Overcoming Pitfalls of Postgres Logical Decoding
 Sai Srirampur
Sai Srirampur
At PeerDB, we are building a fast and simple way to replicate data from Postgres to data warehouses like Snowflake, ClickHouse etc. and queues such as Kafka, Redpanda etc. We implement Postgres Change Data Capture (CDC) to reliably replicate changes from Postgres to other data stores. Postgres Logical Decoding is a building block of Postgres CDC. It enables users to stream changes on Postgres as a sequence of logical operations like INSERTs, UPDATEs, and DELETEs.
Logical Decoding has evolved quite a bit in the past few years in Postgres. However, there are a few quirks that users need to overcome. In this blog, we will summarize common issues and learnings from over 20 customers replicating more than 300 TB of data per month with logical decoding.
Beware of replication slot growth – how to monitor it?
A logical replication slot captures changes in the Postgres Write-Ahead Log (WAL) and streams them in a human-readable format to the client. A common issue with logical decoding is unexpected replication slot growth, which can risk filling up storage and causing server crashes. Slot growth mostly occurs when the consumer application (a.k.a. client) that reads changes from a replication slot lags or halts. The consumer application can lag for various reasons, including not consuming the slot appropriately and the high throughput on the Postgres database, combined with logical decoding being single-threaded. More on this topic in the next section.
You can monitor replication slot growth using the below queries:
/* the below query should always return "true"
indicating slot is always getting consumed. */
SELECT slot_name,active FROM pg_replication_slots ;
/* monitor the size of the slot using the below query */
SELECT slot_name,
pg_size_pretty(pg_wal_lsn_diff(pg_current_wal_lsn(),restart_lsn))
AS replication_lag_bytes
FROM pg_replication_slots;
NOTE: Just for reference, we open-sourced the PG Slot Notify bot, which helps you monitor replication slot size. pgslot-notify-bot helps monitor PostgreSQL replication slots by sending alerts once the size threshold is reached.
Tips for keeping replication slot growth in check
Always consume the replication slot
Logical decoding is a single-threaded process, whereas Postgres allows multiple concurrent connections/threads to ingest data. This means that if the client doesn't consume the replication slot fast enough, the slot can quickly grow.
The first step toward efficiency is to ensure that the client always consumes the replication slot and maximizes resource utilization. Intermittent reading of the slot with constant disconnections can slow down logical decoding. Periodic reconnections can lead to other inefficiencies, as logical decoding may need to restart from the beginning of the WAL instead of continuing the stream.
At PeerDB, we implemented this optimization. We ensure that the replication slot is always consumed and flushed to internal stages such as S3.
Beware of long-running transactions
Long-running transactions can lead to WAL buildup. Since WAL is sequential, Postgres cannot flush the WAL until the long transaction completes, even as other transactions are being consumed. This can result in an increased slot size and slow down logical decoding. For each transaction being decoded, changes from long-running transactions that overlap with the current transaction must also be decoded again and again.
Configure statement_timeout and idle_in_transaction_session_timeout to avoid long running transactions
Long-running transactions can occur either due to active queries running for a long time or stale transactions that were never committed. To avoid these scenarios, you should configure statement_timeout, which terminates queries that run longer than expected, and idle_in_transaction_session_timeout, which terminates stale transactions.
Use logical replication protocols
The SQL API (START_REPLICATION) supports different versions of streaming, controlled via the proto_version parameter. The default proto_version (v1) allows clients to consume changes only from committed transactions. proto_version v2 allows clients to consume changes from in-flight transactions, improving performance by letting them process changes immediately without waiting for the COMMIT. However, it is the client's responsibility to handle transaction semantics. At PeerDB, we are working on a feature that supports proto_version (v2).
This changes decoding from an O(N^2) operation to an O(N) operation and also helps address scenarios with long-running transactions. This blog provides a deep dive into how replication slot growth is affected with v2.
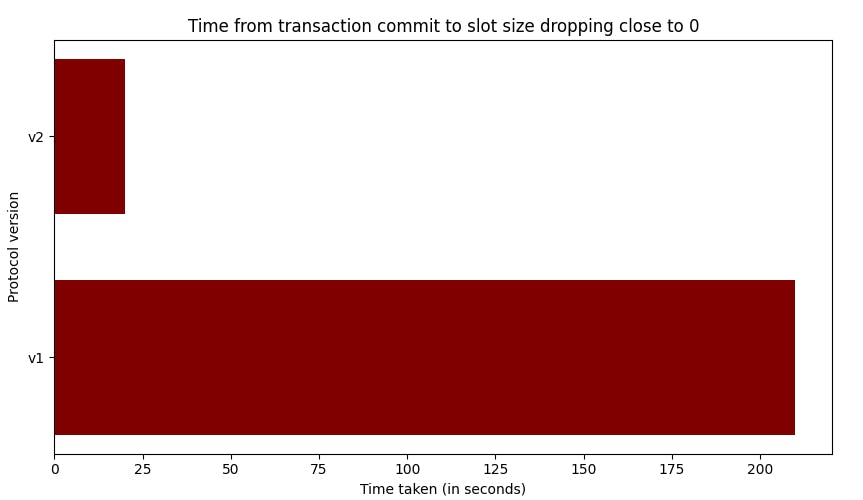
Reference: https://blog.peerdb.io/exploring-versions-of-the-postgres-logical-replication-protocol
No activity can lead to replication slot growth.
