Kubernetes Stateful Sets
 Aniket Kurkute
Aniket Kurkute
"Kubernetes StatefulSets are similar to Kubernetes Deployments, but they have extra features to help deploy stateful applications."
OR
"Kubernetes stateful sets are improved versions of Kubernetes Deployments."
Stateful vs Stateless Applications
Stateful applications need persistent storage to store and process data, such as databases like MySQL and MongoDB. On the other hand, stateless applications don't require persistent storage; they simply forward requests to stateful applications. Examples of stateless applications include web servers like Nginx, Tomcat, any of your front-end services, etc.
Drawbacks of using Kubernetes Deployments to deploy a stateful application
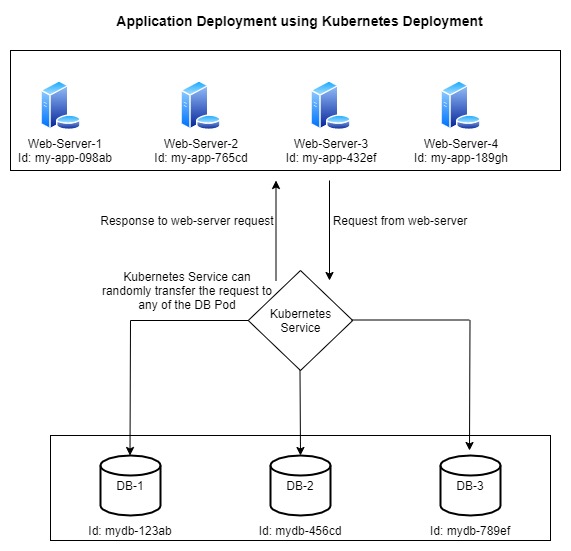
For high availability, we generally maintain multiple replicas of the resources.
In the above diagram as you can see the request flows from Web servers to the Kubernetes Service which then forwards it to the DB pods, now this k8s service forwards any random request to any random DB, so there might come a case wherein a user signs up for the application and his/her data is stored in DB-1(Id: mydb-123ab). The next time the user tries to log in, the k8s services forwards the request to DB-2(Id: mydb-456cd), so in this case the application will fail to retrieve the user info, asking the user to re-register.
In a nutshell, if we deploy a stateful application using a Kubernetes deployment, there will be no data consistency across the DB pods since the data is not updated in each pod. This will eventually lead to application failure.
One alternative solution for data consistency across DB pods is shown in the diagram below. We can assign one of the DB pods as a central pod, and the rest can sync their data from it.
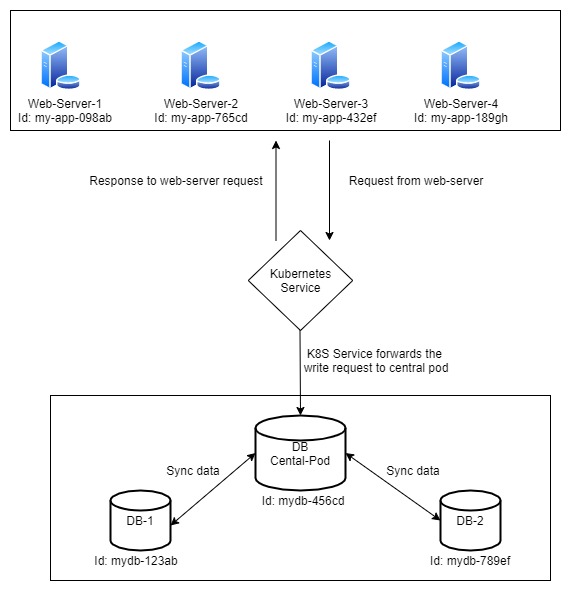
In this approach, helper pods sync data from the central pod. The association between helper pods and the central pod is done using either the IP address or the unique pod IDs. This method works as long as the central pod is up and running. However, if the central pod goes down, a new central pod will come up with a new IP address and a new pod ID. As a result, the association between the helper pods and the new central pod will fail, leading to application failure.
