Elastic Search [Chapter 2]
 Khaled Hesham
Khaled HeshamTable of contents

Life Inside an Elasticsearch Cluster: Insights from Chapter 2
Hey everyone! 😀
Welcome back to our deep dive into "Elasticsearch: The Definitive Guide." Elasticsearch is built to be always available and to scale with your needs. Scale can come from buying bigger servers (vertical scale, or scaling up) or from buying more servers (horizontal scale, or scaling out). While Elasticsearch can benefit from more powerful hardware, vertical scale has its limits. Real scalability comes from horizontal scale—the ability to add more nodes to the cluster and to spread load and reliability between them.
With most databases, scaling horizontally usually requires a major overhaul of your application to take advantage of these extra boxes. In contrast, Elasticsearch is distributed by nature: it knows how to manage multiple nodes to provide scale and high availability. This also means that your application doesn’t need to care about it.
In this post, we’ll explore the fascinating inner workings of an Elasticsearch cluster as detailed in Chapter 2. Whether you're a seasoned Elasticsearch user or a newcomer, understanding how clusters operate is key to accessing Elasticsearch’s full potential. So, let’s get started!
An Empty Cluster: The Beginning
When you first set up Elasticsearch, you start with an empty cluster. Think of it as a blank canvas, ready to store and search through data. Your cluster will consist of one or more nodes (servers), which work together to handle your data.

One node in the cluster is elected to be the master node, which is in charge of managing cluster-wide changes like creating or deleting an index or adding or removing a node from the cluster. The master node does not need to be involved in document-level changes or searches, which means that having just one master node will not become a bottleneck as traffic grows. Any node can become the master. Our example cluster has only one node, so it performs the master role
As users, we can talk to any node in the cluster, including the master node. Every node knows where each document lives and can forward our request directly to the nodes that hold the data we are interested in. Whichever node we talk to manages the pro‐ cess of gathering the response from the node or nodes holding the data and returning the final response to the client. It is all managed transparently by Elasticsearch.
Cluster Health: Keeping Things Running Smoothly
Monitoring the health of your cluster is crucial. Elasticsearch clusters can be in one of three health states:
Green: Everything is perfect.
Yellow: All data is available, but some replicas are not allocated.
Red: Some data is not available.
Keeping your cluster in a green state is the goal, ensuring optimal performance and availability.
Example: Checking Cluster Health
curl -X GET "localhost:9200/_cluster/health"
Running this command will give you a clear snapshot of your cluster’s health, helping you identify and address issues before they become critical.
Add an Index: Organizing Your Data
Indexes in Elasticsearch are like databases in a traditional RDBMS. They are used to store related documents and make it easy to search through them.
Example: Creating an Index
curl -X PUT "localhost:9200/library?pretty"
This command sets up a new index named library, ready to store your documents.
Add Failover: Ensuring High Availability
Failover mechanisms are essential for maintaining data availability even when nodes fail. By configuring replicas, Elasticsearch creates redundant copies of your data.
Example: Configuring Replicas
curl -X PUT "localhost:9200/library/_settings" -H 'Content-Type: application/json' -d'
{
"index": {
"number_of_replicas": 1
}
}'
With this setup, your library index will have one replica, ensuring data redundancy and high availability.
Scale Horizontally: Growing with Your Data
Horizontal scaling in Elasticsearch means adding more nodes to your cluster, allowing it to handle more data and queries efficiently.
Example: Adding Nodes
To add a new node to your cluster, simply start another Elasticsearch instance with the same cluster name:
# On a new node, configure elasticsearch.yml:
cluster.name: my_cluster
Elasticsearch will automatically detect and integrate the new node into the cluster, enhancing its capacity.
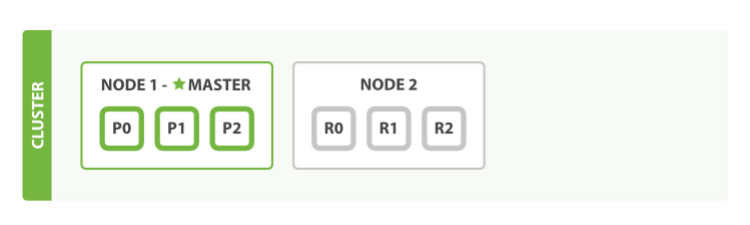
Then Scale Some More: Optimizing Performance
As your data grows, continue scaling by adjusting the number of shards. Shards are like partitions of your index that distribute data and load across the cluster.
