Quarkus para principiantes: Crea tu primer API REST
 Saul Vazquez
Saul VazquezTable of contents
- Introducción
- Prerrequisitos
- Especificaciones
- Configura una base de datos
- Procedimiento
- Prueba la aplicación
- Bonus: Construcción de la Container Image de la aplicación (Opcional)
- Paso 1: Modifica la referencia a la base de datos en el archivo application.properties
- Paso 2: Compila la aplicación a binario nativo
- Paso 3: Crea la imagen de contenedor
- Paso 4: Crea un pod para desplegar los contenedores
- Paso 5: Crea y configura la base de datos en el pod
- Paso 6: Despliega la aplicación contenerizada en el pod
- Paso 7: Elimina los contenedores desplegados
- Paso 8: Almacena la imagen en un registro de imágenes (opcional)
- Conclusiones
- Referencias

Introducción
La mayoría de los sistemas hoy día se basan en el modelo cliente-servidor, predominantemente constituido por APIs a atreves de las cuales las organizaciones exponen sus servicios digitales tanto para usuario internos como externos. Sin embargo, el stack de tecnologías disponibles en el mercado no se ha mantenido estático, se ha modernizado dando prestaciones correspondientes a los tiempo que corren. Nada después del nacimiento de AWS y Kubernetes volvió a ser como antes.
Cuando nace la nube con ella nace la necesidad de actualizar las tecnologías de desarrollo. Las aplicaciones cloud-native son aplicaciones capaces de desenvolverse en plataformas de proveedores de servicios de nube, como AWS, Azure o GCP, y a la vez aprovechar las nuevas prestaciones que estas ofrecen. En términos simples, una aplicación cloud-native es aquella aplicación que tiene capacidades como autoescalamiento, self healing, actualizaciones automáticas, rollbacks, etcétera; y no solo que este corriendo en alguna nube publica.
Es en este contexto es en el que nace Quarkus, que se creó para permitir a los desarrolladores Java crear aplicaciones para un mundo moderno y nativo de la nube. Quarkus es un framework de Java nativo de Kubernetes creado a partir de las mejores bibliotecas y estándares Java, permitiendo a la industria aprovechar la base de conocimiento de Java en el desarrollo de aplicativos nativos de nube, minimizando la curva de aprendizaje de los desarrolladores ya existentes. El objetivo es hacer de Java la plataforma líder en Kubernetes y entornos sin servidor, al tiempo que ofrece a los desarrolladores un marco para abordar una gama más amplia de arquitecturas de aplicaciones distribuidas.
El gran elefante en la habitación es Kubernetes, todos lo hemos escuchado pero nunca se le dedica el tiempo suficiente para estudiarlo, entenderlo y dominarlo. Kubernetes nace en 2014 como respuesta por parte Google a Docker y a AWS por la gran popularidad que iban ganando. Kubernetes, definido por su propia pagina, es:
"Kubernetes is a portable, extensible, open source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation."
Los orquestadores de contenedores, como Kubernetes, son sistemas o plataformas que despliegan aplicaciones y responden a cambios de forma dinámica. Por ejemplo, Kubernetes puede:
Desplegar aplicaciones.
Escalar o desescalar aplicaciones bajo demanda.
Autoreparar las aplicaciones cuando se rompen.
Realizar actualizaciones y aplicar rollbacks con zero-downtime.
Y mucho más.
Al final del día, de las características más importantes de Kubernetes es su capacidad de abstraer la infraestructura subyacente al cluster. Abstrae las diferencias que hay entre las plataformas de nube de la misma manera en la que un sistema operativo como GNU/Linux o Windows lo hacen. Es por eso que algunas veces se le suele referir a Kubernetes como "el sistema operativo de la nube".
Es por esto que desde la concepción de las aplicaciones que desarrollemos debemos tener en mente desarrollarlas como Kubernetes native, que podemos hacer gracias a tecnologías como Quarkus, que es container-first; y Podman, que nos permite manejar el ciclo de vida no solo con contenedores, sino directamente trabajar con "pods" (un conjunto de uno o más contenedores) que son las unidades mínimas que administra Kubernetes.
Prerrequisitos
Como prerequisitorios se asumen conocimientos básicos de Java y de bases de datos relacionales, de preferencia experiencia con PostgreSQL aunque no es necesario si es deseable para entender la configuración que se va a hacer sobre la base de datos.
A lo largo de esta guía se van a utilizar varios comando de terminal, por lo que se espera que tengas cierta familiaridad con al linea de comandos.
Tanto para el despliegues de la base de datos, como en la sección bonus, para la contenerización de la aplicación, estarás utilizando Podman, que es una herramienta de código abierto para desarrollar, gestionar y ejecutar contenedores. Sin embargo, también puedes utilizar Docker. Por lo que para estas secciones, sería deseable que conocieras lo básico de contenedores. Sin embargo, puedes desplegar tú tu base de datos por cualquier otro mecanismo de tu preferencia e ignorar la última sección de bonus.
Especificaciones
A manera de referencia, a continuación te voy a listar los detalles de las herramientas que se utilizaron durante el desarrollo de este tutorial. Sin embargo, no es necesario que tengas estas configuraciones para poder realizar esta guía exitosamente. Ya que a pesar de que para el momento en el que estés leyendo este manual las ultimas versiones de las respectivas tecnologías sean superiores, es altamente probable que haya compatibilidad con versiones anteriores.
Igualmente, a pesar de que esta pruebas se realizaron en un dispositivo Linux, debe ser replicable en un equipo Windows o iOS teniendo las herramientas correctamente configuradas.
| Componente | Detalles |
| Sistema Operativo | Fedora Linux 40 |
| Versión Quarkus | 3.11 |
| JDK | OpenJDK 21.0.3 |
| Versión PostgreSQL | 16 |
| Gestor de proyectos | Apache Maven 3.9.6 |
| Engine de contenedores | Podman 5.1.0 |
| IDE | IntelliJ IDEA 2024.1.3 (Community Edition) |
Configura una base de datos
A continuación se va a mostrar como puedes desplegar tu base de datos desde cero utilizando Podman.
Sin embargo, si quieres utilizar alguna otra base de datos, siéntete con la libertad de poder utilizarla, siempre y cuando pueda ser alcanzada desde el dispositivo en el que estarás realizando el tutorial.
Paso 1: Verifica que tengas un engine de contenedores
Puedes utilizar tanto Podman como Docker como tu engine de contenedores (software capaz de crear y administrar el ciclo de vida de los contenedores) para trabajar con contenedores a lo largo de este tutorial.
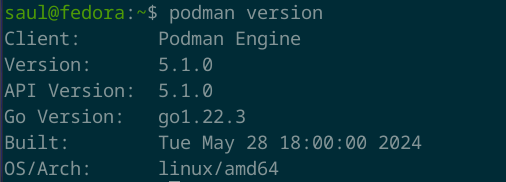
Si tu, al igual que yo, también has decidido utilizar Podman, puedes utilizar el siguiente comando que consulta la versión de Podman y verificar que lo tienes instalado.
podman version
Por otro lado, si has preferido utilizar Docker, utilizarías el siguiente comando:
docker version
Paso 2: Descarga la imagen de la base de datos (PostgreSQL)
Por la parte de la base de datos, te recomiendo utilizar (para mantener la consistencia con el resto de la presente guía) la base de dato PostgreSQL. Aunque podrías utilizar cualquier otra base de datos soportada por Quarkus.
Por su facilidad de uso, vas a utilizar la versión contenerizada de la imagen oficial de PostgreSQL que se encuentra en Docker Hub.
Si estas utilizando Docker, puedes encontrar el comando para descargar esta imagen de lado derecho, que sería el siguiente.
docker pull postgres
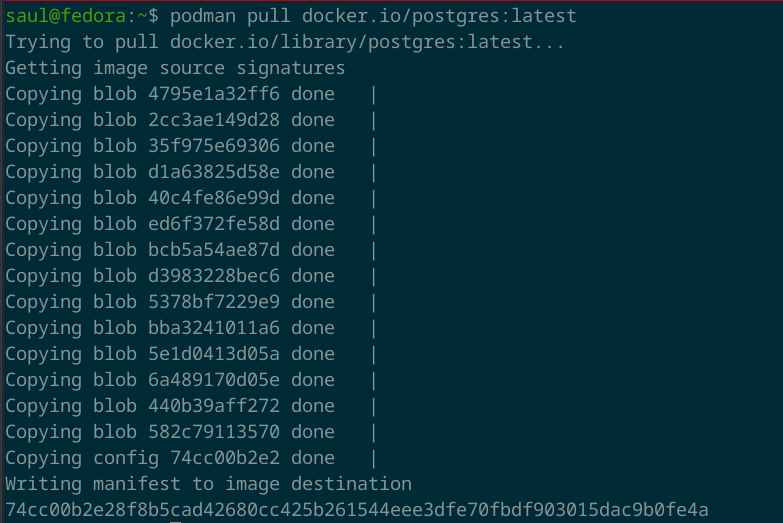
O si estas utilizando Podman, utilizarías el siguiente comando. En el que, a diferencia del comando para Docker, le vas a agregar el nombre del registro de la imagen, que para el caso de Docker Hub sería docker.io.
podman pull docker.io/postgres:latest
Paso 3: Levanta la base de datos
Vas a utilizar la configuración mostrada en la siguiente tabla para crear la base de datos en un contenedor con la imagen que acabas de descargar de Docker Hub.
| Elemento | Valor |
| Nombre del contenedor | postgres-database |
| Nombre de la base de datos | db |
| Usuario | dev |
| Contraseña | passw0rd |
| Imagen del contenedor | postgres:latest |
Vas a pasar esta configuración como parámetros en el comando de podman run, o en docker run en el caso de Docker, como se muestra en el siguiente comando.