These are the drawbacks of using Kubernetes deployments for stateful applications. These issues are addressed by using Kubernetes StatefulSets.
How Kubernetes Stateful sets help in deploying a stateful application
So, as mentioned earlier, StatefulSets are similar to Kubernetes deployments but with some additional features. These features help solve the identity problem that comes with Kubernetes deployments (as explained in the earlier section).
StatefulSets assign a unique identity to each pod, starting from 0. When a new pod is created, it syncs data from the previous pod. For example, mydb-1 syncs from the primary/central pod (mydb-0), mydb-2 syncs from mydb-1, and so on. Once the data syncing is complete and the pod is running, it will connect to the central pod for ongoing syncing. This means the initial data sync happens through the previous pod in the sequence. If the previous pod is in a pending state, the new pod will not be created.
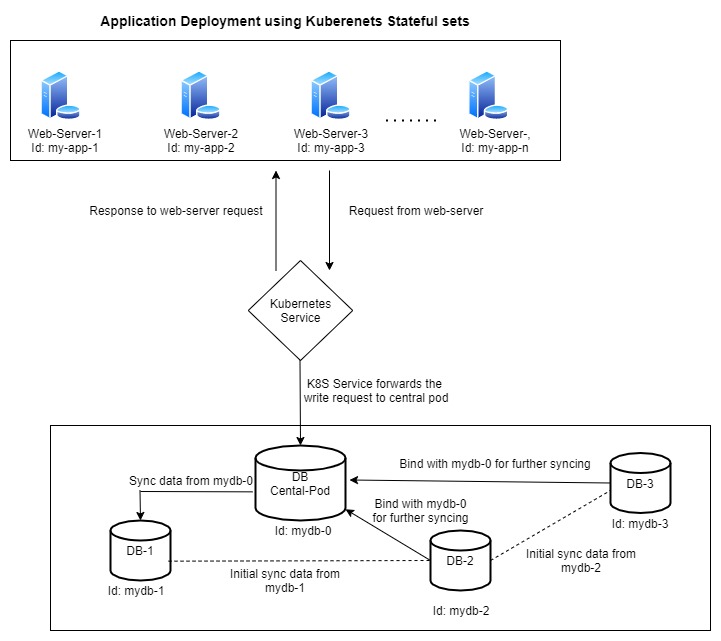
Here, mydb-0 is the central pod that receives write requests from the Kubernetes service. For high availability, when we request a new pod, mydb-1 will be created. Before its creation, Kubernetes ensures it syncs data from mydb-0 and binds mydb-1 to mydb-0 for further syncing. Similarly, mydb-2 will initially sync data from mydb-1 and bind itself to the central pod (mydb-0). In the same way, mydb-3 will initially sync from mydb-2 and bind itself to mydb-0 for further syncing. This process continues in the same manner.
When downscaling the application, Kubernetes will always delete pods in reverse order. For example, if there are 5 pods, mydb-4 will be deleted first, not mydb-0. This ensures that the first pod, the central pod, is always available for other pods and is the last one to be removed.
In this approach, it is always ensured that the new database pod being created will have the latest data before it starts syncing with the central pod. This way, there will be no data inconsistency if the Kubernetes service transfers the read request to any of the database pods. The application will be highly available to all users.
NOTE: Stateful sets attach a PersistenVolumeClaim attached with each Pod.
Stateful sets vs Deployments
As mentioned earlier, Kubernetes Stateful Sets are similar to Kubernetes Deployments, but there are some differences you need to be aware of.
| Stateful Sets | Deployments |
| Used to deploy stateful applications | Used to deploy stateless applications |
| Every pod is assigned a persistent volume | No persistent volume is required as there is no need for persistent storage |
| Stateful sets identify the pods in an ordered manner. | There is no ordered identification in Kubernetes deployments |
| Updates take place in a sequential and ordered manner | Updates take place in an unordered way |
| Examples: Databases | Examples: Webservers, Frontend deployments, etc |
Subscribe to my newsletter
Read articles from Aniket Kurkute directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by