pg_bestmatch.rs: Elevate Your PostgreSQL Text Queries with BM25
 Jinjing Zhou
Jinjing ZhouTable of contents

We're excited to announce the release of pg_bestmatch.rs, a PostgreSQL extension that brings the power of Best Matching 25 Score (BM25) text queries to your database, enhancing your ability to perform efficient and accurate text retrieval. This extension allows users to generate BM25 statistic sparse vectors from text, leveraging the proven performance of BM25 in various benchmark tasks.
Why BM25?
BM25 (Best Matching 25) is a probabilistic ranking function used in information retrieval to evaluate how well a document matches a query. It calculates relevance scores based on term frequency (TF) and inverse document frequency (IDF), balancing these with document length normalization. The formula ensures that terms appearing frequently in a document (TF) and those that are rare across the corpus (IDF) are appropriately weighted, enhancing search accuracy and relevance.
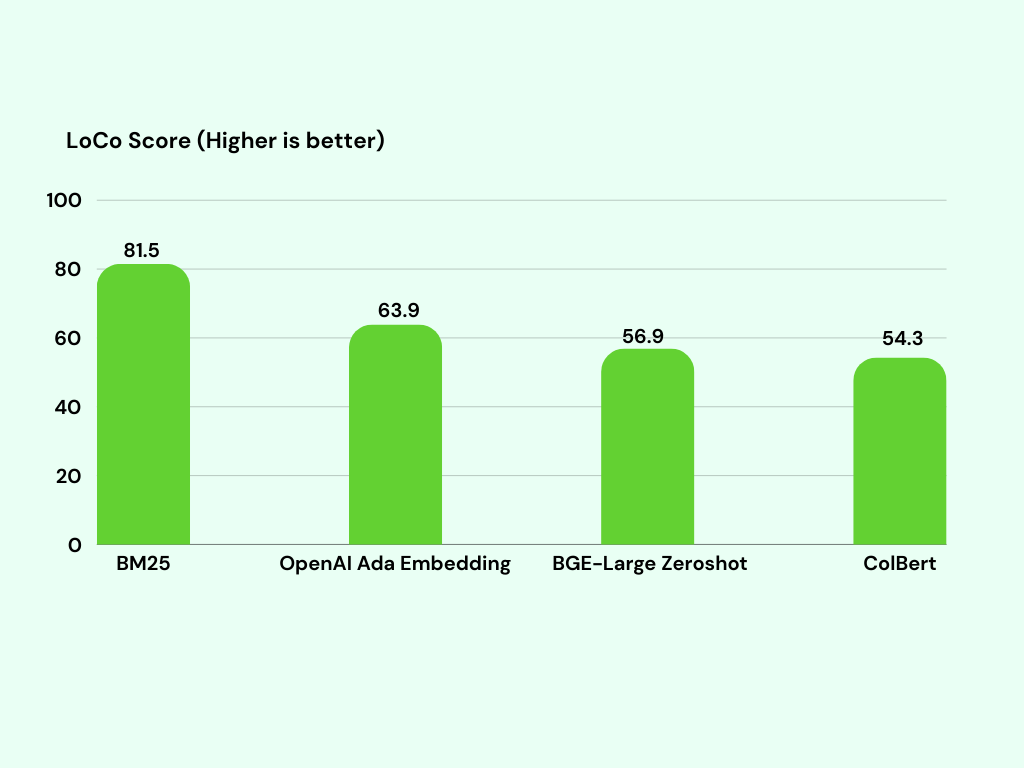
BM25 has been shown to outperform dense vector-based retrieval methods in numerous RAG benchmark tasks. By integrating BM25 into PostgreSQL, you can achieve superior search performance and relevance, especially for applications requiring high-quality text retrieval. You can also combine it with vector search as the hybrid search integration.
Key Features
BM25 Statistic Sparse Vectors: Generate BM25 sparse vectors for text based on your own text data.
Integration with Vector Search Extensions: Compatible with
pgvecto.rsandpgvectorfor efficient vector searches in PostgreSQL.Seamless Tokenization: Utilizes Huggingface's
bert-base-uncasedvocabulary with Byte-Pair Encoding (BPE) tokenizer, boosting performance with subword tokenization
How Does It Work?
$$\begin{align*} \text{BM25 score}(\text{query}, \text{document}) &= \sum_{t \in q} \underbrace{\text{IDF}(t)}{\text{query}} \cdot \underbrace{\frac{f(t, d) \cdot (k_1 + 1)}{f(t, d) + k_1 \cdot (1 - b + b \cdot \frac{|d|}{\text{avgdl}})}}{\text{document}} \\ &= \sum_{t \in q} q_t \cdot d_t = \vec{q} \cdot \vec{d} \end{align*}$$
The BM25 computation can be decomposed into separate components for the query and the documents. The final relevance score is calculated as the dot product between the query's sparse vector and the document's sparse vector. Therefore we transform BM25 into a sparse vector retrieval problems with dot product distance!
Usage
Here's a step-by-step overview of how it works:
Create BM25 Statistics: Use the
bm25_createfunction to generate BM25 statistics for your document set. This function takes the table name, column name, and a statistic name as parameters and creates a materialized view to store the BM25 statistics.SELECT bm25_create('documents', 'passage', 'documents_passage_bm25');Generate Document Sparse Vectors: Convert your document text into sparse vector representations using the
bm25_document_to_svectorfunction. This function takes the BM25 statistic name and the document text as inputs.SELECT bm25_document_to_svector('documents_passage_bm25', 'document_text') as document_vector;Generate Query Sparse Vectors: For each search query, generate a corresponding sparse vector using the
bm25_query_to_svectorfunction. This function also takes the BM25 statistic name and the query text as inputs.SELECT bm25_query_to_svector('documents_passage_bm25', 'search_query') as query_vector;Calculate Relevance Scores: Compute the relevance score of documents for a given query by performing a dot product between the query sparse vector and the document sparse vectors. This score indicates how well a document matches the query.
SELECT document_id, (query_vector <#> document_vector) AS bm25_score FROM documents ORDER BY bm25_score LIMIT 10;
Join the Community
We invite you to try pg_bestmatch.rs and share your feedback. Your contributions and suggestions are invaluable as we continue to enhance and refine this extension. Star our GitHub repository and join our Discord server to get started and become part of our growing community and share your feedback with us.
Experience the power of BM25 text queries in PostgreSQL with pg_bestmatch.rs —your new go-to tool for efficient and accurate text retrieval.
Subscribe to my newsletter
Read articles from Jinjing Zhou directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by