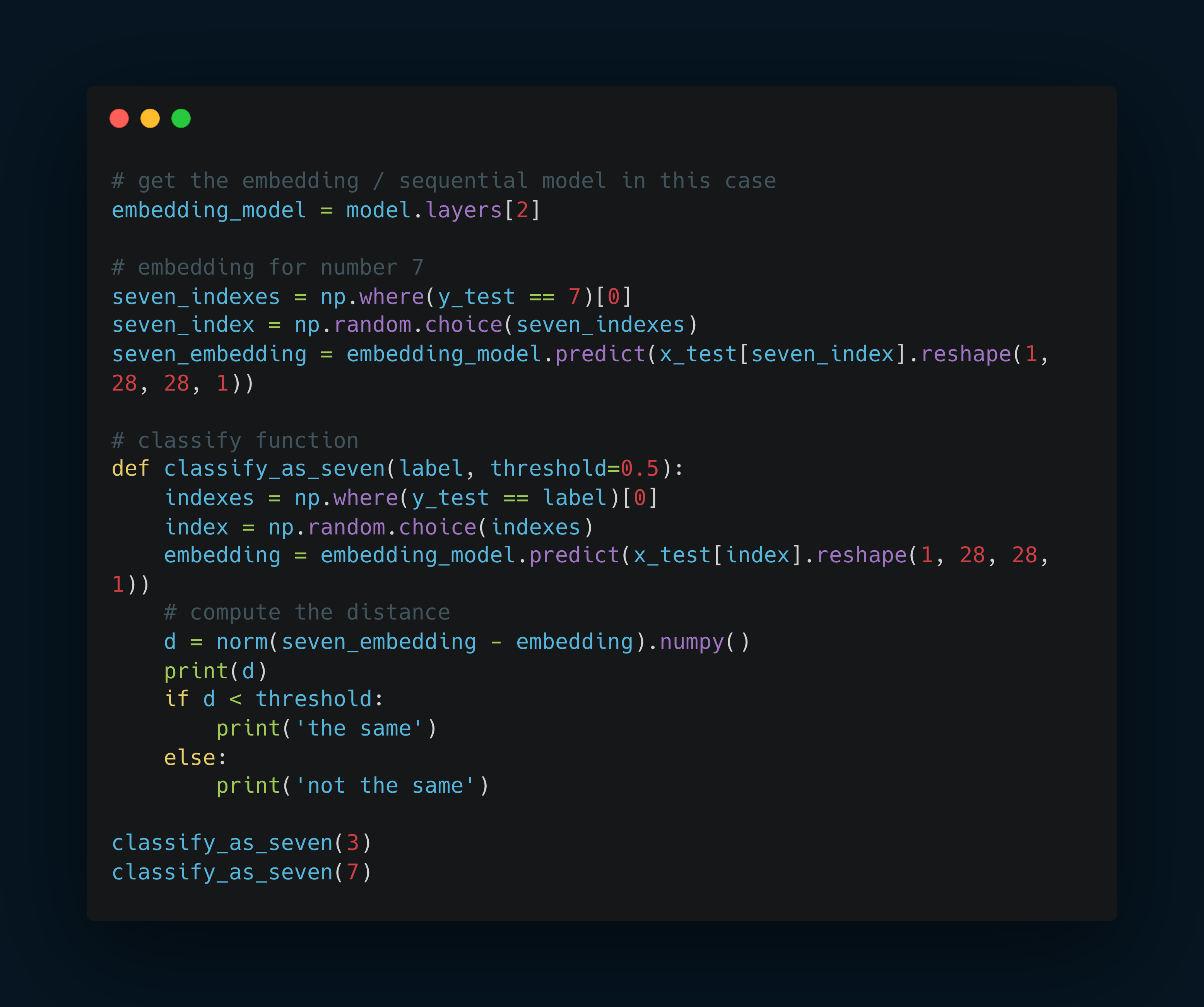
Compute the embedding and do classification
Conclusion
Contrastive learning is a powerful technique that is transforming the way we approach ML problems.
By learning meaningful representations based on the similarities and differences between samples, contrastive learning enables models to capture the essence of the data and generalize well to new, unseen examples.
From image recognition to speaker verification and anomaly detection, contrastive learning has shown promising results across various domains.
As research in this area continues to advance, we can expect to see even more exciting applications and breakthroughs in the future.
So, the next time you encounter a ML problem, consider the power of contrastive learning and how it can help you unlock the hidden patterns and structures in your data.
Embrace the similarities, explore the differences, and let contrastive learning guide you towards more accurate, robust, and generalizable models.
PR: If you like this article, share it with others ♻️
Would help a lot ❤️
And feel free to follow me for articles more like this.
Subscribe to my newsletter
Read articles from Juan Carlos Olamendy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Juan Carlos Olamendy
Juan Carlos Olamendy
🤖 Talk about AI/ML · AI-preneur 🛠️ Build AI tools 🚀 Share my journey 𓀙 🔗 http://pixela.io