Apache Kafka Architecture: A Comprehensive Guide
 Sandeep Choudhary
Sandeep Choudhary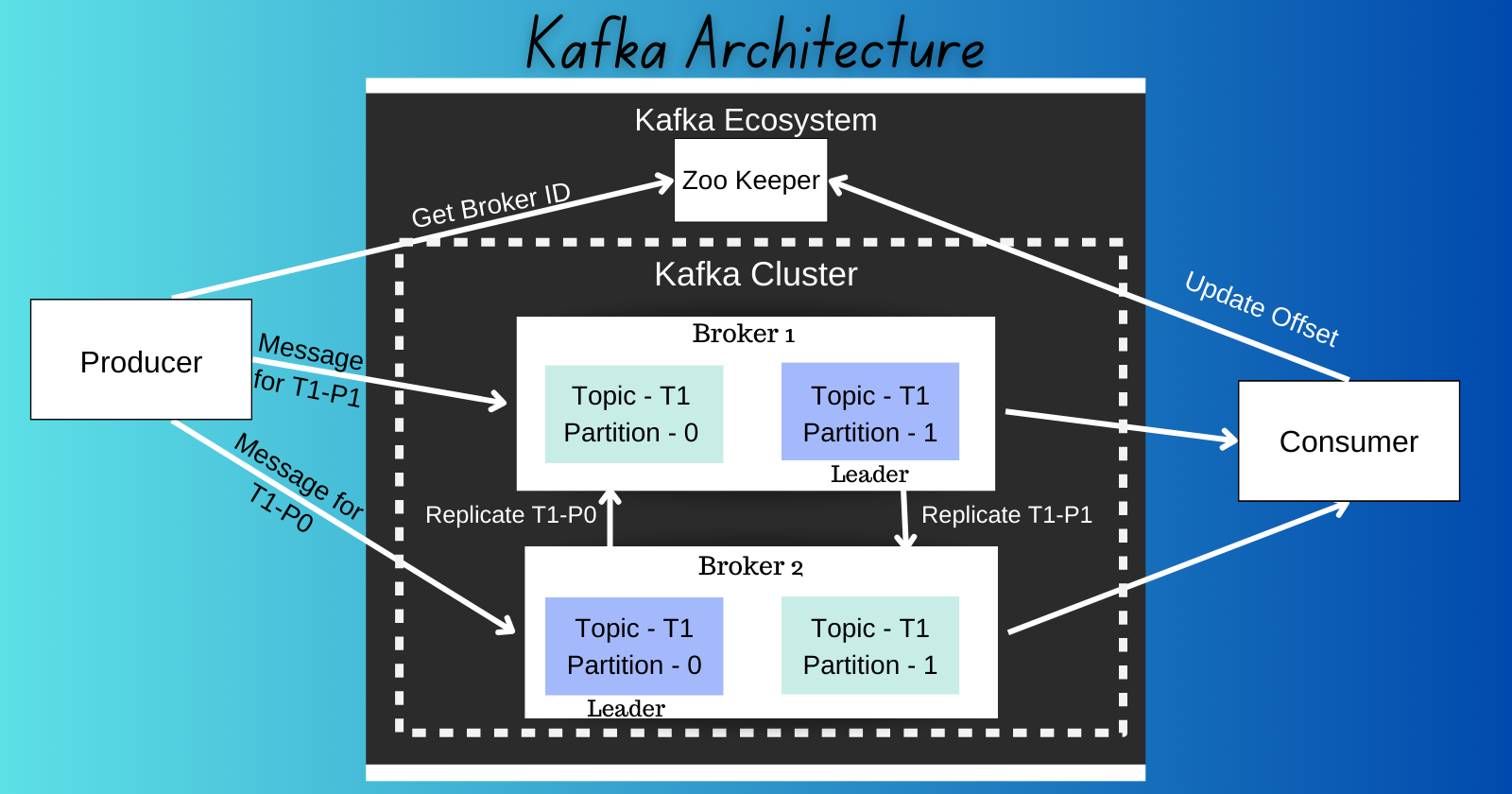
Apache Kafka is a powerful event streaming platform that allows developers to react to new events as they occur in real time. It’s designed to handle high-throughput, low-latency processing, and it’s used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. A storage layer and a computing layer make up the Kafka architecture. The storage layer is built to be a distributed system that can be quickly scaled up to meet growing storage needs and meant to store data efficiently. The four main parts of the compute layer are the connector APIs, streams, producer, and consumer. Together, these components enable Kafka to scale applications across dispersed systems. We'll explore every element of Kafka's architecture in this guide.