podman run -d --name postgres-database -p 5432:5432 -e POSTGRES_PASSWORD=passw0rd -e POSTGRES_USER=dev -e POSTGRES_DB=db postgres:latest

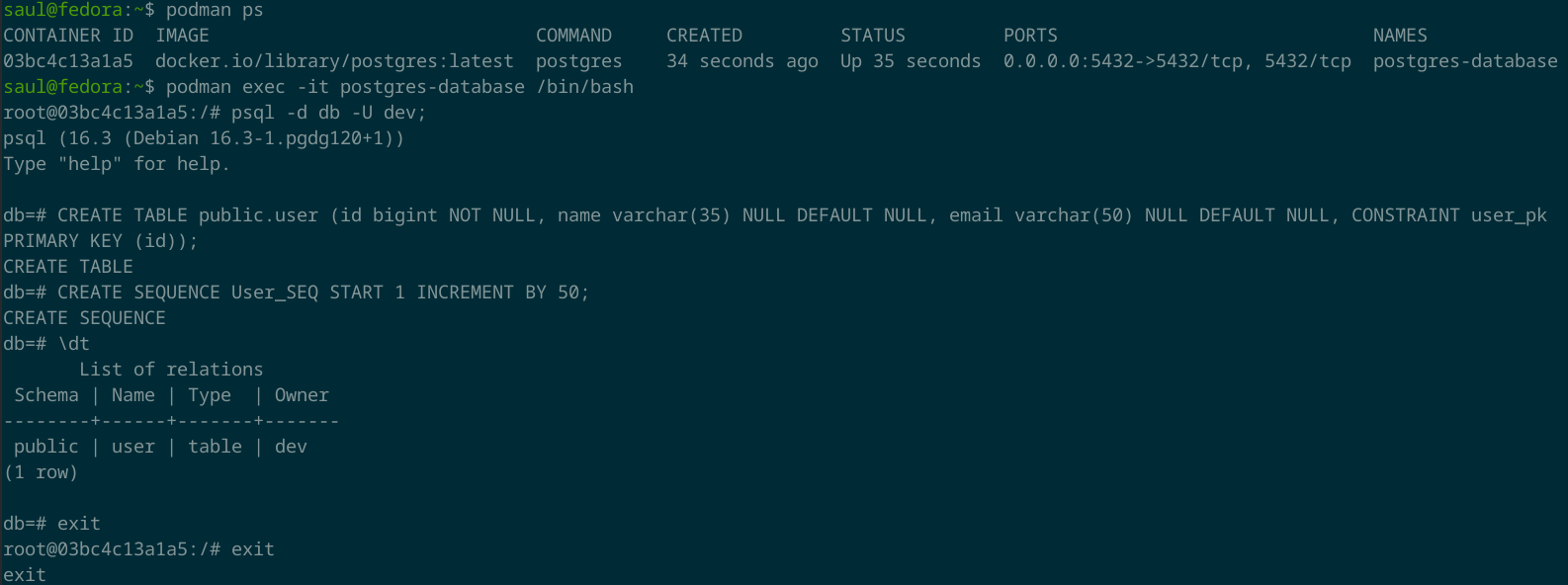
Podemos listar con podman ps los contenedores que se encuentran corriendo. Con lo que confirmas que tienes corriendo tu base de datos.
podman ps

Paso 4: Configura la base de datos
Para la configuración del esquema de la base de datos, vas a crear una tabla llamada user con las 3 columnas que se muestran a continuación.
| Nombre | Tipo de dato |
| id | BIGINT |
| name | VARCHAR(35) |
VARCHAR(50) |
Para aplicar esta configuración, vas a iniciar una terminal interactiva del contenedor de la base de datos PostgreSQL que acabas de crear, utilizando el comando podman exec.
podman exec -it postgres-database /bin/bash
Una vez estando en la terminal del contenedor, vas a utilizar el cliente psql, para iniciar sesión en la base se datos.
psql -d db -U dev;
Después de autenticarte como el usuario dev vas a crear la tabla user en el esquema public, y una secuencia (que es necesaria para poder utilizar Hibernate ORM con Panache que usarás más adelante).
Copia y pega los siguientes comandos para realizar esto.
CREATE TABLE public.user (id bigint NOT NULL, name varchar(35) NULL DEFAULT NULL, email varchar(50) NULL DEFAULT NULL, CONSTRAINT user_pk PRIMARY KEY (id));
CREATE SEQUENCE User_SEQ START 1 INCREMENT BY 50;
Con el comando \dt puedes imprimir la lista de las tablas, y debería ver la tabla que acabas de crear.
\dt
Después sal de la sesión de PostgreSQL y del contenedor con el comando exit.
exit
exit
Procedimiento
Paso 1: Genera la estructura del proyecto
Vas a utilizar la herramienta web de Quarkus para generación de proyectos.
Ve a: https://code.quarkus.io
Utiliza los siguientes valores para llenar los campos para mantener la consistencia con el manual.
| Campo | Valor |
| Group | com.redhat |
| Artifact | my-quarkus-api-rest |
| Build Tool | Maven |
| Version | 1.0.0-SNAPSHOT |
| Java Versión | 21 |
| Starter Code | No |
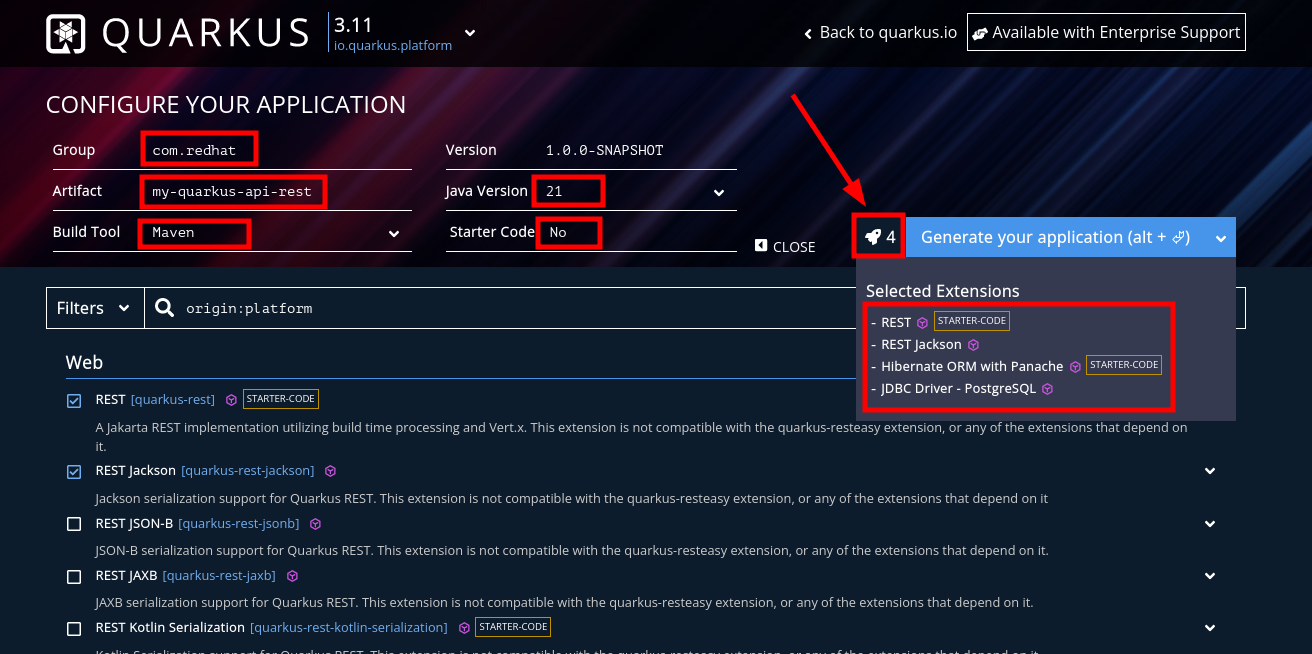
Agrega aquí mismo las 4 extensiones que vas a utilizar en la aplicación.
REST [
quarkus-rest]REST Jackson [
quarkus-rest-jackson]Hibernate ORM with Panache [
quarkus-hibernate-orm-panache]JDBC Driver - PostgreSQL [
quarkus-jdbc-postgresql]
Puedes ver la lista de extensiones que has agregado dando Click sobre el icono del cohete que se encuentra en la parte superior derecha, como se indica en la siguiente captura de pantalla.
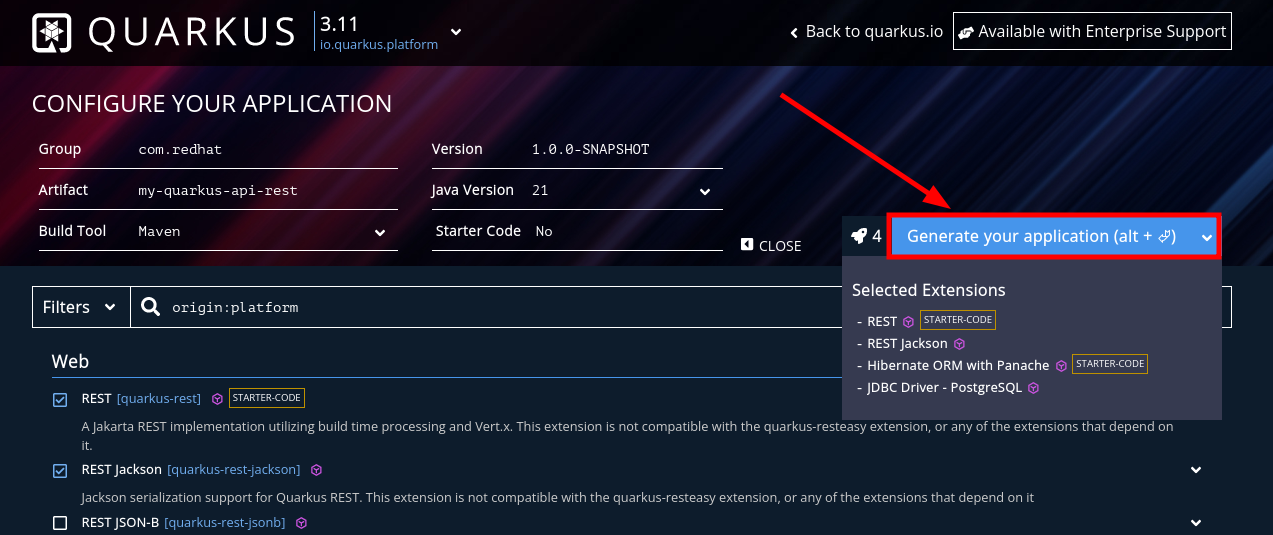
Descarga el proyecto dando Click en el botón azul que dice Generate your application.
