Understanding Long Short-Term Memory (LSTM) Networks
 Osen Muntu
Osen Muntu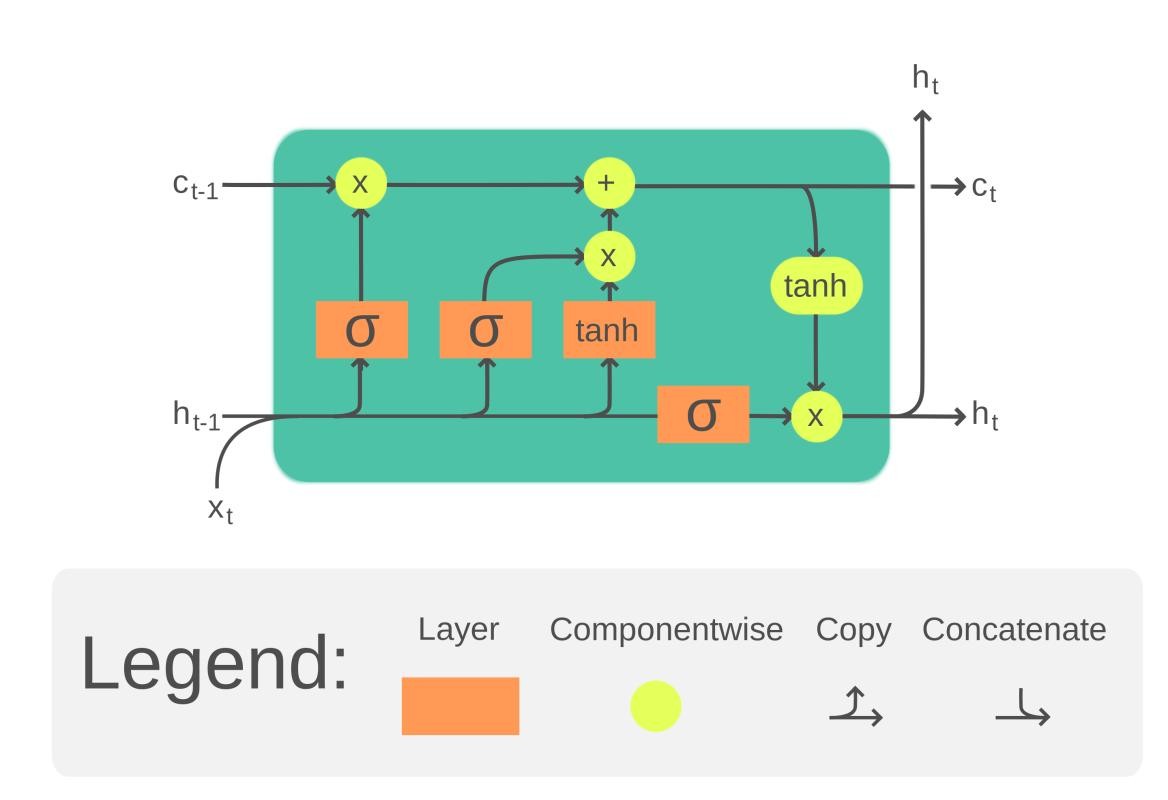
Long Short-Term Memory (LSTM) networks are a type of recurrent neural network (RNN) specifically designed to model and predict sequential data. Unlike traditional RNNs, LSTMs are capable of learning long-term dependencies, making them particularly effective for tasks such as language translation, speech recognition, and time series forecasting. This article delves into the LSTM model, its architecture, how it differs from standard RNNs, its various applications, and provides a guide for implementation in TensorFlow.
What is LSTM?
LSTMs were developed by Hochreiter and Schmidhuber to address the limitations of traditional RNNs, particularly the difficulty in learning long-term dependencies due to issues like the vanishing gradient problem. LSTMs introduce a memory cell that can maintain information over extended periods, allowing the network to remember important details from earlier in the sequence.
Key Components of LSTM
LSTMs are composed of a series of gates that manage the flow of information into and out of the memory cell. These gates include:
Input Gate: Controls the information added to the memory cell.
Forget Gate: Decides what information to discard from the memory cell.
Output Gate: Determines what information is output from the memory cell.
This gating mechanism enables LSTMs to retain, discard, or output information selectively, which is crucial for learning long-term dependencies in data.