Clusters
A Kafka cluster is a system that consists of several brokers, topics, and their respective partitions. The key objective of a Kafka cluster is to distribute workloads equally among replicas and partitions. Within the context of Kafka, a cluster is a group of servers working together for three reasons: speed (low latency), durability, and scalability. Several data streams can be processed by separate servers, which decreases the latency of data delivery. Data is replicated across multiple servers, so if one fails, another server has the data backed up, ensuring stability. Kafka also balances the load across multiple servers to provide scalability.
Kafka brokers manage the load balancing, replication, and stream decoupling within the Kafka cluster. In Kafka, data (individual pieces of data are events) are stored within logical groupings called topics. Those topics are split into partitions, the underlying structure of which is a log. Each of those logs can live on a different broker or server in the cluster. This balances the work of writing and reading from the partition across the cluster. This is also what makes Kafka fast and uniquely scalable.
In order to keep data durable across a distributed system, it is replicated across a cluster. Each node in a cluster has one of two roles when it comes to replication: leader or follower.
Message Brokers
A Kafka broker is a server that runs an instance of Kafka. It is responsible for maintaining the list of consumers for each topic, as well as managing the storage of messages for each topic. A broker is a bridge between producers and consumers. If a producer wishes to write data to the cluster, it is sent to the Kafka server. All brokers lie within a Kafka cluster itself. Also, there can be multiple broker.
The key responsibilities of a Kafka broker include:
Maintaining the list of consumers for each topic: Brokers keep track of which consumers are consuming data from which topics.
Managing the storage of messages for each topic: Brokers are responsible for storing the messages or events that are published to each topic. They ensure that these messages are available for consumption and are retained as per the configured retention policies.
Handling data: Brokers are responsible for receiving messages from producers, assigning offsets to them, and committing the messages to storage on disk. They also service consumers, responding to fetch requests for partitions and delivering the messages to consumers.
Load balancing: Kafka brokers help in distributing the load across multiple servers by maintaining the distribution of topic partitions across the Kafka cluster.
Kafka Connect
Apache Kafka Connect is a free, open-source component of Apache Kafka that serves as a centralised data hub for simple data integration between databases, key-value stores, search indexes, and file systems. Here are some key points about Kafka Connect:
Data Integration: Kafka Connect makes it simple to quickly define connectors that move large data sets in and out of Kafka. It can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing with low latency.
Export Connector: An export connector can deliver data from Kafka topics into secondary indexes like Elastic search, or into batch systems such as Hadoop for offline analysis.
Deployment Modes: Kafka Connect can be deployed as a standalone process that runs jobs on a single machine (for example, log collection), or as a distributed, scalable, fault-tolerant service supporting an entire organisation.
Data-centric Pipeline: Connect uses meaningful data abstractions to pull or push data to Kafka.
Flexibility and Scalability: Connect runs with streaming and batch-oriented systems on a single node (standalone) or scaled to an organisation wide service (distributed).
Reusability and Extensibility: Connect leverages existing connectors or extends them to fit your needs and provides lower time to production.
Topics
A Kafka topic is the most fundamental unit of organisation in Apache Kafka and a storage mechanism for a sequence of events. Essentially, topics are durable log files that keep events in the same order as they occur in time. So, each new event is always added to the end of the log. Additionally, events are immutable. Thus, we can’t change them after they’ve been added to a topic.
As a developer using Kafka, the topic is the abstraction you probably think the most about. You create different topics to hold different kinds of events and different topics to hold filtered and transformed versions of the same kind of event.
For example, if you’re recording a sequence of temperature measurements for a room, once a temperature value has been recorded, like 21°C at 5:02 PM, it cannot be altered as it has already occurred. Furthermore, a temperature value at 5:06 PM cannot precede the one recorded at 5:02 PM. Hence, by treating each temperature measurement as an event, a Kafka topic would be a suitable option to store that data.
Every topic can be configured to expire data after it has reached a certain age (or the topic overall has reached a certain size), from as short as seconds to as long as years or even to retain messages indefinitely. The logs that underlie Kafka topics are files stored on disk. When you write an event to a topic, it is as durable as it would be if you had written it to any database you ever trusted.
