ReLoop: A Self-Correction Continual Learning Loop for Recommender Systems
 Abhay Shukla
Abhay Shukla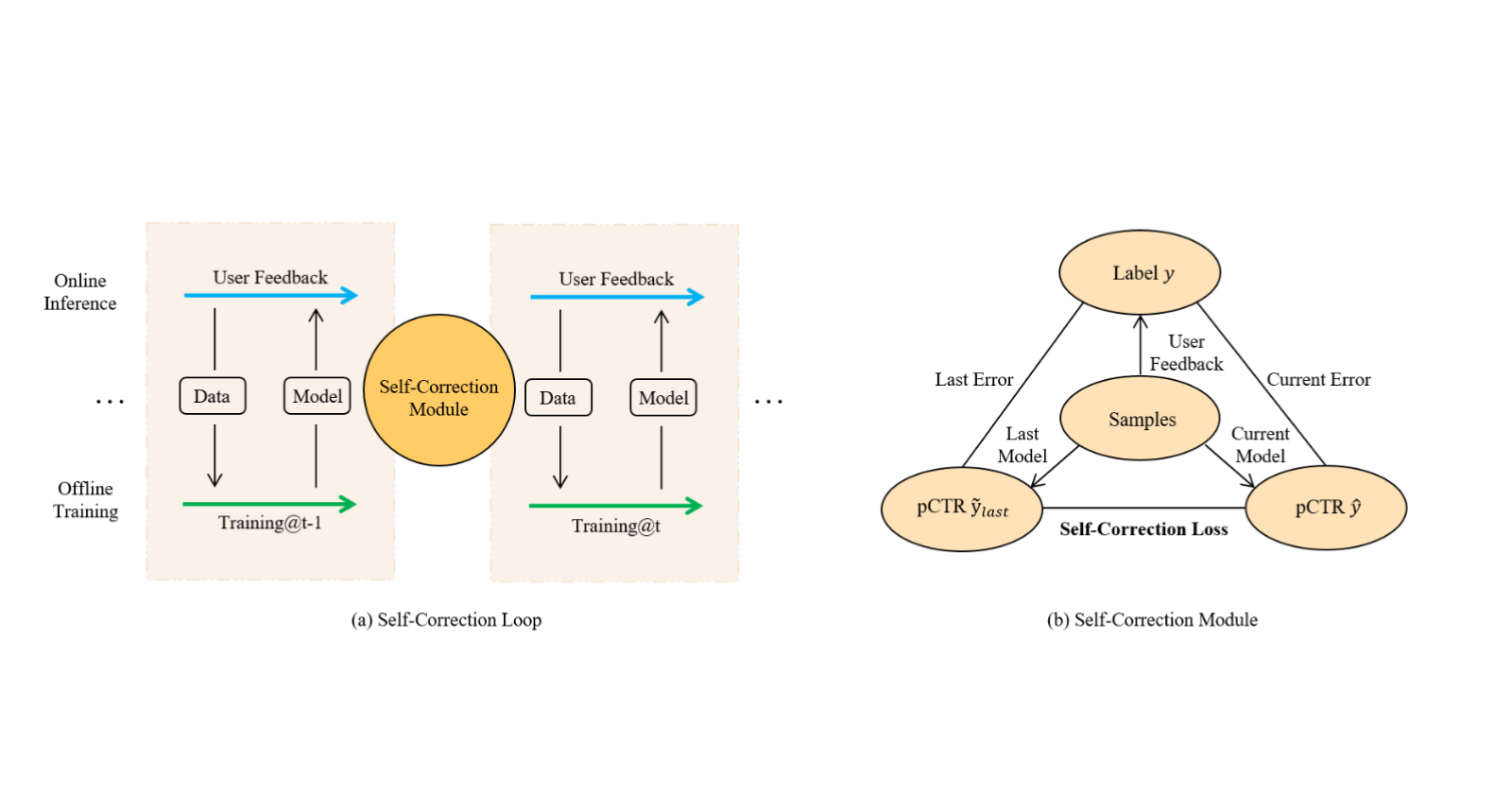
Introduction
Models deployed to production often undergo re-training to learn from new user behaviors and improve the predictions. This training loop is demonstrated in the figure below,
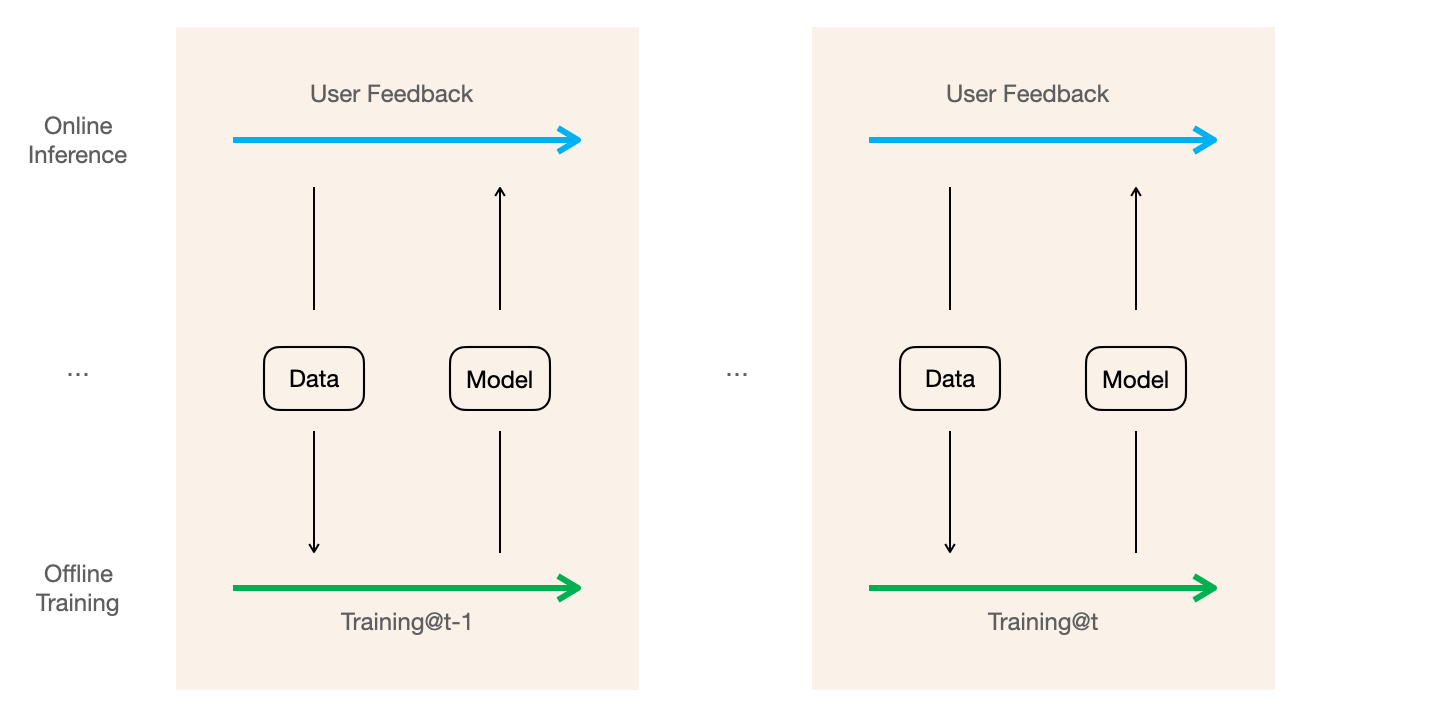
Training data is collected from user's implicit feedback such as clicked items as positives and viewed but not clicked as negatives
Ranking model is trained on the collected data
Production model is updated with the new model
Updated production model is used for online inference and the newly received user feedback is logged
In a regular (re)training loop, steps 1-4 are repeated, usually at some predetermined condition or frequency.
You can find the complete paper here. It is quite easy to read.
Motivation Behind ReLoop
Humans learn not only from the newly gathered information but also from the mistakes made in the past. Can recommender systems do the same? This is the key question authors ask.
