Mastering the groupby() Method in Pandas: A Comprehensive Guide
 Sheema Bakhtiar
Sheema Bakhtiar
Pandas is a powerful data manipulation library in Python, and one of its most useful functions is groupby(). This method allows you to group data and perform operations on these groups, making it an essential tool for data analysis. In this blog post, we’ll dive deep into the groupby() method, explaining its use cases and showing you how to leverage it effectively.
What is groupby() in Pandas?
The groupby() method is used to split the data into groups based on some criteria. Pandas’ groupby() works similarly to SQL’s GROUP BY statement. It’s often used in conjunction with aggregation functions like sum(), mean(), count(), etc., to summarize data. Here's a basic example:
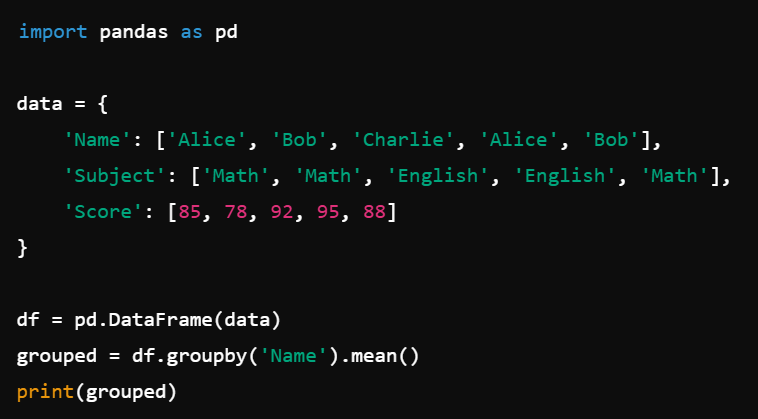
This code will group the data by the Name column and calculate the mean score for each name.
When to Use groupby():
The groupby() method is particularly useful in the following scenarios:
Aggregating Data: When you need to summarize data, such as finding the average, sum, or count of a group.
Segmented Analysis: When you want to analyze subsets of your data independently.
Data Transformation: When you need to transform data by applying a function to each group independently.
Handling Duplicate Values: When your dataset has duplicate values and you need to analyze these duplicates separately.
Detailed Use Cases:
1. Aggregating Data:
Aggregation is one of the most common uses of groupby(). It allows you to perform various calculations on grouped data. Here’s an example:
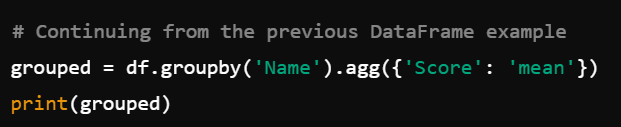
In this case, agg() allows for more flexibility, enabling different aggregation functions for different columns.
2. Grouping by Multiple Columns:
You can group by more than one column to perform more complex analyses. For example:

This will calculate the mean score for each combination of Name and Subject.
3. Filtering Groups:
Sometimes, you only want to perform operations on groups that meet certain criteria. You can filter these groups using the filter() method:

This code will only include groups where the mean score is greater than 80.
4. Applying Custom Functions:
You can apply custom functions to each group using the apply() method:

This will add 10 to the mean score of each group.
5. Transforming Data
If you want to apply a function to each group but maintain the original DataFrame shape, you can use the transform() method:

This code subtracts the mean score from each score in the group.
Tips for Using groupby()
Choosing the Right Aggregation Function: Depending on your analysis, you might use
sum(),mean(),count(),max(),min(), etc. Choose the one that best fits your needs.Handling Missing Data:
groupby()works well with missing data, but be mindful of how missing values might affect your calculations.Performance Considerations: Grouping large datasets can be computationally expensive. Ensure your machine has enough memory to handle large operations.
Start experimenting with
groupby()in your own projects to see just how powerful this method can be. Happy coding!
Subscribe to my newsletter
Read articles from Sheema Bakhtiar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sheema Bakhtiar
Sheema Bakhtiar
HELLO THERE!👋🏻 I Am Sheema Bakhtiar, An Enthusiastic beginner in the tech field, eager to embark on a journey of learning and growth. Currently building a foundation in software development(web dev both front and back end) as well as Data science