Da Click en el botón azul que dice DOWNLOAD THE ZIP que se mostrará en el modal que se acaba de abrir.
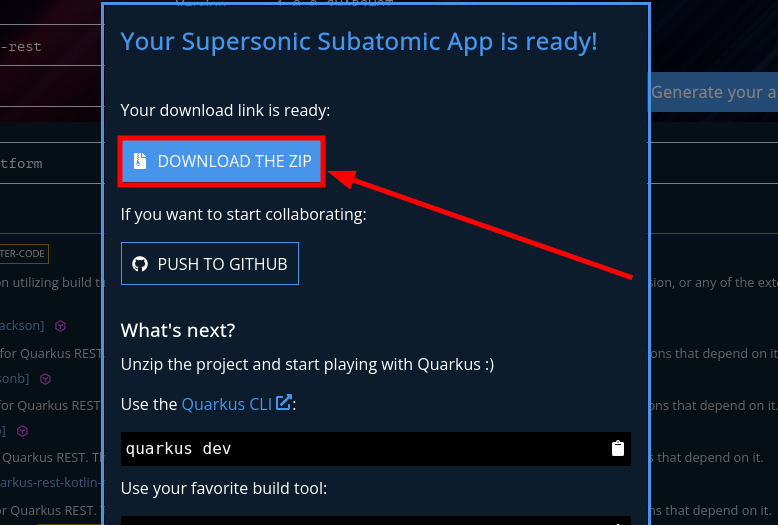
Esto te descargará un comprimido zip.
Descomprime este archivo zip y abre el proyecto con el IDE de tu preferencia. En mi caso particular, voy a seguir desarrollando el manual utilizando la versión comunitaria del IDE IntelliJ. Pero siéntete libre de utilizar cualquier otro editor.
Crea un nuevo paquete con el nombre del grupo que definiste en el generador de proyectos. En este caso sería com.redhat.
Presiona Click derecho, en el caso del editor IntelliJ, sobre el directorio java. Selecciona New y crea un nuevo paquete.
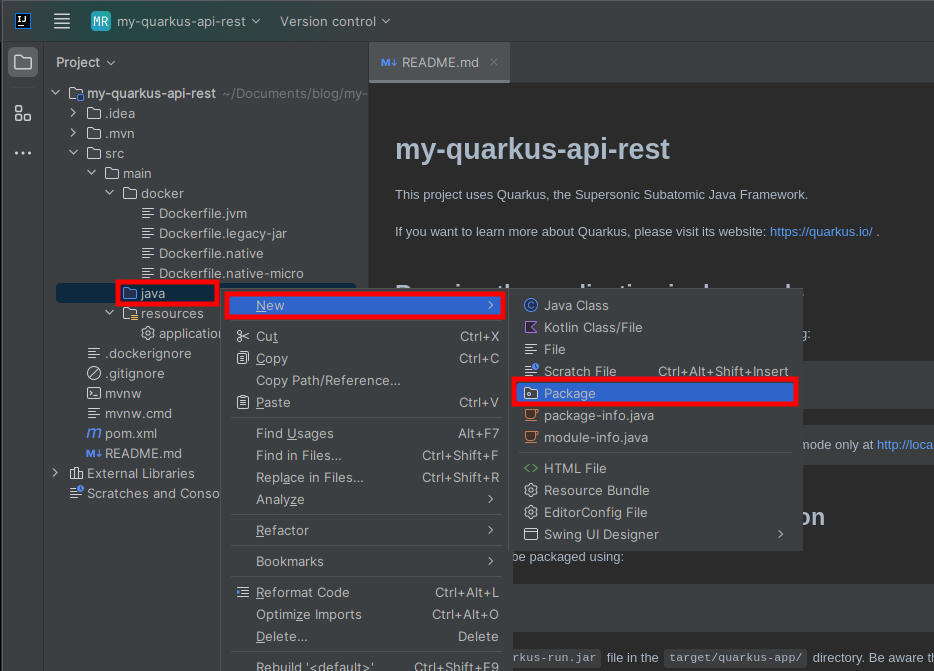
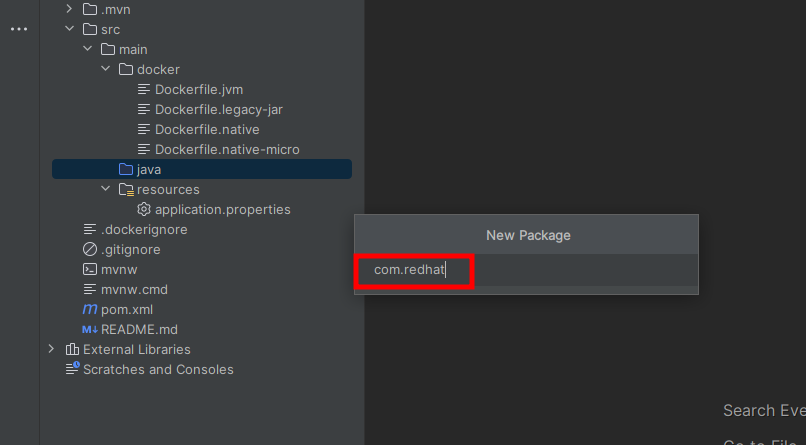
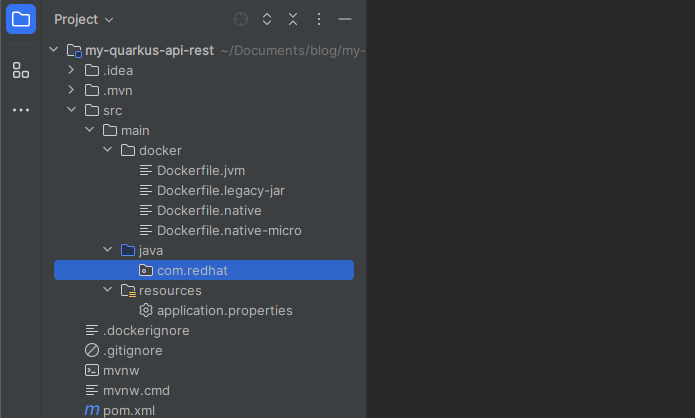
Deberá verse como se muestra en la siguiente captura de pantalla.
Paso 2: Crea la clase de entidad
Jakarta Persistence es una especificación de Java. Se utiliza para persistir datos entre objetos Java y bases de datos relacionales. Jakarta Persistence actúa como puente entre los modelos de dominio orientados a objetos y los sistemas de bases de datos relacionales.
Hibernate ORM es la implementación de facto de Jakarta Persistence (antes conocida como JPA) y le ofrece toda la amplitud de un Object Relational Mapper. Hace posibles mapeos complejos, pero no hace triviales los mapeos simples y comunes. Hibernate ORM con Panache se centra en hacer que sus entidades sean triviales y divertidas de escribir en Quarkus.
Primero crea un clase en la que vas a definir la entidad User de la aplicación.
Presiona Click derecho sobre el nombre del paquete que acabas de crear en el paso anterior. Selecciona New y crea una nueva Java Class.
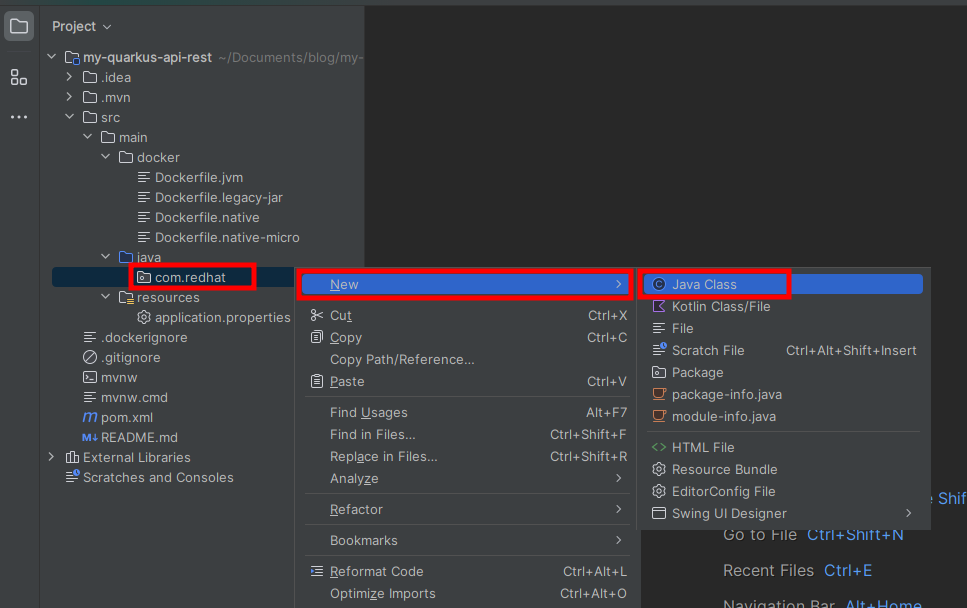
Ponle el nombre de User.