In the retraining process described above, the training loop only focuses on the freshly collected user data and does not consider the errors previous model made to improve its learning. This is what inspired the authors to design a training strategy which reflects and learns from the past errors as well.
"Our key insight is that a new model should be forced to make smaller prediction errors than the previous model versions on the same data samples, and thus achieves the ability of self correction."
The proposed approach ReLoop introduces a Self-Correction Module during model re-training to learn from previous mistakes.
ReLoop Approach
ReLoop training strategy is presented in the figure below,
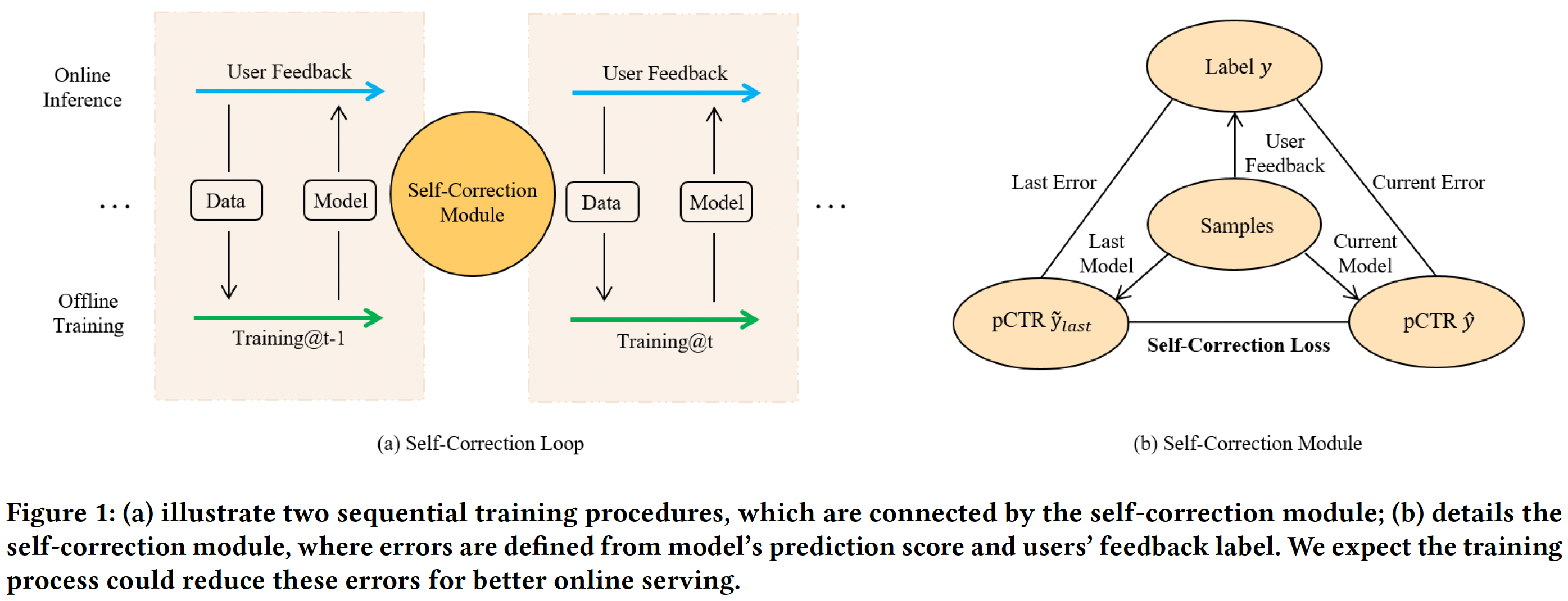
Note that
By introducing Self-Correction Module training loop couples the two successive training periods directly
The illustration and discussion below is presented in context of pCTR model but the technique is model agnostic.
The details of the Self-Correction Module are discussed below.
Self-Correction Module
Self-Correction Module compares the prediction of model@(t-1) and that of new model@t with the ground truth and defines a Self-Correction Loss.
