Apache Kafka 101: Key Features, Architecture, and Use Cases
 Jayakiran Guntuku
Jayakiran Guntuku
What is Apache Kafka?
Apache Kafka is a powerful, distributed streaming platform designed to handle real-time data feeds with high throughput, fault tolerance, and scalability. Initially developed at LinkedIn and open-sourced in 2011, Kafka has become a cornerstone of modern data architectures.
Kafka operates by allowing applications to publish and subscribe to streams of records, similar to a messaging system. However, it is designed to be far more robust and scalable than traditional messaging systems, making it suitable for large-scale, distributed environments.
In today's digital landscape, the ability to process and analyze data in real-time is crucial for gaining insights, improving user experiences, and maintaining competitive advantage. Apache Kafka has emerged as a key technology in modern data architectures, playing a vital role in handling real-time data feeds and enabling efficient data processing at scale
some key features that distinguish Kafka
High Throughput: Kafka can handle high volumes of data with low latency, making it ideal for applications that require real-time processing and analytics.
Fault Tolerance: Kafka achieves fault tolerance through data replication. Data is duplicated across multiple servers, ensuring that even if some servers fail, the data remains accessible and the system continues to function smoothly.
Scalability: Kafka's partitioned log model allows it to scale seamlessly to accommodate growing data volumes by distributing the data across multiple servers.
Durability: Kafka stores data on disk and maintains it for a configurable amount of time, allowing for persistent and reliable data storage.
Stream Processing: Unlike traditional message queues, Kafka is designed specifically for stream processing. It allows for continuous data flows where data is produced (written) and consumed (read) in a real-time fashion. This makes it ideal for applications that need to process data as it arrives.
Publish-Subscribe Messaging: Kafka employs a publish-subscribe messaging model where producers (data sources) publish messages to topics, and consumers (data sinks) subscribe to those topics to read the messages. This decouples data production from data consumption, allowing for flexible, scalable data flows.
Distributed System: Kafka is designed as a distributed system, which means it can scale out horizontally by adding more machines to the cluster. This makes it capable of handling massive data streams efficiently.
Kafka Architecture & Core Components
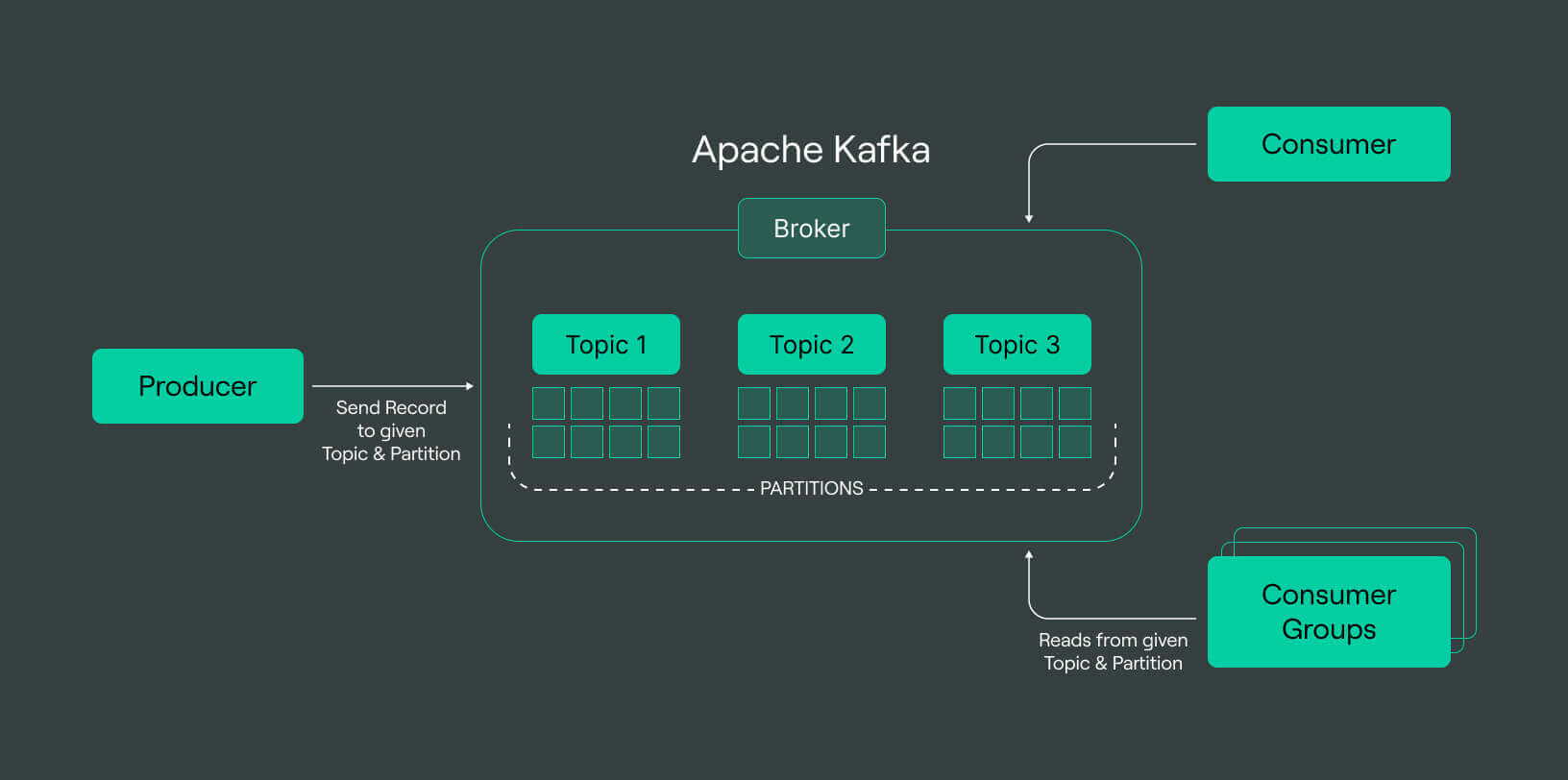
Apache Kafka is composed of several core components that work together to facilitate the production, storage, and consumption of real-time data streams. Here are the main components from the kafka architecture:
Brokers:
Brokers are Kafka servers that store data and serve client requests.
