Chapter 1 - Large Multimodal Model
 Hrishikesh Yadav
Hrishikesh YadavTable of contents

The Large Multimodal Model overview will be given to you in this blog. Also, the model's expanded capabilities for a variety of use cases, which were only achieved with a large amount of training data in deep learning, and the hands-on 💻 experience with the Gemini Pro Vision. This blog focuses on providing the vision on how various usecases are redefined within the realm of Generative Artificial Intelligence.

Overview
Large Multimodal Models (LMMs) represent a cutting-edge development in artificial intelligence, combining the power of language models with the ability to process and understand visual data. These models leverage deep learning techniques to fuse textual and visual information, enabling a range of innovative applications that bridge the gap between language and imagery.
At the core of an LMM lies a visual encoder and a language model, seamlessly connected through a specialized connector architecture. The visual encoder is responsible for extracting meaningful representations from images, videos, or other visual inputs, while the language model processes and generates human-readable text. This fusion of modalities allows LMMs to comprehend and reason about complex scenarios involving both text and visuals, unlocking new possibilities in fields such as computer vision, natural language processing, and multimodal understanding.

One of the key strengths of LMMs is their ability to leverage vast amounts of multimodal training data, encompassing pretraining data for aligning modalities, high-quality supervised learning data for injecting domain knowledge, and instruction tuning data for enhancing performance on specific tasks.
Architecture of MLLMs
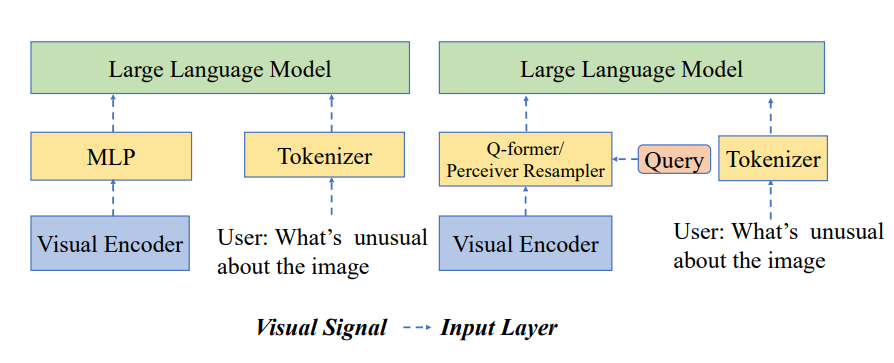
The architectural design of MLLMs is a critical factor that influences their capabilities. Some models, such as LLaVA, take a more direct approach by incorporating visual tokens as if they were a foreign language, directly injecting them into the input layer of the large language model. This method allows the model to process visual and textual information simultaneously within the same input stream.
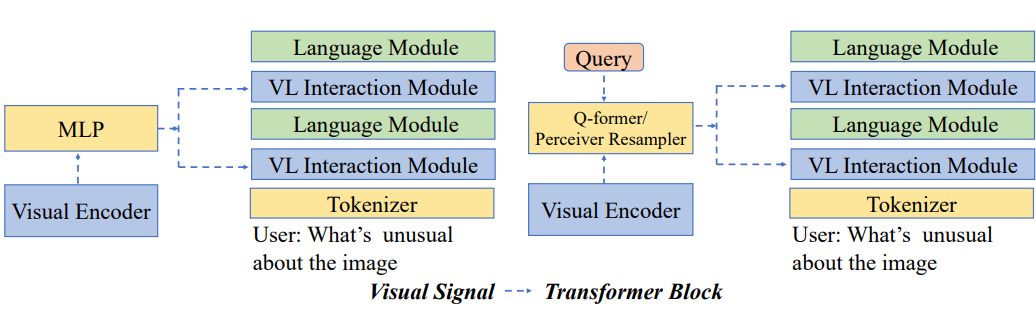
Other MLLMs, like Flamingo, employ cross-attention layers to facilitate interactions between visual and language features within the transformer blocks. This approach enables the model to attend to and integrate information from both modalities at multiple levels of the architecture. The specifics of the connector design also play a crucial role in determining the capabilities of MLLMs. For instance, models such as BLIP-2, Flamingo, and QWen-VL utilize query-based connectors like Q-former or perceiver resampler, while LLaVA and MiniGPT4-v2 employ a multilayer perceptron (MLP) as the connector.
The current modified methods involve using the foundation model as a gated modality to aid in the creation of the multimodal representation. The multimodal representation, which primarily consists of audio and video, is then mapped with the language embedding to create the video-language embedding, which facilitates interaction and response generation for the large language model. The pegasus-1 model by TwelveLabs were designed as per this and the Marengo 2.6 is used for the creation of the multimodal representation.