Partitions
In Apache Kafka, partitions are the main method of concurrency for topics and to improve scalability. A topic, which is a dedicated location for events or messages, is broken into multiple partitions among one or more Kafka brokers.
A partition in Kafka is the storage unit that allows for a topic log to be separated into multiple logs and distributed over the Kafka cluster. Partitions allow Kafka clusters to scale smoothly. They are the basic unit of data storage and distribution within Kafka topics.
By default, a topic is created with only 1 partition and whatever messages are published to this topic are stored in that partition. If you configure a topic to have multiple partitions then the messages sent by the producers would be stored in these partitions such that no two partitions would have the same message/event. All the partitions in a topic would also have their own offsets.
Kafka uses topic partitioning to improve scalability. In partitioning a topic, Kafka breaks it into fractions and stores each of them in different nodes of its distributed system. That number of fractions is determined by us or by the cluster default configurations. Kafka guarantees the order of the events within the same topic partition. However, by default, it does not guarantee the order of events across all partitions.
For example, to improve performance, we can divide the topic into two different partitions and read from them on the consumer side. In that case, a consumer reads the events in the same order they arrived at the same partition. In contrast, if Kafka delivers two events to different partitions, we can’t guarantee that the consumer reads the events in the same order they were produced. To improve the ordering of events, we can set an event key to the event object. With that, events with the same key are assigned to the same partition, which is ordered. Thus, events with the same key arrive at the consumer side in the same order they were produced.
Producer
An Kafka Producer is a client application that publishes (writes) events to a Kafka cluster. Here are some key points about a Kafka Producer:
Partitioning: A producer partitioner maps each message to a topic partition, and the producer sends a produce request to the leader of that partition. The partitioners shipped with Kafka guarantee that all messages with the same non-empty key will be sent to the same partition.
Message Delivery: Depending on how the producer is configured, each produce request to the partition leader can be held until the replicas have successfully acknowledged the write. This gives the producer some control over message durability at some cost to overall throughput.
Batching: The record is added to a batch of records that will also be sent to the same topic and partition. A separate thread is responsible for sending the batch to the appropriate Kafka brokers.
Response from Broker: When the broker receives the messages, it sends back a response to the Producer. If the messages were successfully written to Kafka, the broker will return a RecordMetadata object.
In practice, most of the subtlety around producers is tied to achieving high throughput with batching/compression and ensuring message delivery guarantees.
Consumer
An Apache Kafka Consumer is a client application that subscribes to (reads and processes) events from Kafka topics. Here are some key points about a Kafka Consumer:
Fetch Requests: The Kafka consumer works by issuing “fetch” requests to the brokers leading the partitions it wants to consume. The consumer offset is specified in the log with each request. The consumer receives back a chunk of log that contains all of the messages in that topic beginning from the offset position.
Consumer Groups: A consumer group is a set of consumers that cooperate to consume data from some topics. The partitions of all the topics are divided among the consumers in the group. As new group members arrive and old members leave, the partitions are re-assigned so that each member receives a proportional share of the partitions. This is known as rebalancing the group.
Offset Management: After the consumer receives its assignment from the coordinator, it must determine the initial position for each assigned partition.
Push vs Pull Design: Kafka follows a traditional messaging system design in that data is pushed by the producer to the broker and pulled from the broker by the consumer. An advantage of a pull-based system is that if a consumer falls behind production, they can catch up.
ZooKeeper
ZooKeeper is an important component of a Kafka cluster that acts as a distributed coordination service. ZooKeeper is in charge of monitoring and preserving the cluster’s metadata, coordinating the operations of many nodes, and assuring the general stability and consistency of the Kafka cluster. It stores the list of brokers that are currently active and that belong to the cluster.
Here are some key roles of ZooKeeper in a Kafka cluster:
Cluster Coordination: ZooKeeper keeps track of the active brokers in the cluster, as well as their connectivity and state. Each broker registers with ZooKeeper, making it possible for other brokers and clients to find and connect with them.
Controller Election: ZooKeeper is used in the Kafka cluster to elect a controller node. The controller is responsible for partition leader election, partition reassignment, and cluster-wide metadata management.
Metadata Management: ZooKeeper maintains and manages important metadata about topics, partitions, and their related leader/follower information.