Let,
\(\tilde{y}_{last}\): be the prediction of the model@(t-1), currently in production
\(y\): be the ground truth observed in user logs
\(\hat{y}\): be the prediction of the new model@t which is to be trained
For the case of positive label, i.e. \(y = 1\),
\(y - \hat{y}\): is the Current Error w.r.t. model@t
\(y - \tilde{y}_{last}\): is the Last Error w.r.t. model@(t-1)
To build a self-correcting system, training process@t should get lower error than the previous one. I.e.
$$y - \hat{y} \leq y - \tilde{y}_{last} \Leftrightarrow \tilde{y}_{last} - \hat{y} \leq 0$$
Similarly, for the case of positive label, i.e. \(y=0\), we get
$$\hat{y} - \tilde{y}_{last} \leq 0$$
These two conditions are combined to define the self-correction (SE) loss as,
$$\mathcal{L}_{sc} = y\times max(\tilde{y}_{last} - \hat{y}, 0) + (1-y)\times max(\hat{y} - \tilde{y}_{last}, 0)$$
Training Strategy
For CTR prediction task the binary cross-entropy (CE) loss is defined as
$$\mathcal{L}_{ce} = -y\times log\ \hat{y} - (1-y)\times log\ (1-\hat{y})$$
ReLoop loss is formulated as sum of CE loss and SE loss as,
$$\mathcal{L} = \alpha \mathcal{L}_{sc} + (1-\alpha)\mathcal{L}_{ce}$$
where \(\alpha \in [0,1]\) is the hyper-parameter to adjust the importance of SC loss and CE loss.
Authors make a comparison of self-correction loss with Knowledge Distillation (KD) based training loss. KD loss is given by,
$$\mathcal{L}_{kd} = -\tilde{y}_{last}\times log\ \hat{y} - (1-\tilde{y}_{last})\times log(1-\hat{y})$$
A comparison of \(\mathcal{L}_{ce}\), \(\mathcal{L}_{sc}\) and \(\mathcal{L}_{kd}\) is shown in the figure below,
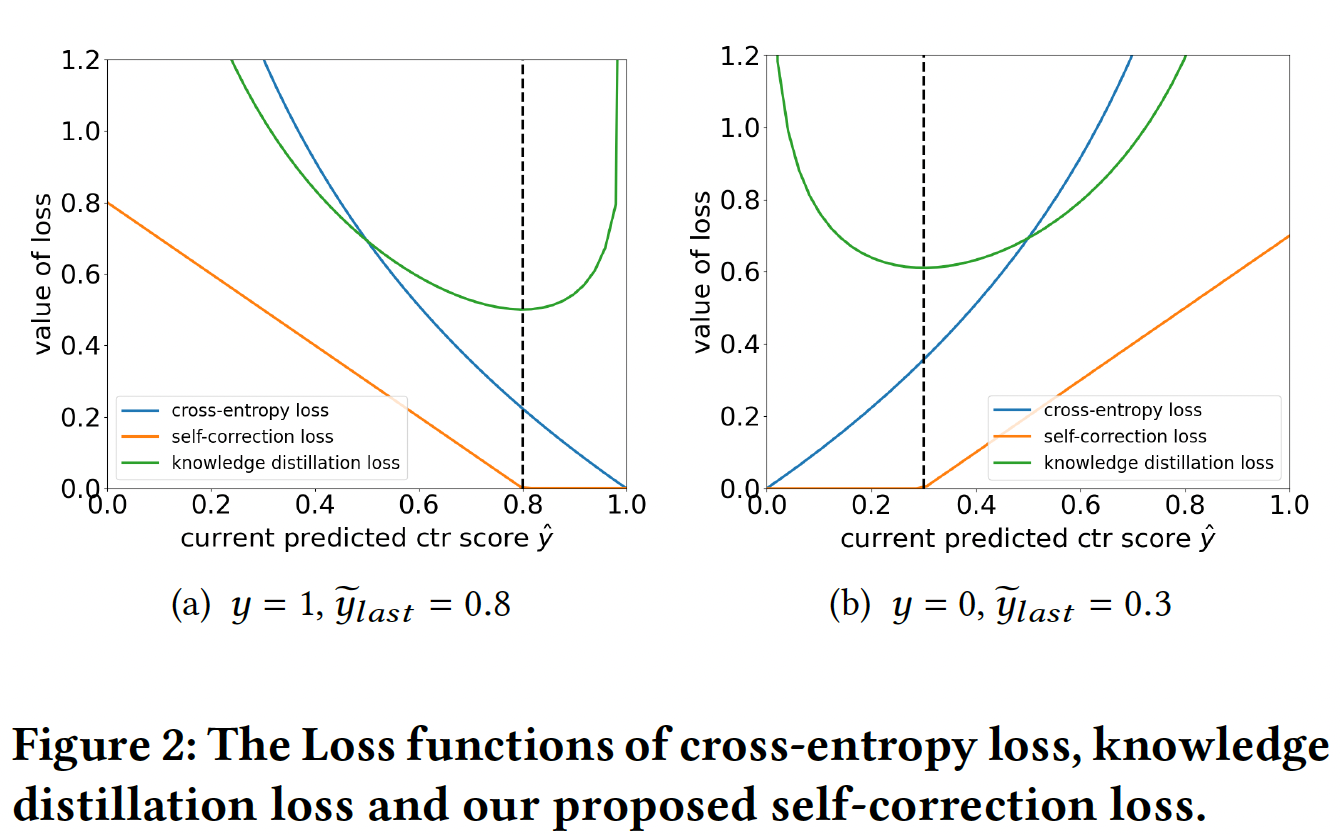
Note that \(\mathcal{L}_{sc}\) is activated only when current model performs worse off than the last model.
Result Discussion
Data
Criteo: is CTR prediction dataset. 45M instances, 13 numerical feature fields and 26 categorical fields.
Avazu: is a mobile ads dataset. 40M instances, 22 feature fields including advertisement attributes and user features.
MovieLens: 2M instances.
Frappe dataset is collected from a context-aware app discovery tool. 288k instances and 10 feature fields.