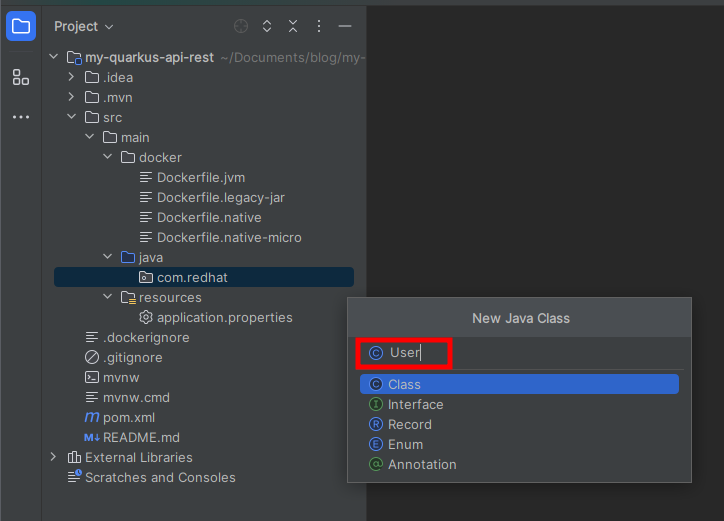
Para definir una entidad Panache, simplemente extienda PanacheEntity, anótala con @Entity y añada sus columnas como campos públicos. Y con la anotación @Table puedes indicar el nombre de la tabla y el esquema de tu base de datos.
Copia y pega el siguiente snippet de código en el que estas definiendo la entidad que representará un modelo de tu tabla de la base de datos.
package com.redhat;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
import jakarta.persistence.Table;
@Entity
@Table(name = "user", schema = "public")
public class User extends PanacheEntity {
@Column(name="name")
public String name;
@Column(name="email")
public String email;
}
Al extender esta clase de PanacheEntity nos permite aprovechas las ventajas de que nos ofrece Panache, que en conjunto con Hibernate ORM va a abstraer mucho código repetitivo y trivial, permitiéndote enfocarte en la lógica de negocio.
En este caso, Panache se encargará de la generación automática de los id's de lo elementos que insertemos en la base de datos, creará los getters y setters de la entidad; entre otras cosas más. Es por esto que en la entidad solo definimos dos atributos, name e email, ya que Panache administrará la columna id.
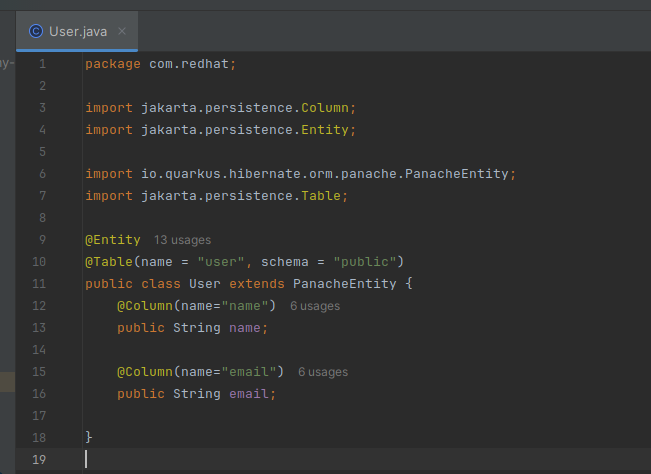
Paso 3: Define los servicios de la aplicación
Crea una clase llamada UserResource, al mismo nivel de la clase User, dentro del paquete com.redhat, repitiendo el mismo procedimiento que acabas de hacer.
Copia y pega el siguiente snippet de código dentro de la clase UserResource que acabas de crear.
package com.redhat;
import java.util.List;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.PUT;
import jakarta.ws.rs.DELETE;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import jakarta.transaction.Transactional;
import jakarta.ws.rs.core.Response;
import jakarta.ws.rs.PathParam;
import jakarta.enterprise.context.ApplicationScoped;
import com.redhat.User;
@Path("/user")
@ApplicationScoped
public class UserResource {
@GET
@Consumes(MediaType.APPLICATION_JSON)
@Produces(MediaType.APPLICATION_JSON)
public List<User> getAll() throws Exception {
return User.findAll().list();
}
@POST
@Transactional
public Response create(User u) {
if (u.name == null || u.email == null) return Response.ok().status(400).build();
User user = new User();
user.name = u.name;
user.email = u.email;
User.persist(user);
return Response.ok(u).status(200).build();
}
@PUT
@Transactional
@Path("/{id}")
public User update(@PathParam(value = "id") Long id, User u) {
User entity = User.findById(id);
if (entity == null) Response.ok().status(400).build();
if(u.name != null ) entity.name = u.name;
if(u.email != null) entity.email = u.email;
return entity;
}
@DELETE
@Path("/{id}")
@Transactional
public Response delete(@PathParam(value = "id") Long id) {
User entity = User.findById(id);
if (entity == null) Response.ok().status(400).build();
entity.delete();
return Response.status(204).build();
}
}
Con la anotación @Path estas definiendo la dirección del endpoint que estas creando, y al que se van a dirigir la peticiones. Con @ApplicationScoped estas indicando a la aplicación la visibilidad que va a tener este java bean, en este caso al anotarlo con @ApplicationScoped este puede ser utilizado desde cualquier lugar de la aplicación. Otros scopes que también puedes utilizar, por ejemplo, son @RequestScoped o @SessionScoped .
Con @GET , @POST ,@PUT ,@DELETE indicas el verbo HTTP que utilizará este servicio.
Con respecto a las anotaciones @Consumes y @Produces indicas el tipo de dato que el servicio va a recibir y a producir, respectivamente.
Otra anotación también importante es la @Transactional, que hay que agregarla a los servicio que hacen alguna modificación en la base de datos, en este caso vemos que el método getAll() no tiene esta anotación ya que este servicio solo consulta, no modifica ningún registro.
Algo también importante a resalta es que hay algunos métodos que no se definieron en la clase anterior, la de la entidad, como por ejemplo persist(), findById() o delete(). Esto es porque los estos métodos nos los proporciona Panache y es este el que se encarga de realizar las operaciones directamente en la base de datos.
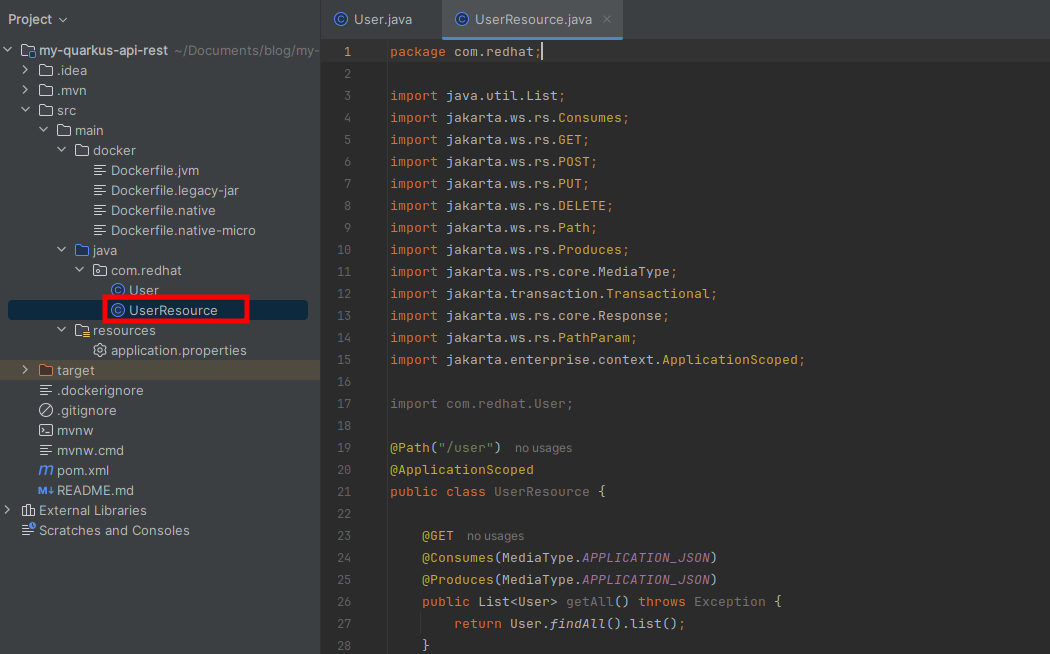
Observa que estas creando 4 métodos, uno por cada tipo de operación que se quiere realizar sobre la base de datos; GET, POST, PUT y DELETE.
Paso 4: Agrega las propiedades para configurar la base de datos
Por último, al mismo nivel del directorio java hay otro directorio llamado resources que contiene un archivo llamado application.properties.
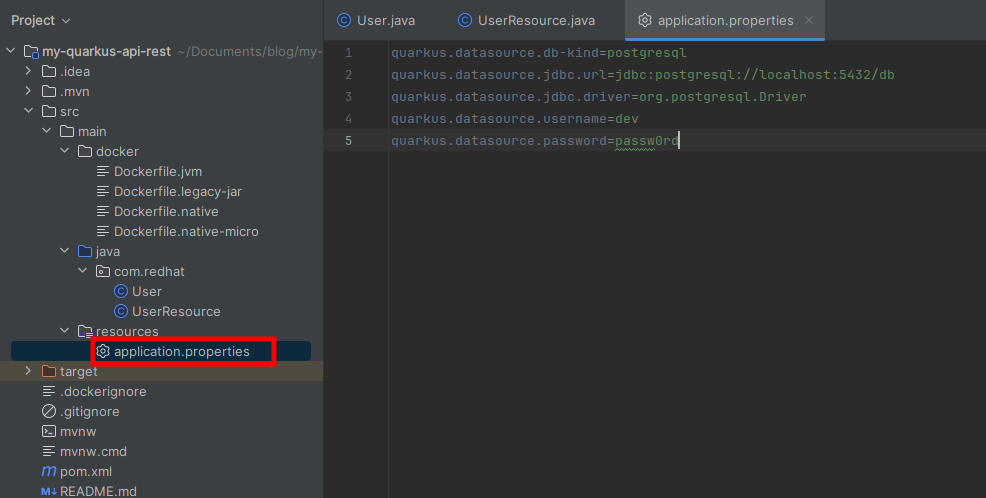
Copia y pega las siguientes propiedades dentro de este archivo de propiedades, que van a ser la propiedades de configuración para realizar la conexión a la base de datos.
quarkus.datasource.db-kind=postgresql
quarkus.datasource.jdbc.url=jdbc:postgresql://localhost:5432/db
quarkus.datasource.jdbc.driver=org.postgresql.Driver
quarkus.datasource.username=dev
quarkus.datasource.password=passw0rd
quarkus.datasource.db-kind: El tipo de base de datos a la que nos conectaremos.
quarkus.datasource.jdbc.url: URL de conexión a la base de datos.
quarkus.datasource.jdbc.driver: El nombre de la clase del driver de la base de datos.
quarkus.datasource.username: El nombre de usuario de la base de datos con el que se quiere entablar la conexión.
quarkus.datasource.password: La contraseña del usuario con el que se quiere entablar la conexión.