QWen-VL employs a more intricate three-stage training process that involves pretraining, multi-task training, and instruction tuning. Notably, significant emphasis is placed on the utilization of high-quality supervised data during the multi-task training stage. This comprehensive approach enables the model to acquire and consolidate knowledge across diverse tasks and modalities. Pegasus-1 is a different MLLM and Improved as it is been trained on 1,00,000 high quality video text pairs. Also, trained on the massive multimodal dataset over multiple stages.
One major problem that arises during the training of large multimodal models is catastrophic forgetting, which refers to the tendency of a model to forget previously learned knowledge as it is trained on new data. This can be particularly problematic when fine-tuning large foundation models on new modalities or tasks. To mitigate this issue, techniques such as selective updates by unfreezing the foundation model parameters and carefully adjusting learning rates during the training process can be employed. By judiciously updating only specific portions of the model and controlling the learning rates, catastrophic forgetting can be minimized, enabling the preservation of previously acquired knowledge while effectively integrating new information and capabilities.
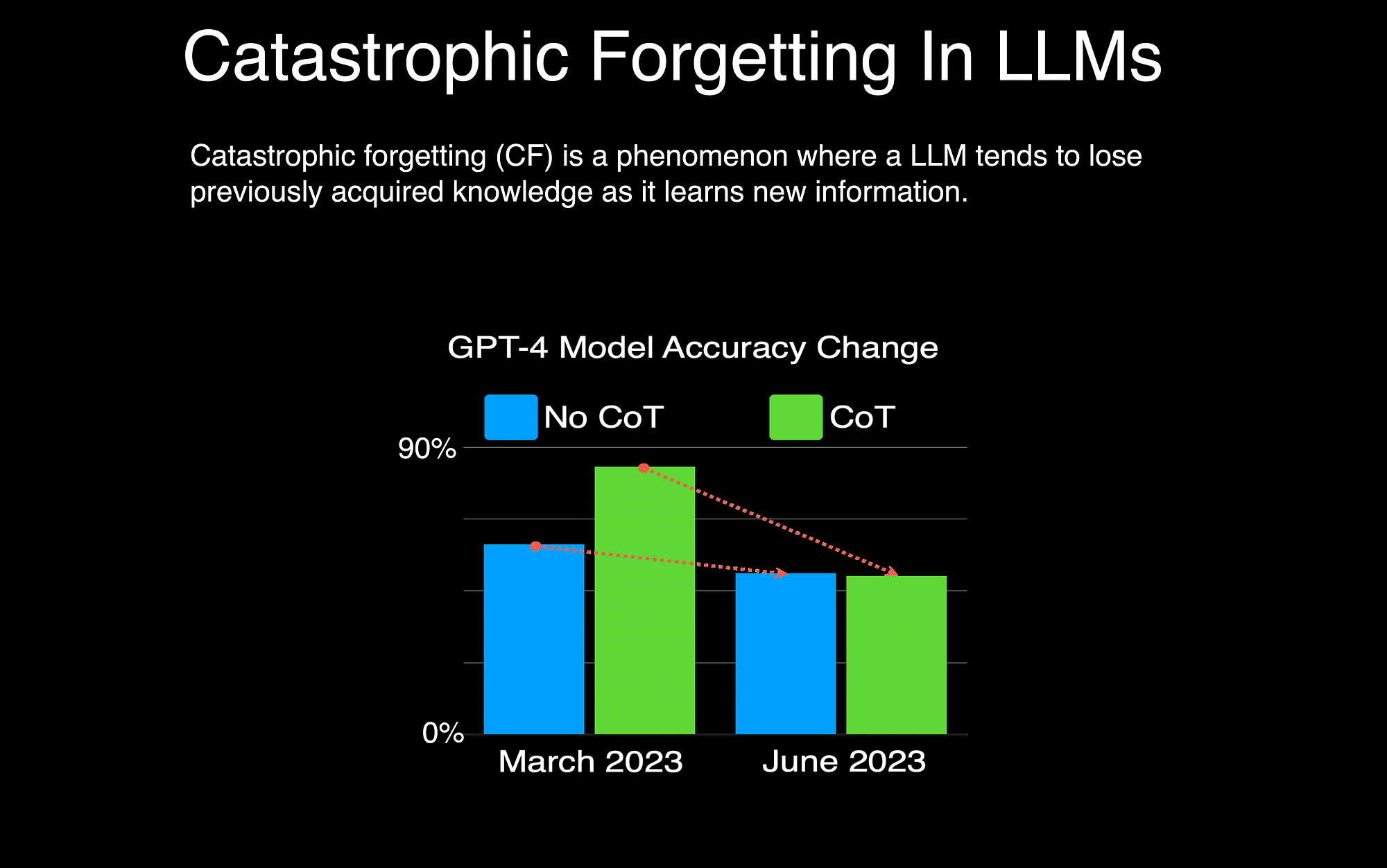
This challenge is crucial to address for ensuring the robust and stable performance of multimodal models across diverse tasks and domains.
