Practical ML: How to Find the Right Spot to Stop your Training Process to Save Money and Time
 Juan Carlos Olamendy
Juan Carlos Olamendy
Have you ever wondered what's the right moment to stop your training process?
How to ensure the models generalize well and save time and computational power at the same time?
Hard questions, right? I got you!
I want to help you find the answers because I faced recently this common frustration.
Let's dive into the intricacies of the training process to find the cheapeast way to figure out a sweet spot on your model performance and computing resources.
👇
The Balance: Underfitting vs. Overfitting
Before we delve into early stopping, let's set the stage by understanding the two extremes of model training: underfitting and overfitting.
Underfitting occurs when a model is too simple to capture the underlying patterns in the data.
Training a model for too few epochs results in underfitting.
It performs poorly on both training and unseen data because it hasn't captured the underlying patterns.
On the other hand, overfitting happens when a model learns the training data too well.
When you train a model for too many epochs, it starts to overfit.
This means the model becomes too tailored to the training data, capturing noise and fluctuations.
An overfitted model performs exceptionally well on training data but poorly on unseen data.
The challenge lies in finding the "just right" amount of training – not too little, not too much.
This optimal point is where the model has learned enough to make accurate predictions without memorizing the noise in the training data.
But how do we find this sweet spot?
Enter early stopping.
Early Stopping
Early stopping is a regularization technique that helps prevent overfitting by monitoring the model's performance on a validation set during training.
The core idea behind early stopping is simple yet powerful:
Train the model on the training data
Regularly evaluate its performance on a separate validation set
Stop training when the performance on the validation set starts to degrade
By implementing early stopping, we can catch the moment when our model starts to overfit and preserve its ability to generalize well to new data.
To implement early stopping, you need a performance metric to monitor.
Commonly, this is the loss function, but it can also be metrics like accuracy, precision, or recall.
The key is to track how this metric evolves on the validation set during training.
It's crucial to save the model's state at regular intervals during training.