Prueba la aplicación
Ahora vamos a probar la aplicación que acabas de crear utilizando una capacidad de Quarkus que se llama Live Coding, que lo que permite realizar modificaciones sobre el código y ver este cambio reflejado de forma automática e inmediata en la instancia que estas corriendo.
Hay varias maneras en las que puedes iniciar el modo de desarrollo, pero en mi caso en particular emplearé el comando de Maven directamente desde la terminal, el comando mvn.
Aunque también puedes utilizar la herramienta de linea de comandos de Quarkus, quarkus, que te permite crear proyectos, gestionar extensiones y realizar tareas esenciales de compilación y desarrollo utilizando la herramienta de compilación de proyectos subyacente.
También podrías utilizar el Maven Wrapper que viene incluido en el proyecto de Quarkus, que te permite ejecutar el proyecto Maven sin tener Maven instalado y presente en la ruta. Puedes encontrarlo como mvnw.
Paso 1: Inicia el modo de Live Coding
Ejecuta el siguiente comando de Maven para iniciar el modo de desarrollo utilizando el perfil quarkus.
mvn quarkus:dev
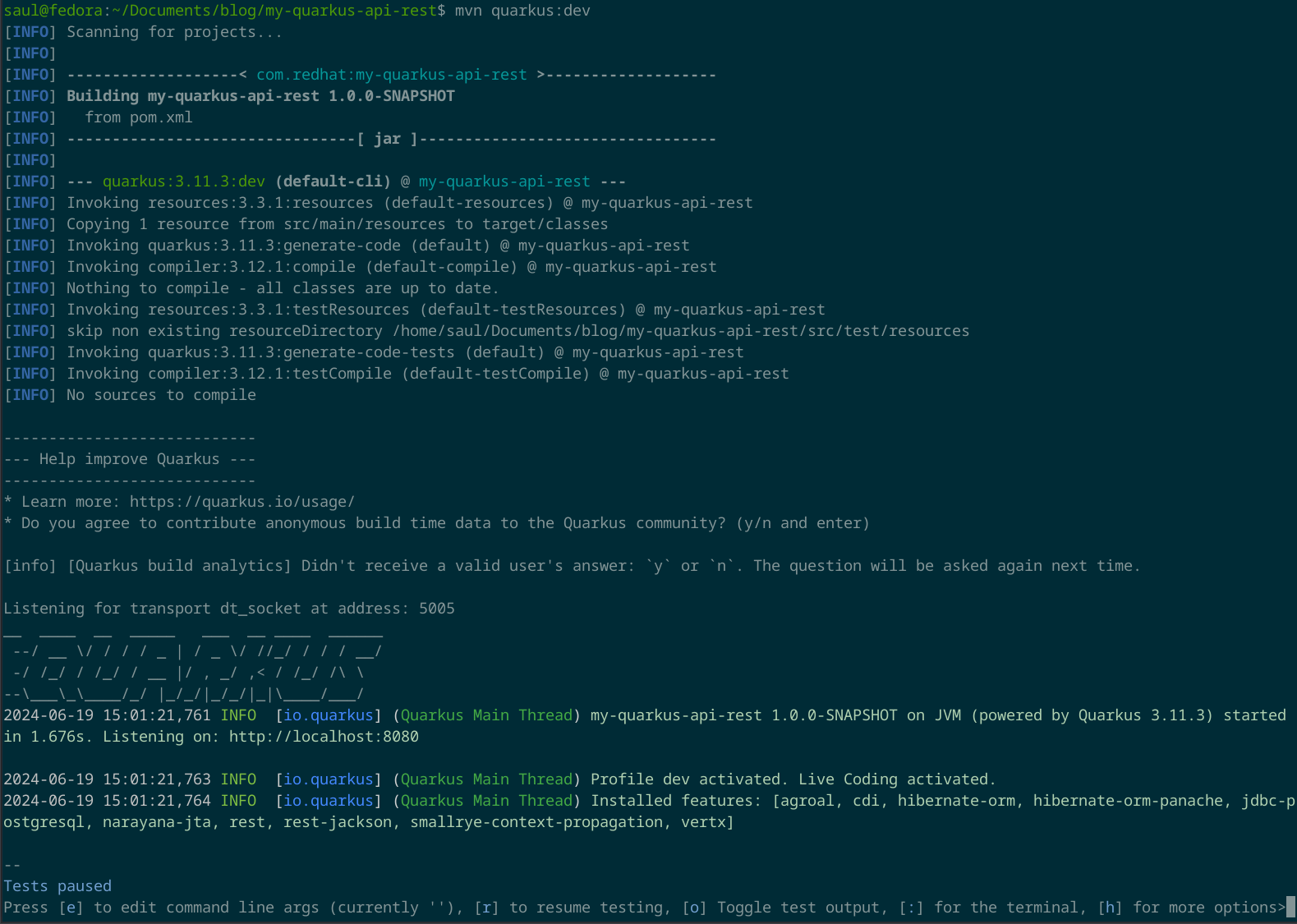
Alternativamente, también puedes utilizar la CLI de quarkus que puedes instalar en tu computadora o el Maven Wrapper que viene incluido en el proyecto de Quarkus.
quarkus dev
./mvnw compile quarkus:dev
Paso 2: Obtén datos de la base de datos - Operación GET
Personalmente me resulta más sencillo consumir la aplicación desde la terminal utilizando el comando cURL, curl.
Pero podrías utilizar cualquier otro cliente que pueda realizar peticiones HTTP, como Postman, que también es muy popular en el mundo del desarrollo.
Si vas a utilizar curl ten en cuenta que a pesar de que este comando esta presente en la PowerShell de Windows podrían variar los comandos en PowerShell. Por lo tanto asegurate de que este comando este correctamente escrito o utiliza Postman.
Ejecuta el siguiente comando para consumir la petición GET y recuperar todos los elementos de la tabla user de la base de datos.
curl -w '\n' http://localhost:8080/user

En este caso, esta operación te deberá devolver un arreglo vació, ya que esta tabla la acabas de crear y todavía no se le han hecho inserciones.
Paso 3: Inserta un nuevo registro en la base de datos - Operación POST
Ejecuta el siguiente comando para consumir la petición POST para insertar un nuevo renglón en la tabla user.
curl -w '\n' -X POST -H "Content-Type: application/json" -d '{"name": "Peter Parker", "email": "spiderman@email.com"}' http://localhost:8080/user

Si ahora consultar todos los elementos deberías ver este elemento listado.
curl -w '\n' http://localhost:8080/user
Paso 4: Actualiza datos de las base de datos - Operación PUT
Ejecuta el siguiente comando para consumir la petición PUT para actualizar un elemento de la base de datos. Pasa el JSON con los elementos actualizados y pasa el ID del elemento en el path de la petición.
curl -w '\n' -X PUT -H "Content-Type: application/json" -d '{"name": "Peter Parker", "email": "parker@email.com"}' http://localhost:8080/user/1

Si consultar este elementos verás los valores de sus campos actualizados.
curl -w '\n' http://localhost:8080/user
Paso 5: Elimina registros de la base de datos - operación DELETE
Ejecuta el siguiente comando para consumir la petición DELETE y eliminar el elemento de la tablar con el ID que pases en el path de la consulta.
curl -w '\n' -X DELETE http://localhost:8080/user/1

Si consultas los elementos de la tabla, este elemento ya no estará listado.
curl -w '\n' http://localhost:8080/user
Bonus: Construcción de la Container Image de la aplicación (Opcional)
En un esquema de despliegue tradicional, compilarías tu aplicación Java a bytecode y la desplegarías sobre un servidor de aplicaciones. Sin embardo, hoy día lo frameworks de desarrollo modernos nos ofrecen alternativas de construcción y ponen sobre la mesa estrategias de despliegue modernas.
En el caso de Quarkus al ser un frame cloud-native desarrollado bajo el concepto de Container-First, esta capacitado para correr en contenedores, y por extensión, de ser desplegada con un orquestador de contenedores, como Kubernetes.
Vale la pena formalizar el algunos conceptos para poder tener una perspectiva más integral.
Contenedor:
Los contenedores son unidades ejecutables de software que empaquetan código de aplicación junto con sus bibliotecas y dependencias. Los contenedores son una tecnología que permite empaquetar y aislar aplicaciones con todo su entorno de ejecución, es decir, todos los archivos necesarios para ejecutarse.
Pod:
Un Pod (como en una manada de ballenas) es un grupo de uno o más contenedores, con almacenamiento compartido y recursos de red, y una especificación sobre cómo ejecutar los contenedores.
Imagen:
Una imagen de contenedor es un archivo estático e inalterable que incluye código ejecutable para poder ejecutar un proceso aislado en la infraestructura de TI. La imagen se compone de bibliotecas de sistema, herramientas de sistema y otros ajustes de plataforma que un programa de software necesita para ejecutarse en una plataforma de contenerización, como Docker, Podman o Kubernetes.
Dentro del directorio main del proyecto vas a encontrar varios Dockerfile que te permitirán contenerizar tus aplicaciones de Quarkus. Dentro de estos Dockerfile vienen instrucciones para construir y utilizar tu aplicación Quarkus contenerizada.