LSTM Architecture
The LSTM architecture revolves around its memory cell and three crucial gates:
Forget Gate: It filters the information that is no longer needed, effectively forgetting irrelevant data. It takes the previous hidden state and the current input to decide what to forget.
Input Gate: It regulates the addition of new information to the memory cell. This gate filters the values to be remembered and updates the cell state with new data.
Output Gate: It extracts useful information from the current cell state to generate the output. The gate decides what part of the cell state should be output and what should be retained for future use.
Each gate works with a sigmoid function that outputs values between 0 and 1, controlling the degree to which information is passed through.
Bidirectional LSTM
A Bidirectional LSTM (BiLSTM) processes data in both forward and backward directions, providing a richer understanding of the context. This is especially useful in applications like language translation and speech recognition, where understanding the full context is crucial.
- BiLSTM consists of two LSTM networks: one processes the input sequence from start to end, and the other processes it from end to start. The outputs of these two networks are then combined.
How LSTMs Differ from RNNs
Memory Handling:
RNNs: Have a single hidden state that captures information from the previous steps but struggle with long-term dependencies.
LSTMs: Introduce a memory cell that retains information over long periods, controlled by input, forget, and output gates.
Training:
RNNs: Easier to train but suffer from vanishing or exploding gradients.
LSTMs: More complex due to the gating mechanisms but are designed to mitigate the vanishing gradient problem, making them better at capturing long-term dependencies.
Performance:
RNNs: Effective for short-term dependencies and simpler tasks.
LSTMs: Superior in tasks requiring long-term context, such as machine translation and speech recognition.
TensorFlow Implementation
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# Generate dummy sequential data
import numpy as np
data = np.random.random((1000, 10, 1)) # 1000 sequences, 10 time steps, 1 feature
labels = np.random.randint(2, size=(1000, 1)) # Binary labels
# Define the LSTM model
model = Sequential()
model.add(LSTM(50, input_shape=(10, 1)))
model.add(Dense(1, activation='sigmoid'))
# Compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(data, labels, epochs=10, batch_size=32)
# Evaluate the model
loss, accuracy = model.evaluate(data, labels)
print(f'Loss: {loss}, Accuracy: {accuracy}')
Use Cases of LSTMs
1. Language Modeling:
Application: Predict the next word in a sentence or generate new text.
Example: Language translation services like Google Translate use LSTMs to improve accuracy by understanding context over long sentences.
2. Speech Recognition:
Application: Convert spoken words into text.
Example: Voice assistants like Siri and Alexa utilize LSTMs to understand and process spoken commands effectively.
3. Time Series Forecasting:
Application: Predict future values based on past data.
Example: Financial institutions use LSTMs to predict stock market trends, helping in making investment decisions.
4. Anomaly Detection:
Application: Identify unusual patterns that do not conform to expected behavior.
Example: Cybersecurity firms employ LSTMs to detect potential security breaches by recognizing anomalies in network traffic.
5. Recommender Systems:
Application: Suggest products or content based on user preferences.
Example: Streaming services like Netflix use LSTMs to recommend shows and movies by analyzing viewing patterns.
6. Video Analysis:
Application: Identify actions or objects in video data.
Example: Surveillance systems use LSTMs for real-time activity recognition, enhancing security measures.
Conclusion
LSTMs represent a significant advancement over traditional RNNs by introducing mechanisms to handle long-term dependencies effectively. This makes them invaluable in a wide range of applications that involve sequential data. Despite their complexity, LSTMs' ability to learn and retain long-term information has made them a cornerstone of modern deep learning architectures. Whether it's translating languages, predicting stock prices, or recognizing speech, LSTMs continue to set the standard for performance in sequential data tasks. With tools like TensorFlow, implementing LSTMs has become accessible, enabling widespread use across industries.
Subscribe to my newsletter
Read articles from Osen Muntu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Osen Muntu
Osen Muntu
Osen Muntu, AI Engineer and Flutter Developer, passionate about artificial intelligence and mobile app development. With expertise in machine learning, deep learning, natural language processing, computer vision, and Flutter, I dedicate myself to building intelligent systems and creating beautiful, functional apps. Through my blog, I share my knowledge and experiences, offering insights into AI trends, development tips, and tutorials to inspire and educate fellow tech enthusiasts. Let's connect and drive innovation together!