Production dataset. 500M instances and over 100 feature fields, sampled from an industrial news feed product.
Baselines
ReLoop model is compared with SOTA approaches including FTRL (Follow The Regularized Leader), FM (Factorization Machines), NFM (Neural Factorization Machines), PNN (Product-Based Neural Network), Deep&Cross, Wide&Deep, DeepFM, xDeepFM, FmFM (Field-matrixed Factorization Machines), AFN+ (Adaptive Factorization Network), Distill.
Metric
AUC and LogLoss are used as offline metrics.
CTR is used as online metric.
Offline Results
In offline experiments ReLoop strategy beats other baselines on public datasets. ReLoop (RLP) training strategy is model agnostic but for comparison and experiments DCN and DeepFM backbones are used for training.
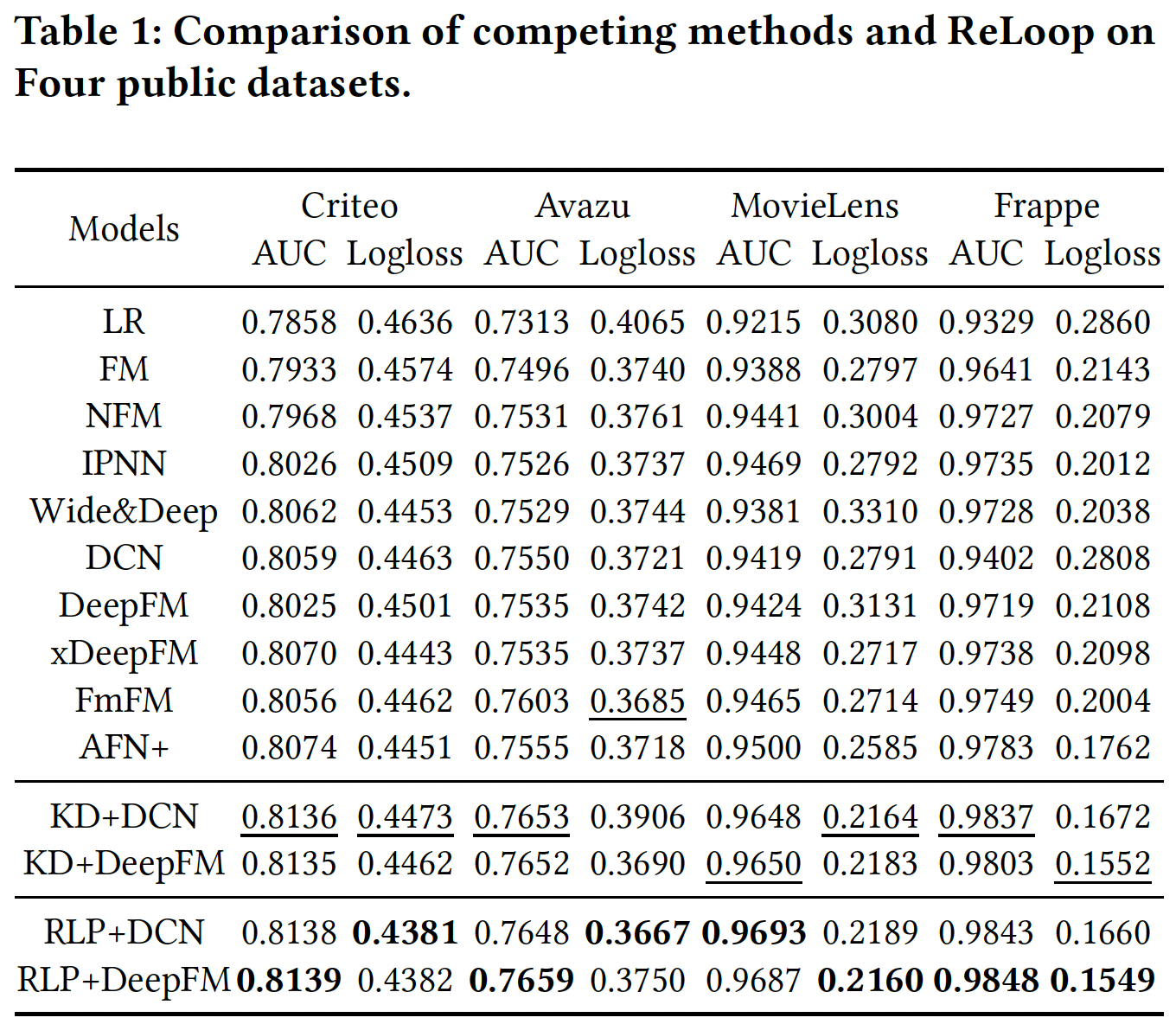
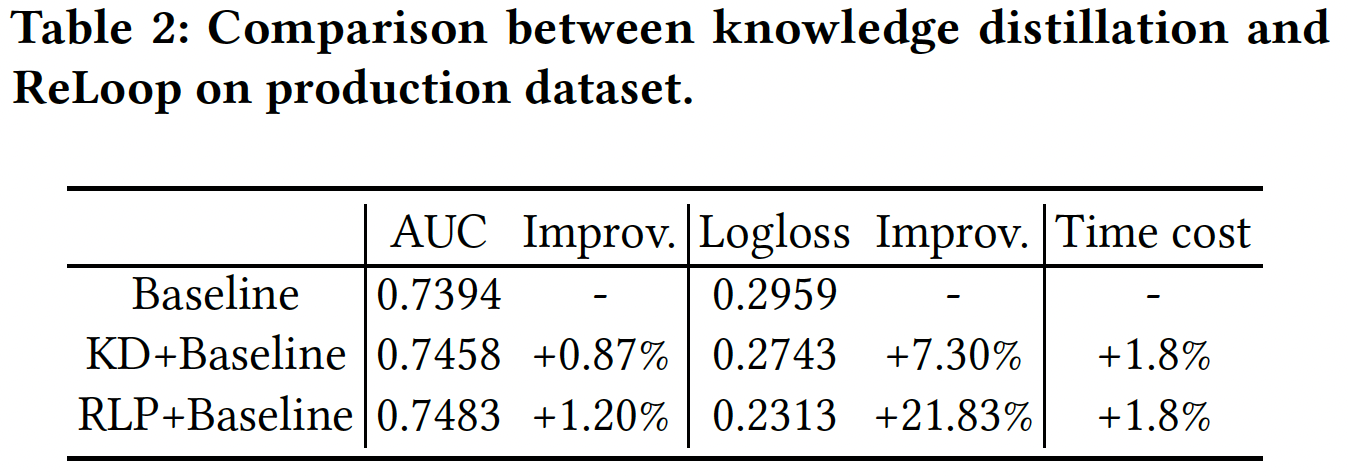
Knowledge Distillation (KD) strategy is the closest to RLP (ReLoop) in public dataset and these two are further on production data as well. It is found that ReLoop beats KD strategy on production data as well.