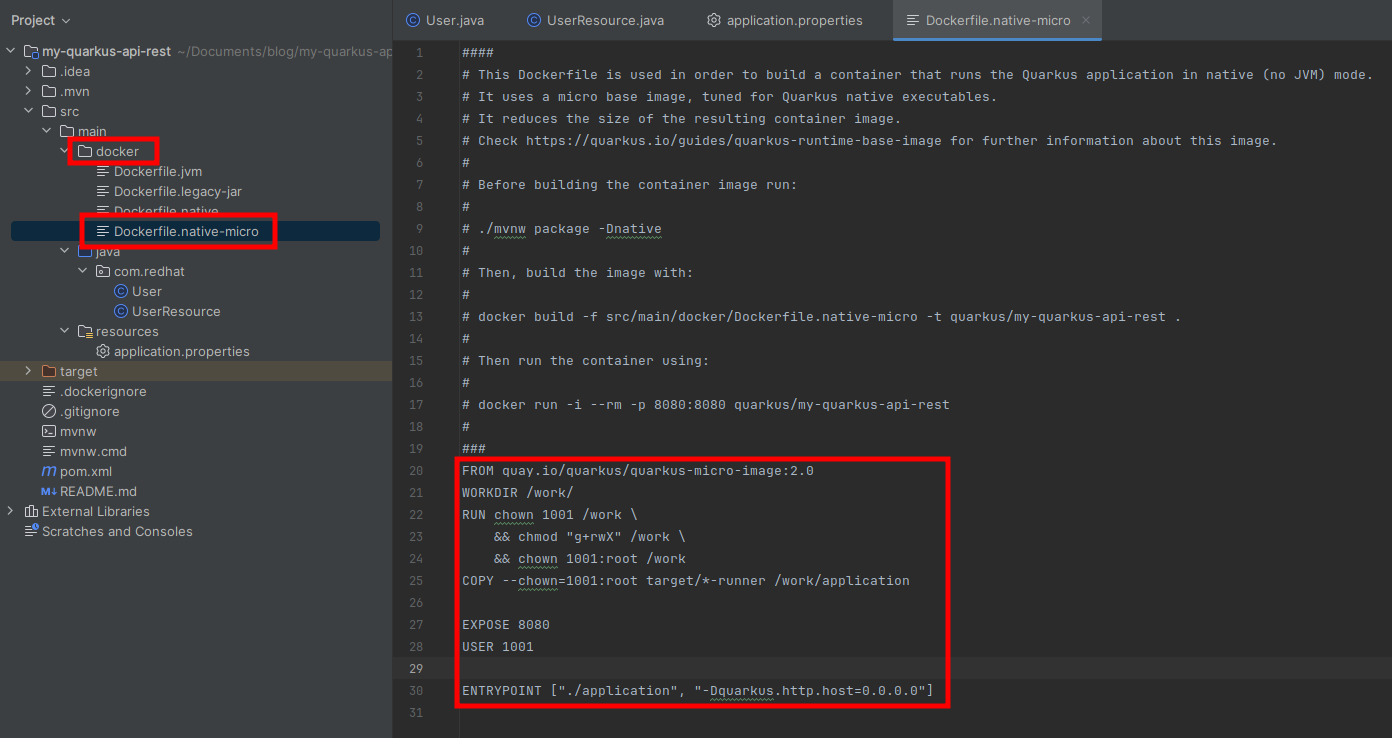
A continuación vas a construir una imagen de contenedor con tu aplicación y vamos a probarla desplegando el contenedor dentro de un pod, gracias que Podman nos permite trabajar con pods directamente, que si bien es un concepto de los orquestadores de contenedores es muy útil tener esta capacidad durante la etapa de desarrollo de aplicaciones cloud native.
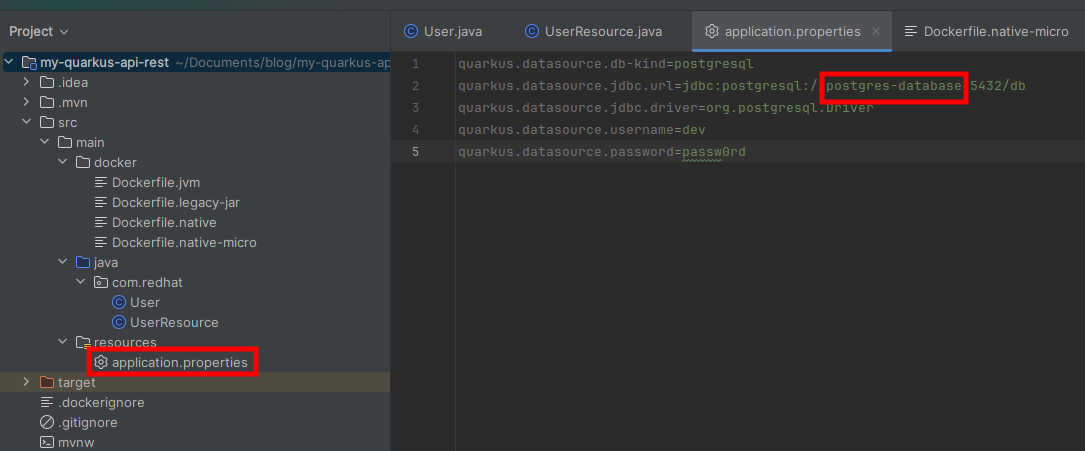
Paso 1: Modifica la referencia a la base de datos en el archivo application.properties
Como vamos a desplegar la aplicación dentro del mismo pod podemos utilizar el nombre del contenedor como referencia a la base de datos, en lugar del localhost que has estado utilizando en las pruebas hasta ahora.
Modifica el application.properties para que quede de la siguiente forma.
quarkus.datasource.db-kind=postgresql
quarkus.datasource.jdbc.url=jdbc:postgresql://postgres-database:5432/db
quarkus.datasource.jdbc.driver=org.postgresql.Driver
quarkus.datasource.username=dev
quarkus.datasource.password=passw0rd
Paso 2: Compila la aplicación a binario nativo
Compila a binario nativo para generar una imagen minima, utilizando la opción -Dnative en el comando de Maven.
mvn package -Dnative
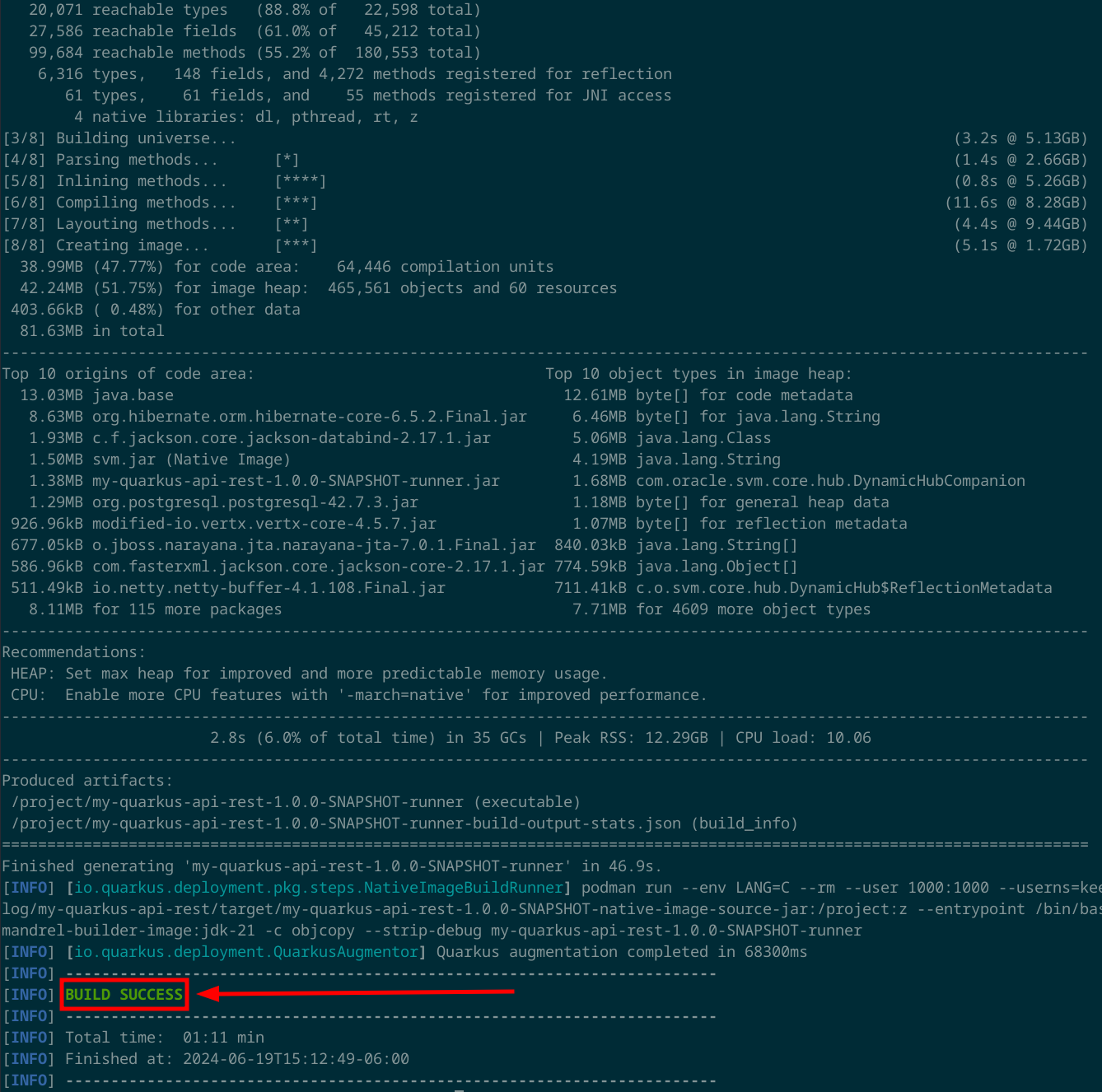
El proceso de construcción podría tardar algunos minutos, pero al final encontrarás el archivo ejecutable dentro del directorio target. Dentro target encontrarás un archivo cuyo nombre termina con ...-runner, este es tu binario nativo.