This allows us to revert to the best-performing version of the model once training is complete.
Early Stopping in Action
Let's look at a simple implementation of early stopping using TensorFlow and Keras:
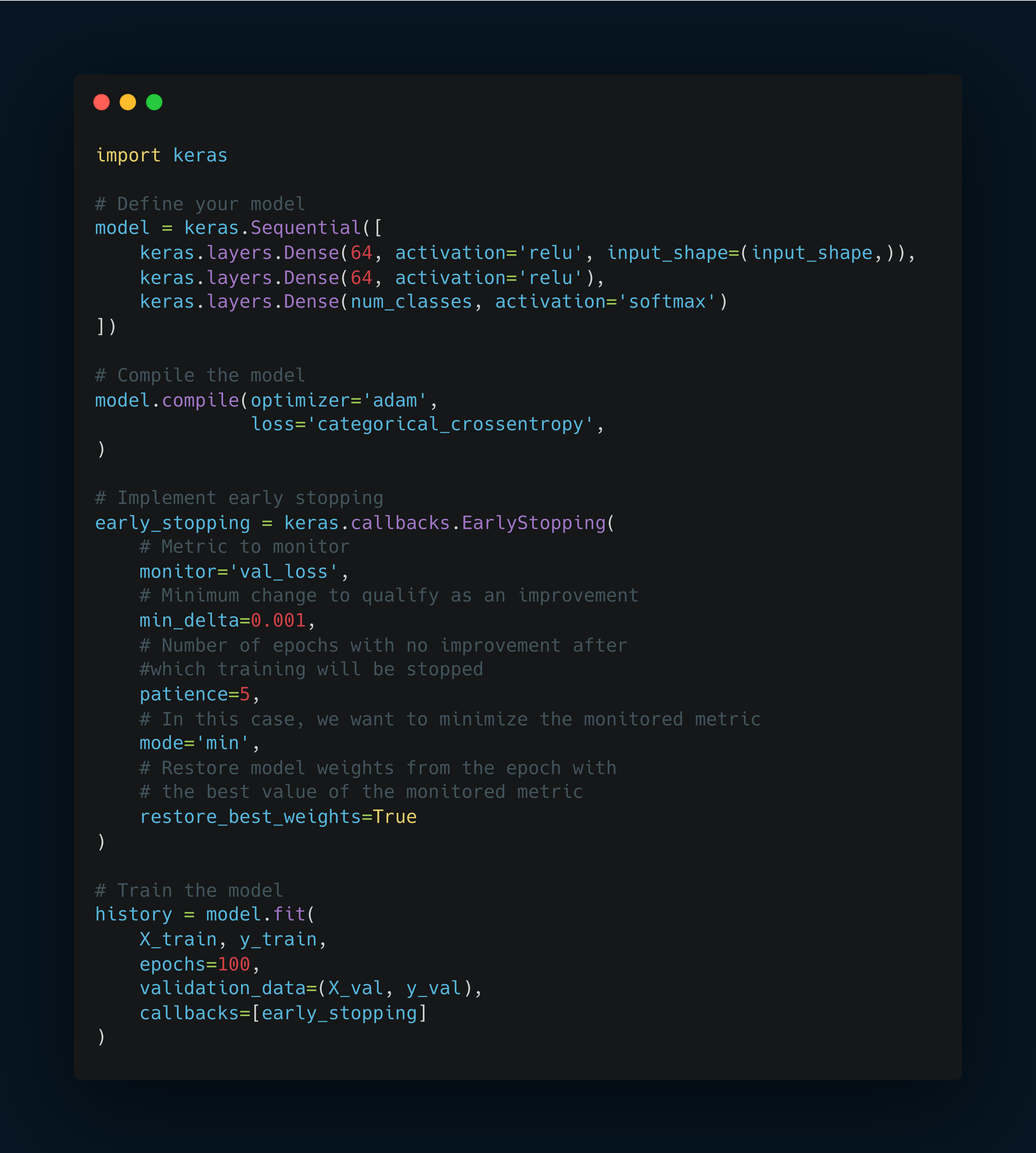
In this example, we create an EarlyStopping callback that monitors the validation loss.
If the loss doesn't improve by at least 0.001 for 5 consecutive epochs, training will stop.
The restore_best_weights=True argument ensures that we keep the model's state from its best-performing epoch.
The Benefits of Early Stopping
Early stopping acts as a regularization mechanism.
By preventing the model from overfitting to the training data, it helps in achieving better generalization.
It works alongside other regularization techniques like dropout and L2 regularization.
Advantages of Early Stopping
Prevents Overfitting: Stops training before the model starts overfitting the training data.
Saves Resources: Reduces unnecessary computation by halting training early.
Improves Generalization: Enhances the model's performance on unseen data.
Challenges and Considerations
While early stopping is powerful, it requires careful consideration of the following:
Patience Parameter: Setting the right patience parameter is crucial. Too high, and you risk overfitting; too low, and you might stop too early.
Validation Set Size: Ensure your validation set is representative of the unseen data. A small or biased validation set can lead to misleading results.
Conclusion
Early stopping is a simple yet effective technique to enhance your model's performance and prevent overfitting.
By leveraging a validation set and monitoring performance metrics, you can automatically halt training at the optimal point.
This not only saves computational resources but also ensures your model generalizes well to unseen data.
As you continue to build and refine machine learning models, incorporating early stopping into your workflow will undoubtedly contribute to more robust and reliable outcomes.
So, the next time you train a model, consider early stopping as a vital tool in your arsenal.
Keep experimenting, stay curious, and may your models always find the perfect balance!
And remember.
If you like this article, share it with others ♻️
Would help a lot ❤️
And feel free to follow me for articles more like this.
Subscribe to my newsletter
Read articles from Juan Carlos Olamendy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Juan Carlos Olamendy
Juan Carlos Olamendy
🤖 Talk about AI/ML · AI-preneur 🛠️ Build AI tools 🚀 Share my journey 𓀙 🔗 http://pixela.io