Online Results
Online results show significant CTR improvement over baseline in A/B test.
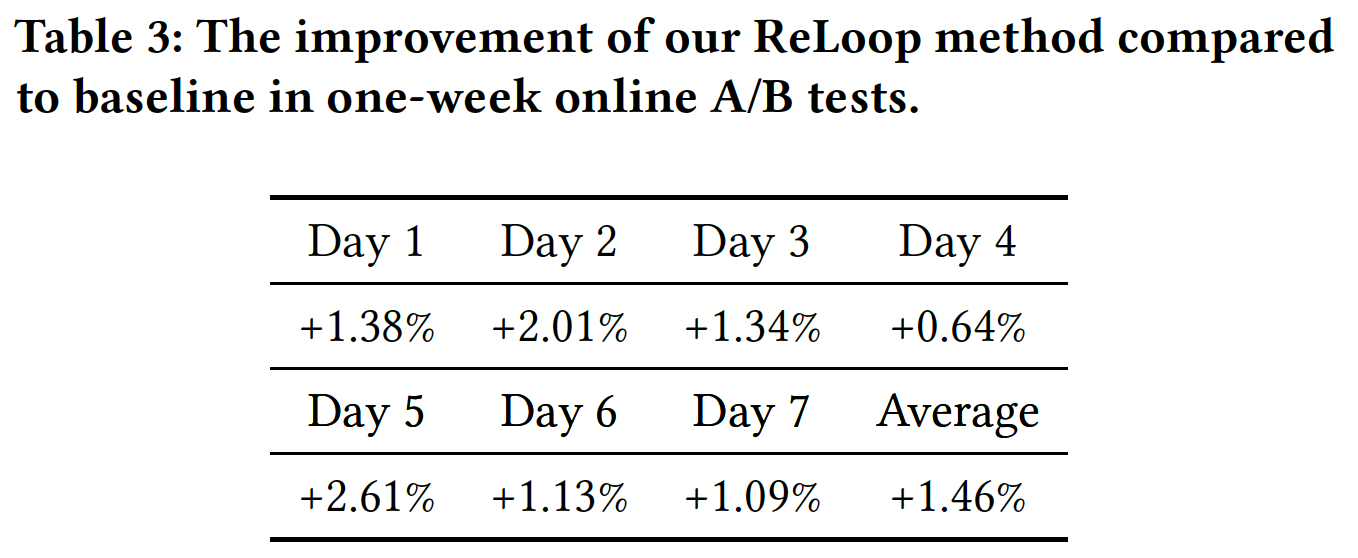
Interestingly, authors also conduct A/A test and the online results report improvements on (A/B - A/A).