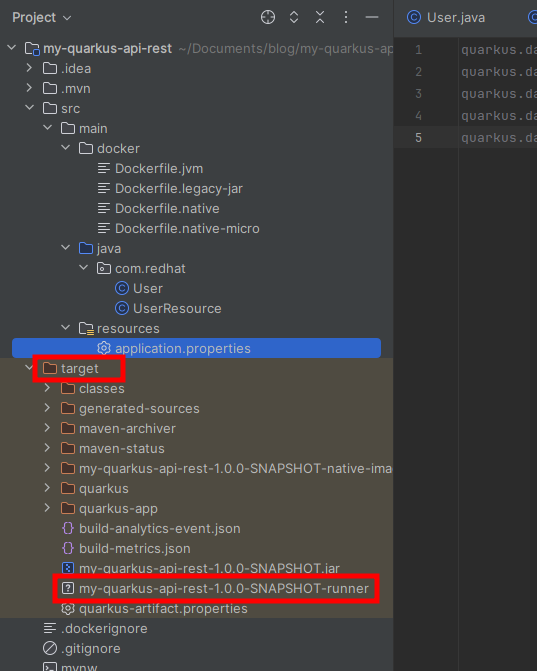
NOTA
Alternativamente, si quisieras hacer al construcción de un compilado tradicional de Java y generar un archivo jar, utilizarías el siguiente comando de Maven.
mvn packageY usarías el archvio Dockerfile.jvm en los pasos posteriores.
Adicionalmente, Quarkus también nos da la opción de generar un Uber-Jar agregando la propiedad
quarkus.package.jar.type=uber-jaren el archivo de propiedades,application.properties.
Paso 3: Crea la imagen de contenedor
Construye la imagen de contenedor utilizando el Dockerfile Dockerfile.native-micro, que va a crear una imagen de tamaño mínimo.
Ejecuta el siguiente comando para crear una imagen que se llame api-rest-crud-service . No omitas el punto, ., al final del comando, ya que esta es la referencia al directorio en el que te encuentras y de donde se va a tomar el binario ejecutable que va a ser copiado en la imagen.
podman build -f src/main/docker/Dockerfile.native-micro -t quarkus/api-rest-crud-service .
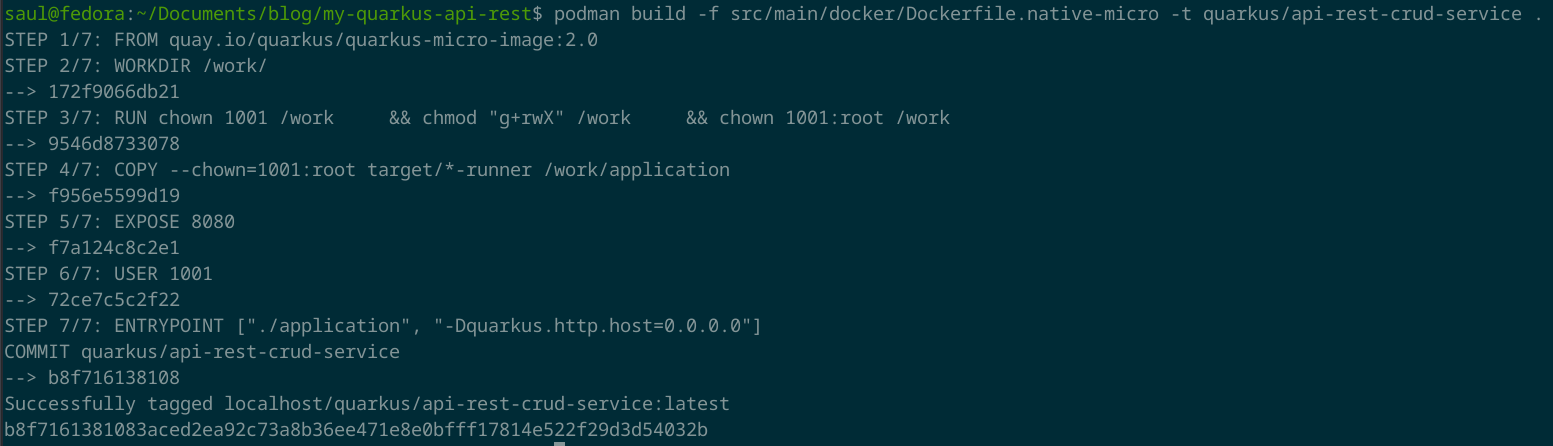
Una vez terminado de correr la construcción de la imagen, puede consultar esta imagen con el siguiente comando.
podman images
Pon atención a la última columna, SIZE, ya que en esta podrás ver que la imagen resultante tiene un tamaño de 116 MB, que es bastante pequeña.

Paso 4: Crea un pod para desplegar los contenedores
Corre el siguiente comando para crear un pod, indicando con la bandera -p que quieres mapear el puerto 8080 del pod al exterior, ya que es en este puerto en el que va a estar corriendo la aplicación.
Y con el comando podman pod list puede consultar los pods que tienes.
podman pod create --name my-api-rest-pod -p 8080:8080
podman pod list

Paso 5: Crea y configura la base de datos en el pod
Para y elimina el contenedor de la base de datos que ya tienes corriendo.
podman stop postgres-database
podman rm postgres-database
Y corre los siguientes dos comandos para para crear una base de datos dentro del contenedor e iniciar un terminal de este contenedor.
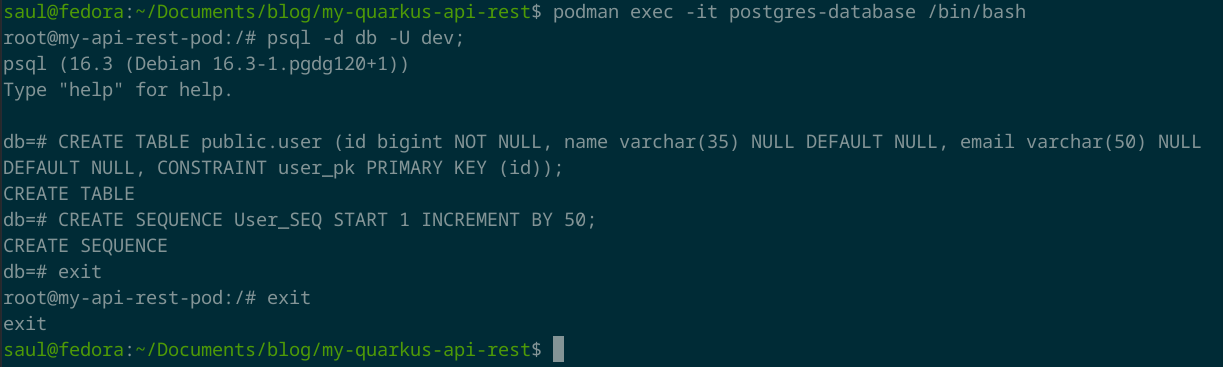
podman run -d --name postgres-database --pod my-api-rest-pod -e POSTGRES_PASSWORD=passw0rd -e POSTGRES_USER=dev -e POSTGRES_DB=db postgres:latest
podman exec -it postgres-database /bin/bash
Nota que con la opción --pod my-api-rest-pod le estas indicando el pod en el que quieres que se cree el contenedor.

Copia y pega los siguientes comandos en la terminal que acabas de crear para crear la tabla y la secuencia en la base de datos.
psql -d db -U dev;
CREATE TABLE public.user (id bigint NOT NULL, name varchar(35) NULL DEFAULT NULL, email varchar(50) NULL DEFAULT NULL, CONSTRAINT user_pk PRIMARY KEY (id));
CREATE SEQUENCE User_SEQ START 1 INCREMENT BY 50;
exit
exit
Paso 6: Despliega la aplicación contenerizada en el pod
Despliega un contenedor de tu aplicación en el pod, junto con la base de datos.
Ejecuta el siguiente comando.
podman run -i --name quarkus-rest-backend --pod my-api-rest-pod quarkus/api-rest-crud-service:latest
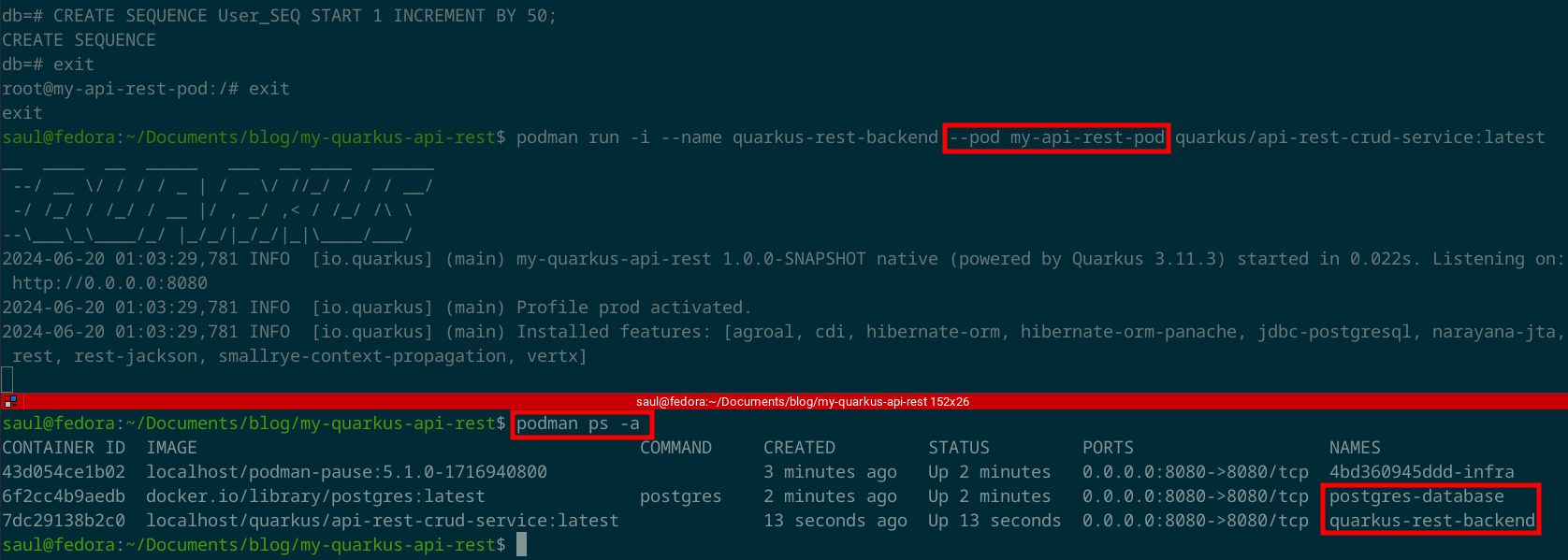
Ahora, puedes volver a hacer las pruebas que hicimos anteriormente con los comando de cURL, o con Postman.
