Serial vs Parallel: A Comparative Study in Computing Efficiency using Machine Learning algorithms.
 Likesh K
Likesh KIn the exploration of computing efficiency, the comparison between serial and parallel processing stands as a pivotal discussion point. This blog delves into the core differences, advantages, and applications of each approach, aiming to shed light on how they shape computing tasks and overall efficiency. Additionally, we will explore by using Machine Learning algorithms in Serial & Parallel processing to do a Comparative Study between these two approaches.
Before diving into the comparative study, let’s briefly outline the algorithms at the heart of this exploration:
K-Nearest Neighbors (KNN): A simple, yet powerful algorithm that classifies new cases based on a similarity measure (e.g., distance functions) with known cases.Random Forest: An ensemble learning method for classification and regression that operates by constructing a multitude of decision trees at training time to output the mode of the classes (classification) or mean prediction (regression) of the individual trees.Regression Analysis: A statistical method for modeling the relationship between a dependent variable and one or more independent variables, allowing for predictions of trends and future values.
Serial vs. Parallel Processing: A Duel of Efficiencies
The execution of ML algorithms in serial processing environments processes data sequentially, handling one operation at a time. While this method ensures simplicity and straightforward implementation, it often leads to increased computation times, especially with large datasets or complex algorithms like Random Forest.

Conversely, parallel processing divides the dataset and computations across multiple processors, enabling simultaneous execution of tasks. This approach can significantly reduce the time required for training ML models, making it especially beneficial for algorithms that can be easily parallelized, such as Random Forest and KNN.
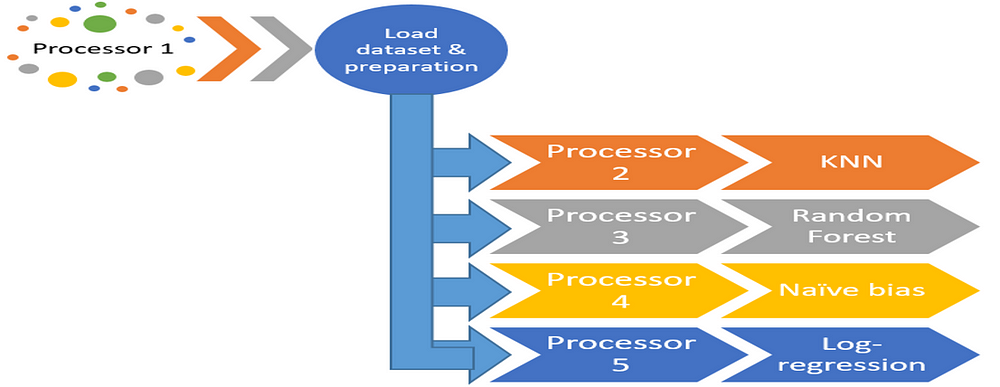
Methodology
The methodology for this research involves a detailed and structured approach to compare the performance of serial and parallel processing across multiple computational tasks. Here is a comprehensive overview of the algorithms used, input data types and sources, and the systematic process employed for both implementation and evaluation:
A. Algorithms Used To provide a comprehensive comparison, the study encompasses a range of algorithms across different areas of computing:
Machine Learning Algorithms: k-Nearest Neighbors (kNN): Used for classification by analyzing the distance between different points.Logistic Regression: Employed for binary classification by modeling the probabilities for classification problems.
General Computational Tasks: Matrix Multiplication: Fundamental in various applications, particularly in graphics and numerical simulation. Array Summation: Basic operation used to test computational efficiency on simple iterative tasks. Image Processing: Tasks such as filtering and edge detection to analyze parallel processing in data-intensive tasks.
Sorting Algorithms: Including quicksort and Mergesort to evaluate the efficiency of sorting operations in parallel. String Concatenation: To assess how both processing types handle large-scale data concatenation operations.
RESULTS AND ANALYSIS
A. Addressing the Research Questions Based on the experiments conducted, the results and subsequent analysis provide insights into the efficiency of parallel versus serial processing for different computational tasks. The research questions set forth in the study guide the presentation and interpretation of the findings:
1) Comparative Execution Time: Does parallel processing significantly reduce execution times compared to serial processing across various algorithms such as kNN, Logistic Regression, and Matrix Multiplication?
2) Efficiency Gains: What efficiency gains are observable when applying parallel processing, and how do these vary across different types of algorithms?
3) Influencing Factors: Which factors most significantly influence the performance improvements observed in parallel processing compared to serial processing?
4) Scalability and Challenges: How does the scalability of parallel processing manifest across different computational tasks, and what challenges are encountered?
B. Experiments Conducted Two primary experiments were conducted
Experiment 1 - Execution Time Comparison - Setup: Each algorithm was run on datasets of increasing size, from small to very large, to test scalability. - Serial vs. Parallel: Each task was executed using serial processing and then with parallel processing using Java’s concurrency frameworks.
Experiment 2 - Scalability and Overhead Analysis - Setup: The focus was on understanding how the parallel processing scales with increasing number of threads and processors. - Measurement: The overhead introduced by parallel processing was also measured to determine its impact on performance gains.
C. Results: Figures and Tables
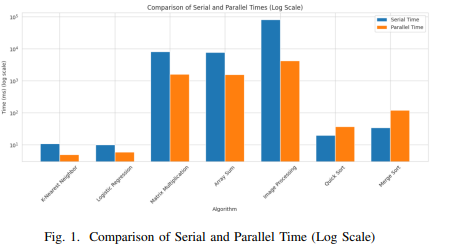
In conclusion, this research provides a comprehensive evaluation of the performance benefits of parallel processing compared to traditional serial processing across a variety of computational tasks and machine learning algorithms. The speed-up factors calculated from our experiments demonstrate significant improvements in efficiency for the majority of tasks when utilizing parallel processing strategies in a multiprocessor environment.For computationally intensive tasks such as Matrix Multiplication, Array Summation, and Image Processing, we observed substantial reductions in execution time, with speed-up factors ranging from approximately 4.84 to 19.06. This underscores the potential of parallel processing techniques in handling large-scale data and complex calculations, aligning with the increasing demand for real-time data processing capabilities. In contrast, for sorting algorithms like Quick Sort and Merge Sort, the parallel implementations underperformed compared to their serial counterparts. This highlights the inherent complexities and challenges associated with parallelizing certain algorithms that have intricate data dependencies or require significant inter-thread communication, which can introduce additional overheads and diminish the benefits of parallel execution.
Subscribe to my newsletter
Read articles from Likesh K directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by