Records
In Kafka, each record (also referred to as a message) consists of a key, a value, and a timestamp and it is the fundamental unit of data. The key and value are both byte arrays and can contain any data. Records are stored accurately (i.e., in the order in which they occurred) in a fault-tolerant and durable way. It enables applications to publish or subscribe to data or event streams. Records are categorised into topics and stored in Kafka clusters. A topic is divided into one or more partitions that are distributed among the Kafka Cluster. Each record in a partition is assigned a unique, monotonically increasing identifier called an offset. The offset helps identify the position of a record within the partition.
Here are some key points about records in Kafka:
Immutable: Once a record is written to a partition, it can’t be changed.
Order Preserved: Records are appended to the end of the partition in the order they are written.
Consumption: Consumers read records from a topic at their own pace.
Retention: Records are retained for a configurable amount of time, regardless of whether they have been consumed.
Streams
Kafka Streams is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka’s server-side cluster technology.
Here are some key features of Kafka Streams:
Elastic, highly scalable, fault-tolerant: It can be deployed to containers, VMs, bare metal, or cloud.
Fully integrated with Kafka security: It provides exactly-once processing semantics.
No separate processing cluster required: You can develop on Mac, Linux, Windows.
Abstraction over producers and consumers: Kafka Streams lets you ignore low-level details and focus on processing your Kafka data.
Declarative: Processing code written in Kafka Streams is far more concise than the same code would be if written using the low-level Kafka clients.
Schema Registry
The Schema Registry in Kafka is a standalone server process that runs on a machine external to the Kafka brokers. It provides a centralised repository for managing and validating schemas for topic message data, and for serialisation and deserialisation of the data over the network. Producers and consumers to Kafka topics can use schemas to ensure data consistency and compatibility as schemas evolve.
Here are some key features of the Schema Registry:
Data Validation: It validates the data being sent to Kafka.
Compatibility Checking: It checks if the data is compatible with the expected schema.
Versioning and Evolution: It allows schemas to evolve over time while ensuring compatibility.
Centralised Repository: It provides a centralised repository for managing schemas.
Pros and Cons of Apache Kafka
Apache Kafka is a powerful, open-source, distributed streaming platform that is used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications. However, like any technology, it has its strengths and weaknesses. Here’s a detailed look at the pros and cons of Apache Kafka.
Pros of Apache Kafka
Low Latency: Apache Kafka offers low latency, i.e., up to 10 milliseconds. This is because it decouples the message, which lets the consumer consume the message anytime.
High Throughput: Due to low latency, Kafka can handle a high volume and velocity of messages. Kafka can support thousands of messages in a second.
Fault Tolerance: Kafka provides resistance to node/machine failure within the cluster.
Durability: Kafka offers the replication feature, which makes data or messages persist more on the cluster over a disk. This makes it durable.
Scalability: The quality of Kafka to handle a large number of messages simultaneously makes it a scalable software product.
Real-Time Handling: Apache Kafka is able to handle real-time data pipeline.
Distributed System: Apache Kafka contains a distributed architecture which makes it scalable.
Cons of Apache Kafka
Lack of Monitoring Tools: Apache Kafka does not contain a complete set of monitoring and managing tools. Thus, new startups or enterprises fear to work with Kafka.
Message Tweaking Issues: The Kafka broker uses system calls to deliver messages to the consumer. In case, the message needs some tweaking, the performance of Kafka gets significantly reduced.
No Wildcard Topic Selection: Apache Kafka does not support wildcard topic selection. Instead, it matches only the exact topic name.
Performance Reduction: Brokers and consumers reduce the performance of Kafka by compressing and decompressing the data flow.
Clumsy Behaviour: Apache Kafka most often behaves a bit clumsy when the number of queues increases in the Kafka Cluster.
Lack of Some Message Paradigms: Certain message paradigms such as point-to-point queues, request/reply, etc. are missing in Kafka for some use cases.
In conclusion, while Apache Kafka is a powerful messaging system that offers high scalability, high-throughput, low-latency platform and fault tolerance, it also has its own set of disadvantages, including complexity, operational overhead, message ordering, message size limitations, and dependency on Zookeeper. Its storage layer is designed to store data efficiently and is a distributed system such that if your storage needs grow over time you can easily scale out the system to accommodate the growth.
Subscribe to my newsletter
Read articles from Sandeep Choudhary directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by