curl -w '\n' http://localhost:8080/user
curl -w '\n' -X POST -H "Content-Type: application/json" -d '{"name": "Peter Parker", "email": "spiderman@email.com"}' http://localhost:8080/user
curl -w '\n' -X PUT -H "Content-Type: application/json" -d '{"name": "Peter Parker", "email": "parker@email.com"}' http://localhost:8080/user/1
curl -w '\n' -X DELETE http://localhost:8080/user/1
Paso 7: Elimina los contenedores desplegados
Para limpiar tus espacio de trabajo y eliminar los contenedores y el pod que has creado, ejecuta los siguientes comandos.
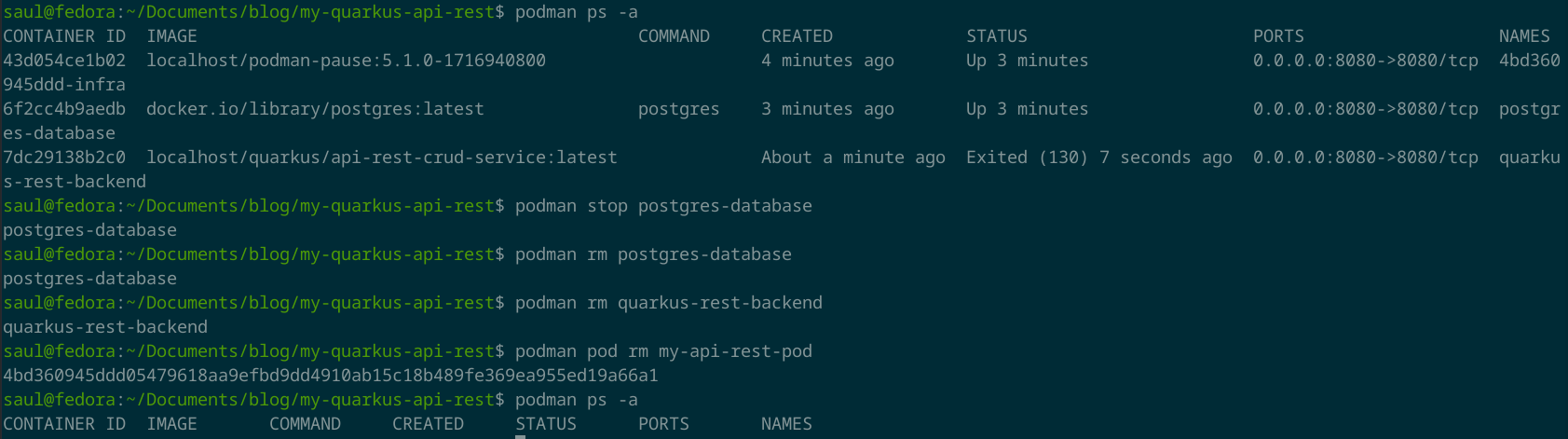
podman ps -a
podman stop postgres-database
podman rm postgres-database
podman rm quarkus-rest-backend
podman pod rm my-api-rest-pod
podman ps
Con podman ps puedes ver los contenedores que tienes.
Paso 8: Almacena la imagen en un registro de imágenes (opcional)
Si quieres distribuir y alamcenar tus imágenes, la manera más sencilla de hacerlo es utilizando un registro (container registry), que es un servidor dedicado que se utiliza para almacenar imágenes de contenedores y accederlas. El registro más popular es Docker Hub, pero hay muchos otros registros públicos, como Quay.io. Y es este último que voy a utilizar para mostrar como podrías hacerlo.
Si quisieras utilizar este registro primero deberás crear una cuenta en la pagina web.
Inicia sesión, indicando el nombre de dominio del registro al que te quieres conectar al comando podman login. Y pon las credenciales de tu cuenta de Quay.io.
podman login quay.io
Y con podman tag renombra tu imagen para asignarle un nombre compatible con el del registro.
El siguiente es el ejemplo que utilice indicando el dominio del registro en el que quiero almacenar la imagen seguido de mi nombre de usuario, separado por una diagonal, /. Y al final el nombre de la imagen, deparado por dos puntos, :, del nombre del tag.
En este caso, asegurate de colocar bien tu datos correspondientes.
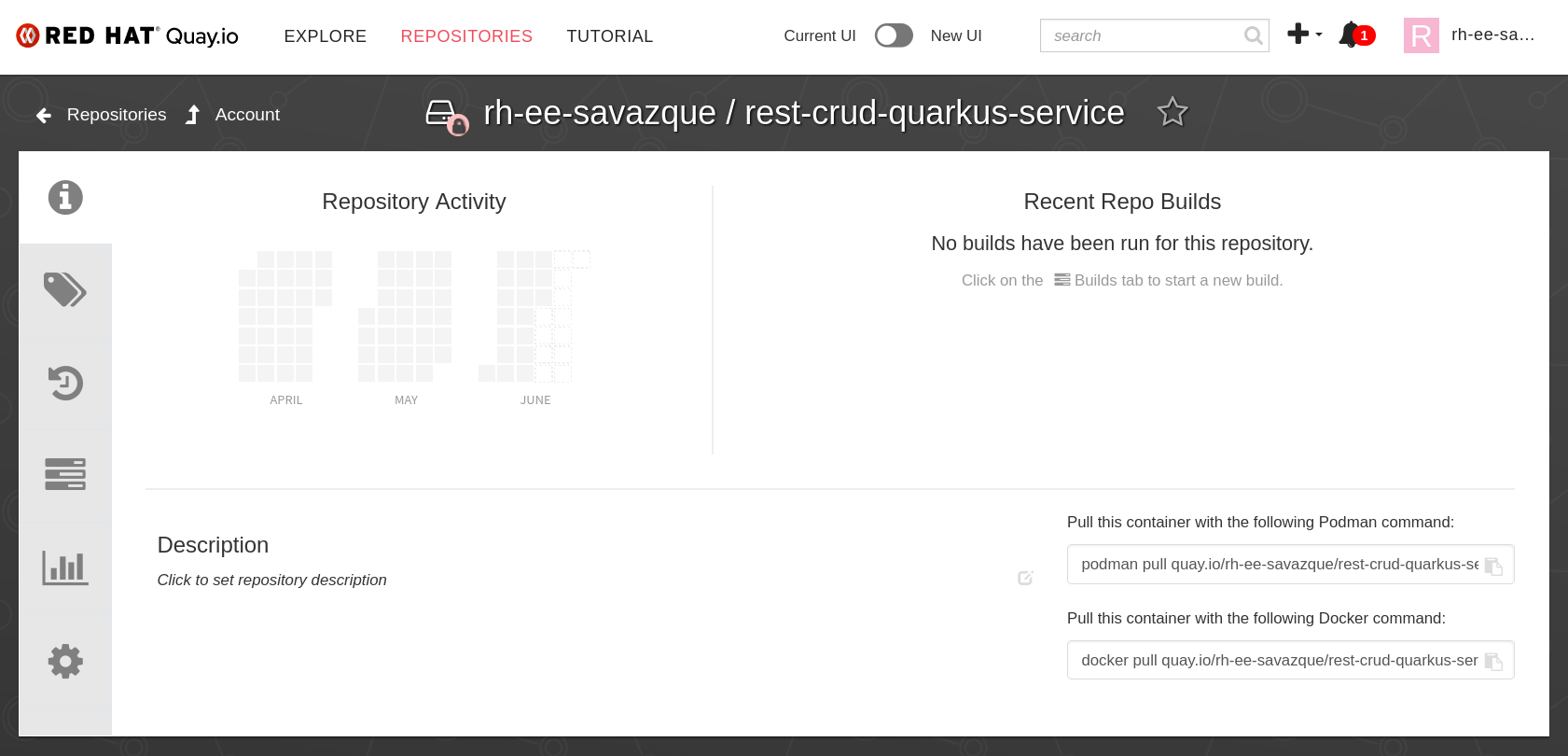
podman tag quarkus/api-rest-crud-service quay.io/rh-ee-savazque/rest-crud-quarkus-service:latest

Con un podman push subes la imagen al registro.
podman push quay.io/rh-ee-savazque/rest-crud-quarkus-service:latest

Y si visitar Quay.io, verás tu imagen.
Conclusiones
El desarrollo de aplicaciones cloud-native con Quarkus es muy sencillo. En este relativamente corto tutorial pasamos de cero a tener una API REST con CRUD contenerizada, ligera, veloz y altamente optimizada; en un registro de imágenes para su distribución.
Podman es una herramienta que nos permite administrar el ciclo de vida contenedores y, a diferencia de Docker, nos permite también trabajar con pods.
Referencias
The Kubernetes Book: 2024 Edition - By Nigel Poulton
Docker Hub - Postegres Docker Official Image
Quarkus - Getting Started with Reactive
Quarkus - Writing REST Services with Quarkus REST
Podman: Managing pods and containers in a local container runtime
Subscribe to my newsletter
Read articles from Saul Vazquez directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by