Organizing movie collection with machine learning
 kapil Garg
kapil Garg
If you have downloaded movies from internet sources, chances are that those video file names' contains a lot of garbage in it.
Oppenheimer.2023.1080p.LM.HD-TeleSync.DUAL.DD2.0.H.264-xCLuMsYx.mkv
Minions The Rise of Gru 2022 BluRay ReMux 1080p AVC TrueHD 7.1 DTS AC3-MgB.mkv (22294327228 bytes)
If you like to keep your collection neat and tidy, may be you update those names manually. But why not use machine learning to do that !!
Idea is to create an ner model and use it to identify movie name out of a file name. These names are not like an english language sentence which spacy process with nlp but these are not random either. Hopefully spacy will be able to process these.
To create a custom ner model, we need data to train it. Each file name that we use for training, we need to provide it with annotation which identifies the movie name in it.
We use spacy for that and start with en-core-web-sm model.
Step 1 : Install spacy and en-core-web-sm
pip install spacy
python -m spacy download en_core_web_sm
Step 2: Prepare training data
In order to train the model, First we need to prepare the data. Let's call the entity, that we want to identify, movie. Our training data should look like this-
For each file name, training data consists of a list of entities. Each element in the entities list marks the start and end of the entity and entity name.
I'm using dataset available at Kaggle . It is not exhaustive but it will do.
Step 3 : Load the model and create a pipeline for NER
Step 3.1 : add entity ruler (optional)
There are other components in file name which may be of interest, like resolution (1080p, 720p) or source (Blu Ray, Web Rip) etc. It will be easier to capture these using entity ruler.
The
EntityRuleris a component that lets you add named entities based on pattern dictionaries, which makes it easy to combine rule-based and statistical named entity recognition for even more powerful pipelines.
Step 4 : Train the model
Since we are training ner, we don't need other pipe lines.
We are done with creating the model. We can test it now .
Step 5 : Test the model
To test it, we need to load this model and pass the file name. In return it should identify the movie name and other entities (which we added using entity ruler)
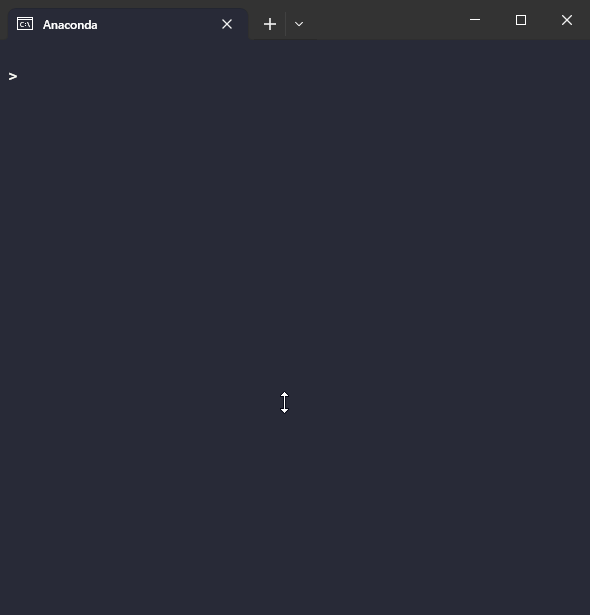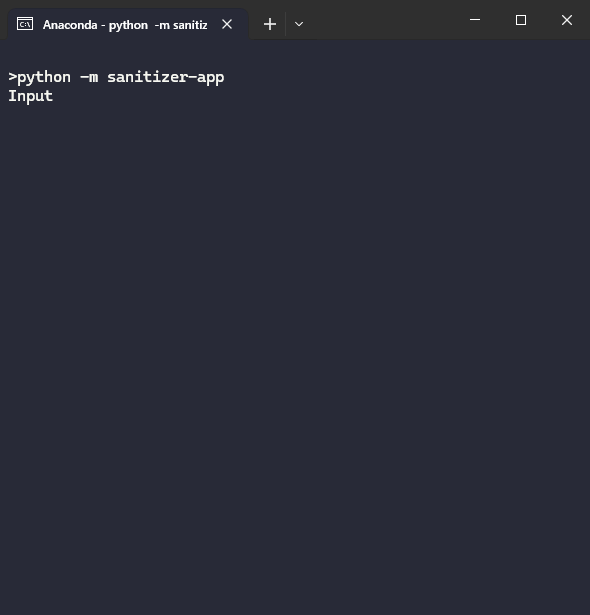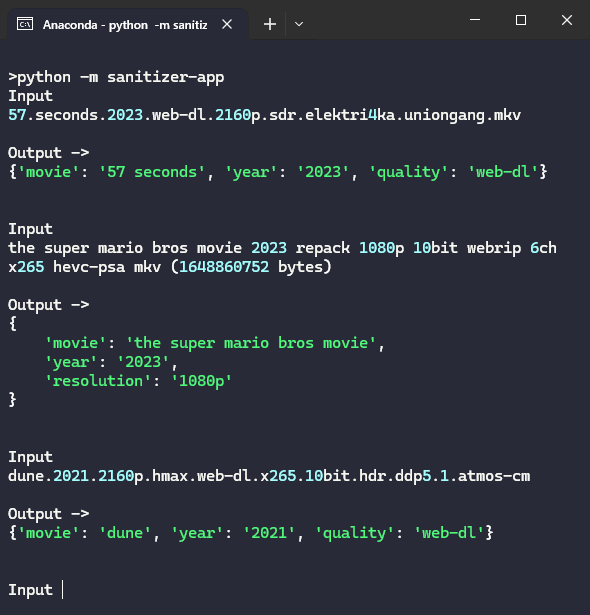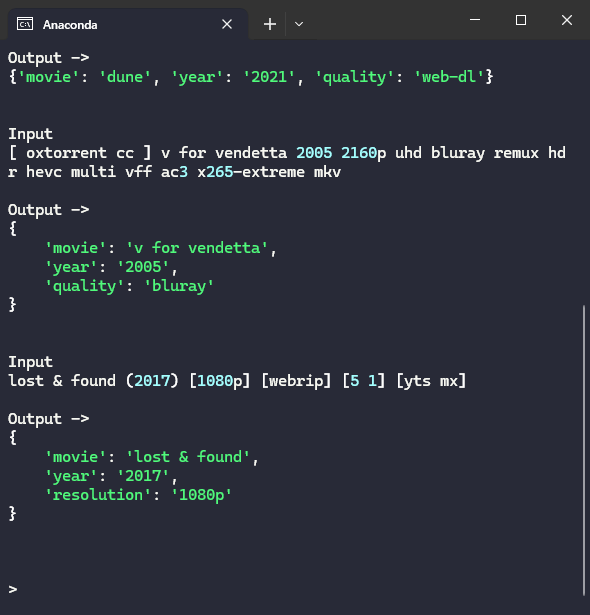
That's it. We have our working app which can successfully identify the movies from file name.
Full source code is available at GitHub.
Thanks for reading!
Subscribe to my newsletter
Read articles from kapil Garg directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by