It is common to see replication slots grow in size in dev/test/QA databases during periods of inactivity. In such scenarios, the WAL continues to grow due to maintenance processes like VACUUMs. To avoid this and ensure that the slot is consistently consumed by the client, you can follow one of the approaches below:
Include a heartbeat table that continuously gets updated in your replication pipeline. This ensures that the slot keeps moving. More details on this approach can be found here.
Use
pg_logical_emit_messageto periodically emit a message in the WAL and ensure that this message is consumed by the client by confirming the LSN (Log Sequence Number) of the message.
Use table filtering when creating PUBLICATIONs
If you are replicating changes from only a few tables, ensure that you create a PUBLICATION that includes just those tables. Postgres efficiently persists changes for only those tables in the replication slot. This helps reduce the size of the replication slot and improves logical decoding performance.
Some useful Postgres configs
max_slot_wal_keep_size
To keep your logical replication slots from consuming excessive disk space, set the max_slot_wal_keep_size parameter. This config limits the amount of WAL (Write-Ahead Log) data a replication slot can retain. Choose a size that suits your environment to ensure old WAL files are removed when the limit is reached, preventing disk space issues.
logical_decoding_work_mem
To control memory usage during logical decoding, adjust the logical_decoding_work_mem parameter. This setting allocates a specific amount of memory for the decoding process of each replication slot. Set a value that balances memory use and performance according to your system's capacity and workload. You can consider increasing logical_decoding_work_mem if you observe IO as the wait_event for the START_REPLICATION process. More details on tuning logical_decoding_work_mem can be found here.
Supporting DDL Changes
One of the most common and well-known issues with logical decoding is that it doesn't capture schema changes such as adding or dropping columns, changing data types, adding new tables, and so on.
An approach that clients could follow is to leverage Relation and Type messages that logical decoding provides. Whenever columns are added or dropped, Postgres sends a Relation ('R') message with the new schema, preceding the new row. Clients can perform a diff with the old schema to identify the new or dropped columns. A similar approach can be followed for supporting changing data types, where Postgres sends a Type ('T') message.
Within PeerDB, we implemented the above intricate approach to support automatic schema changes, such as adding or dropping columns.
TOAST columns need REPLICA IDENTITY FULL
Logical decoding doesn't capture TOAST (large sized >8KB) columns that haven't been changed in an update operation. You need to enable REPLICA IDENTITY FULL for a table to capture values of unchanged TOAST columns.
Here is a useful blog that talks about the impact of setting REPLICA IDENTITY FULL on your Postgres database. TL;DR:REPLICA IDENTITY FULL might be fine for tables with primary keys or from Postgres 16, where indexes can be used on the subscriber side for searching the rows.
In PeerDB, for certain targets, we implemented a method to replicate unchanged TOAST columns without requiring REPLICA IDENTITY FULL.
Logical decoding doesn’t support generated columns
One limitation of Postgres logical decoding is that it doesn’t support generated columns. Generated columns are columns whose values are automatically computed from other columns in the table using a specified expression. Values of these columns appear as NULL for clients consuming the logical replication slots. A few workarounds incl:
In-flight transformations: Compute the value of generated columns while the data is in transit by performing transformations. PeerDB supports row-level transformations out-of-the-box to enable such generated column use cases.
Extract, Load, and Transform (ELT): Another approach we've seen customers follow is to perform transformations once the data reaches the target. Customers often use transformation tools such as DBT or Coalesce.
Logical Replication Slots Don't Persist on Postgres Upgrades
Upgrading PostgreSQL versions presents a challenge because logical replication slots do not persist through upgrades. However, it's possible to manage upgrades without full resyncs by recreating the replication slot during maintenance.
The process is as follows:
Enter Maintenance Mode: Place the database in maintenance mode to prevent data changes.
Upgrade PostgreSQL: Perform the PostgreSQL version upgrade.
Recreate Replication Slot: Recreate the logical replication slot.
Exit Maintenance Mode: Resume normal operations.
This method ensures minimal disruption and avoids the need for a complete resync of the data.
Starting Postgres 17 replication slots are persisted on upgrades
Starting with PostgreSQL 17, logical replication slots will persist through version upgrades. This improvement will apply to future upgrades, such as from version 17 to 18, simplifying the upgrade process significantly.
Logical Replication Slot don't persist Failovers
Another issue with logical decoding is that replication slots don't persist during a failover, i.e., when a standby becomes primary. One potential solution is to implement retry logic in your clients to recreate the replication slot post-failover. However, this approach is not fully reliable and can incur data loss, as creating the slot right after failover without data ingestion is not trivial.
Postgres 17 will support failover slots
The good news is that PostgreSQL 17 will support failover slots, allowing replication slots to persist automatically through failovers. This enhancement simplifies the failover process, ensures data reliability, and reduces manual intervention, resulting in more robust and resilient replication handling.
Conclusion
At PeerDB, we are building a replication tool with a laser focus on Postgres. To provide the fastest and most reliable Postgres replication experience, we delve deeply into understanding Postgres logical decoding. This blog summarizes our efforts over the past year. Many of the challenges discussed above have already been addressed in our product, and for those that haven't, we work closely with our customers to find and implement workarounds. We hope you enjoyed reading the blog! If you want to give PeerDB a try, these links should prove useful: :)
Subscribe to my newsletter
Read articles from Sai Srirampur directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by