Hands-On with Gemini Pro Vision
setting up the environment
!pip install google-generativeai
Loading the environment variable and the API key of Gemini
import os
import PIL.Image
from dotenv import load_dotenv, find_dotenv
import google.generativeai as genai
from google.api_core.client_options import ClientOptions
load_dotenv()
GOOGLE_API_KEY=os.getenv('GOOGLE_API_KEY')
Setting up the model configuration
genai.configure(
api_key=GOOGLE_API_KEY,
transport="rest",
client_options=ClientOptions(
api_endpoint=os.getenv("GOOGLE_API_BASE"),
),
)
Now, Time to prepare the function to call the model with the text and Image
def gemini_model(image_path: str, prompt: str) -> str:
img = PIL.Image.open(image_path)
model = genai.GenerativeModel('gemini-pro-vision')
response = model.generate_content([prompt, img], stream=True)
response.resolve()
return response.text
Here, the model selected from the genai package is gemini-pro-vision.
We will be putting this image, to understand what all things can be done with the model.

gemini_model("pizza.jpg",
"Analyze whether it is healhty or How can I make it healthy ?")
The response, we get after hitting the model
Pizza is a popular dish that can be enjoyed by people of all ages. However, it is often considered to be an unhealthy food choice due to its high calorie, fat, and sodium content.
By making these few simple changes, you can enjoy pizza without feeling guilty. Here are some additional tips for making healthy pizza:
Use a light tomato sauce or marinara sauce instead of a heavy cream sauce.
Add plenty of vegetables to your pizza. Some good choices include broccoli, mushrooms, peppers, and onions.
Choose lean protein toppings, such as chicken, turkey, or fish.
Limit the amount of cheese you put on your pizza.
Bake your pizza instead of frying it.
By following these tips, you can make pizza a healthy and delicious part of your diet.
In order to make a specific use case the target, the prompt can be adjusted, and in doing so, the input image can be modified. Some additional use cases within the multimodal (specific Image + Text) space that you can explore are -
UI Image to Code
Tourist Place Guide
Nutrition Analysis of Food
Food Photo to Recipe
Doodle Like Game
and many more
It is necessary to comprehend and assess the usecase's suitability for that model as well as its vulnerability while developing the application. In the upcoming chapter, we will be discussing on how one can utilize the vector database like weavite to perform the RAG like operation with the multimodal storage for the next generation retrieval usecases.
Various Research Work to go through in the Large Multimodal Model
Exploring the Reasoning Abilities of Multimodal Large Language Models (MLLMS): A Comprehensive Survey on Emerging Trends in Multimodal Reasoning - https://arxiv.org/pdf/2401.06805
Large Multimodal Models: Notes on CVPR 2023 Tutorial -https://arxiv.org/pdf/2306.14895
PaLM-E: An Embodied Multimodal Language Model - https://arxiv.org/pdf/2303.03378
A survey on the Multimodal Large Language Model for the Autonomous Car - https://openaccess.thecvf.com/content/WACV2024W/LLVM-AD/html/Cui_A_Survey_on_Multimodal_Large_Language_Models_for_Autonomous_Driving_WACVW_2024_paper.html
MM-LLMs: Recent Advances in MultiModal Large Language Models - https://arxiv.org/pdf/2401.13601
Subscribe to my newsletter
Read articles from Hrishikesh Yadav directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Hrishikesh Yadav
Hrishikesh Yadav
With extensive experience in backend and AI development, I have a keen passion for research, having worked on over 4+ Research work in the Applied Generative AI domain. I actively contribute to the community through GDSC talks, hackathon mentoring, and participating in competitions aimed at solving problems in the machine learning and AI space. What truly drives me is developing solutions for real-world challenges. I'm the member of the SuperTeam and working on the Retro Nexus (Crafting Stories with AI on Chain). The another major work focused on the technological advancement and solving problem is Crime Dekho, an advanced analytics and automation platform tailored for police departments. I find immense fulfillment in working on impactful projects that make a tangible difference. Constantly seeking opportunities to learn and grow, I thrive on exploring new domains, methodologies, and emerging technologies. My goal is to combine my technical expertise with a problem solving mindset to deliver innovative and effective solutions.