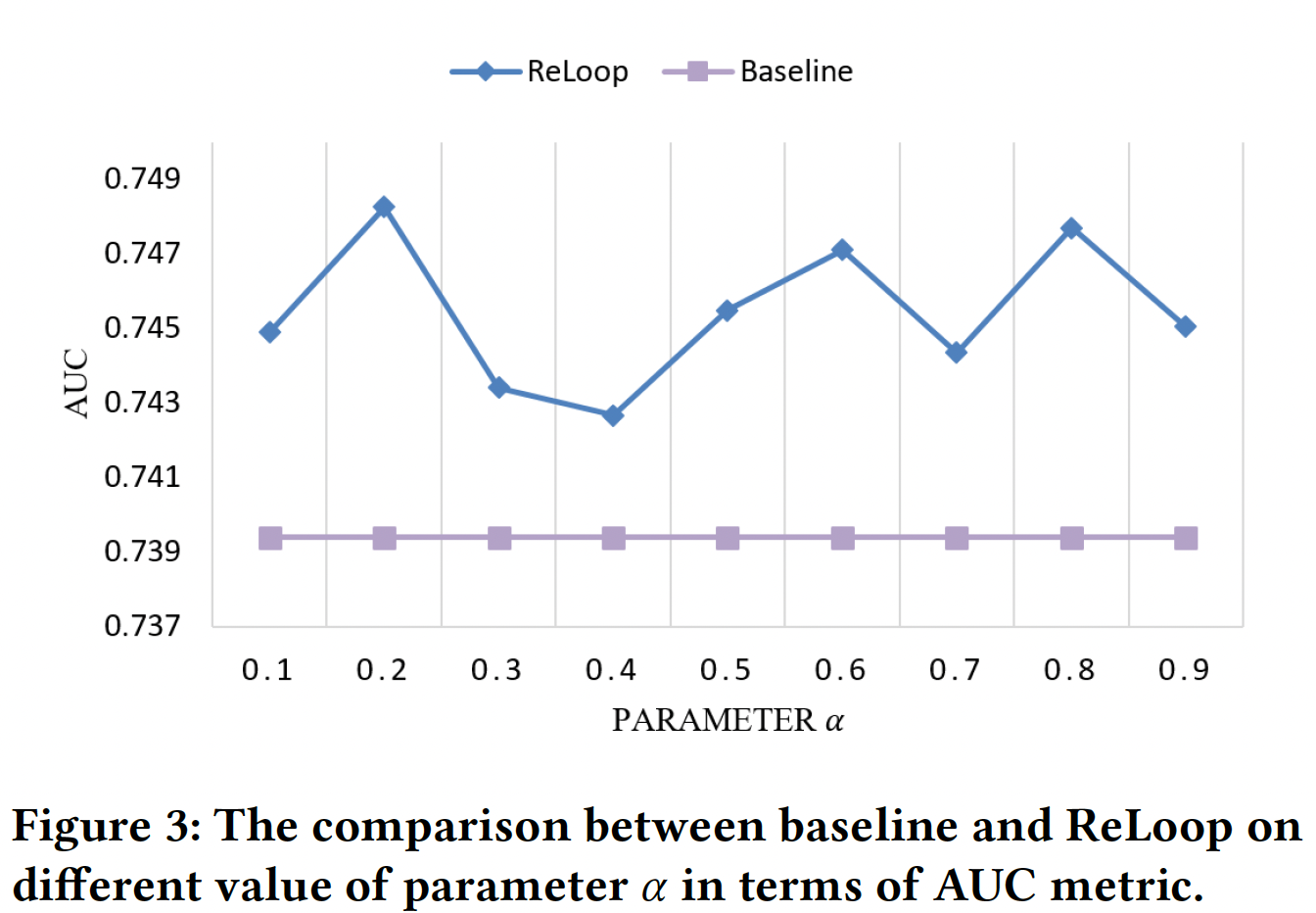
It is also shown that irrespective of the choice of \(\alpha\), the hyper-parameter to adjust the importance of self-correction loss and cross-entropy loss, ReLoop method performs better than baseline methods.
Thoughts/Questions
It will be interesting to extend such a framework to cases where the new model is not a re-trained one but a new model altogether, e.g. a new architecture.
\(\mathcal{L}_{ce}\) and \(\mathcal{L}_{sc}\) losses are of different scales. In such a case, does convex combination makes sense?
How will this training strategy perform w.r.t. noisy labels and outliers? Will it force the re-training to over-fit on noise and outliers?
Subscribe to my newsletter
Read articles from Abhay Shukla directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by