Example: Adjusting Shards
What about scaling as the demand for our application grows? If we start a third node, our cluster reorganizes itself to look like
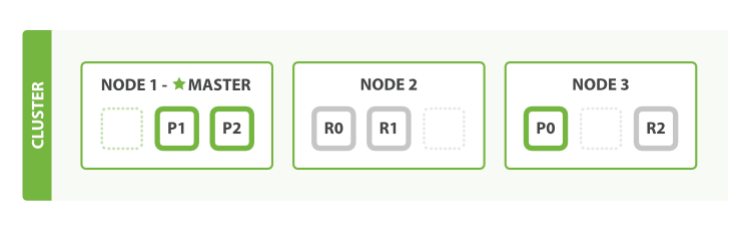
One shard each from Node 1 and Node 2 have moved to the new Node 3, and we have two shards per node, instead of three. This means that the hardware resources (CPU, RAM, I/O) of each node are being shared among fewer shards, allowing each shard to perform better. A shard is a fully fledged search engine in its own right, and is capable of using all of the resources of a single node. With our total of six shards (three primaries and three replicas), our index is capable of scaling out to a maximum of six nodes, with one shard on each node and each shard having access to 100% of its node’s resources.
As said before The number of replica shards can be changed dynamically on a live cluster, allowing us to scale up or down as demand requires. Let’s increase the number of replicas from the default of 1 to 2:
curl -X PUT "localhost:9200/library/_settings" -H 'Content-Type: application/json' -d'
{
"index": {
"number_of_replicas": 2
}
}'
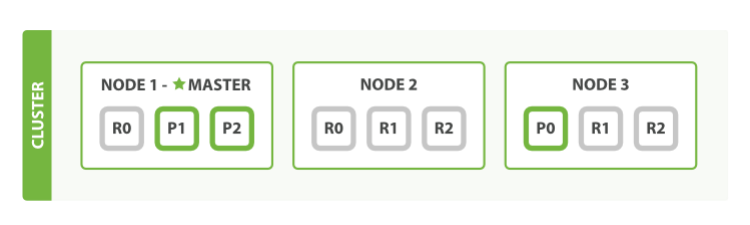
As can be seen index now has nine shards: three primaries and six replicas. This means that we can scale out to a total of nine nodes, again with one shard per node. This would allow us to triple search performance compared to our original three-node cluster.
Coping with Failure: Resilience in Action
Despite your best efforts, node failures can still happen. Elasticsearch is designed to handle these gracefully by automatically reallocating shards from failed nodes to healthy ones.
Example: Handling Node Failures
We’ve said that Elasticsearch can cope when nodes fail, so let’s go ahead and try it out. If we kill the first node, our cluster looks like
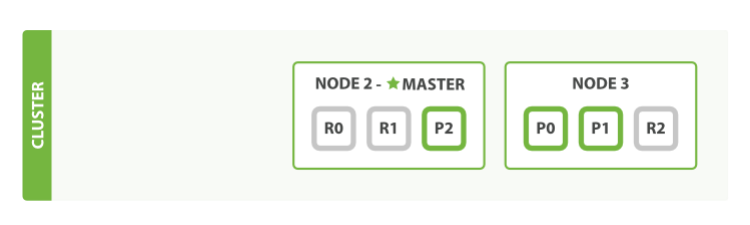
The node we killed was the master node. A cluster must have a master node in order to function correctly, so the first thing that happened was that the nodes elected a new master: Node 2. Primary shards 1 and 2 were lost when we killed Node 1, and our index cannot function properly if it is missing primary shards. If we had checked the cluster health at this point, we would have seen status red: not all primary shards are active!
When two primary shards are lost in an Elasticsearch cluster, the system promotes their replicas to primaries, quickly restoring cluster health to yellow. The health status is yellow, not green, because although all primary shards are available, one of the two specified replicas is missing.
Despite the yellow status, the cluster remains functional and can withstand further node failures without data loss, thanks to redundant shard copies. Restarting the failed node allows the cluster to reallocate the missing replicas and reuse old shard copies if possible.
This process demonstrates Elasticsearch's ability to scale horizontally and ensure data safety through efficient shard management.
Conclusion
Chapter 2 of "Elasticsearch: The Definitive Guide" takes us on a journey through the life inside an Elasticsearch cluster. From setting up and monitoring cluster health to scaling and ensuring resilience, this chapter equips you with the knowledge to manage a robust and efficient Elasticsearch deployment.
Stay tuned for more deep dives into Elasticsearch as we continue exploring its powerful features and capabilities. Until next time, happy Learning! 🚀
#Elasticsearch #DataScience #TechBlog #SearchEngine #TechJourney #ClusterManagement #Scalability #HighAvailability
Subscribe to my newsletter
Read articles from Khaled Hesham directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Khaled Hesham
Khaled Hesham
EX-SWE Trainee @ SIEMENS | EX-Data Engineer Intern @ EJADA | Backend Engineer