Functionality: A Kafka cluster comprises multiple brokers to ensure data distribution and fault tolerance. Each broker is responsible for maintaining a subset of partitions for the topics it handles.
Cluster Coordination: Brokers communicate with each other to coordinate activities and ensure data consistency across the cluster.
Topics
Topics are categories or feed names to which records (messages) are published.
Organization: Each topic is split into partitions, which allows Kafka to scale horizontally by distributing data across multiple brokers.
Retention: Topics can be configured with retention policies, determining how long Kafka retains data.
Partitions
Partitions are segments within topics that enable parallel processing.
Purpose: Each partition is an ordered, immutable sequence of records. Kafka appends new records to the end of the partition.
Scalability: By dividing a topic into multiple partitions, Kafka can spread the load across multiple brokers, enabling parallel processing by multiple consumers.
Producers
Producers are clients that publish (write) data to Kafka topics.
Mechanism: Producers send records to a specified topic, and Kafka brokers handle the partitioning and storing of these records.
Key Features: Producers can choose partitioning strategies, such as round-robin or key-based partitioning, to control data distribution.
Consumers
Consumers are clients that subscribe to (read) data from Kafka topics.
Mechanism: Consumers read data from one or more partitions of a topic. Kafka ensures that each record is processed by a single consumer within a consumer group.
Consumer Groups: Multiple consumers can form a consumer group. Kafka assigns each partition to only one consumer within the group, enabling parallel processing and load balancing.
ZooKeeper
ZooKeeper is a centralized service for maintaining configuration information, naming, and providing distributed synchronization and group services.
Role in Kafka: In Kafka, ZooKeeper is used to manage and coordinate brokers, handle leader elections for partitions, and maintain metadata about topics and partitions.
Transition: Kafka is in the process of removing the dependency on ZooKeeper, with the introduction of the KRaft (Kafka Raft) protocol, which aims to handle metadata management and broker coordination natively within Kafka.
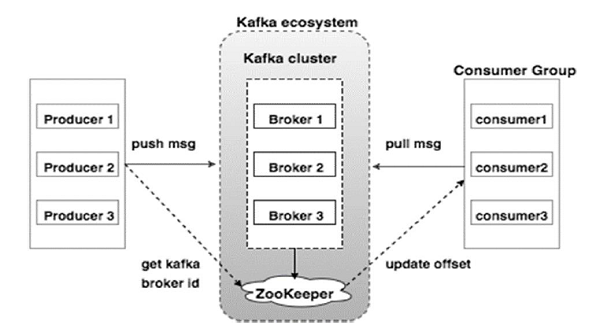
Key Points To Remember
Producers can send messages to any topic.
Consumers subscribe to topics and receive messages from all partitions of the topic.
Each consumer group maintains its own offset (position) within each partition, allowing for parallel consumption from the same topic without data loss.
Partitions can be replicated across brokers for fault tolerance.
Apache Kafka Use-cases
Message Broker: Kafka serves as an excellent replacement for traditional message brokers. Compared to traditional massage brokers, Apache Kafka provides better throughput and is capable of handling a larger volume of messages. Kafka can be used as a publish-subscribe messaging service and is a good tool for large-scale message processing applications.
Tracking Website Activities: The activity associated with a website, that includes metrics like page views, searches, and other actions that users take, is published to a centralized topic which in turn contains a topic for each type of activity. This data can be further used for real-time processing and real-time monitoring.
Monitoring Metrics: Kafka finds applications in monitoring the metrics associated with operational data. Statistics from distributed applications are consolidated into centralized feeds to monitor their metrics.
Stream Processing: A widespread use case for Kafka is to process data in processing pipelines, where raw data is consumed from topics and then further processed or transformed into a new topic or topics, that will be consumed for another round of processing. These processing pipelines create channels of real-time data. Kafka version 0.10.0.0 onwards, a powerful stream processing library known as Kafka Streams, has been made available in Kafka to process data in such a format.
Event Sourcing: Event sourcing refers to an application design that involves logging state changes as a sequence of records ordered based on time.
Logging: Kafka can be used as an external commit-log for a distributed application. Kafka’s replication feature can help replicate data between multiple nodes and allow re-syncing in failed nodes for data restoration when required. In addition, Kafka can also be used as a centralized repository for log files from multiple data sources and in cases where there is distributed data consumption. In such cases, data can be collected from physical log files of servers and from numerous sources and made available in a single location.
Conclusion
In this introduction, we covered the essential aspects of Kafka, including its key components, such as brokers, topics, partitions, producers, and consumers. We also delved into its distributed architecture, highlighting how Kafka achieves high throughput, fault tolerance, and scalability. Moreover, we discussed the significance of Kafka in modern data environments, showcasing its versatility and widespread adoption across various industries.
I hope this article has provided a valuable starting point and inspired you to explore the powerful world of Apache Kafka. Stay tuned for more articles in this series, where we will delve into advanced configurations such as Kafka Streams, Kafka Connect, and the new KRaft protocol.
Subscribe to my newsletter
Read articles from Jayakiran Guntuku directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jayakiran Guntuku
Jayakiran Guntuku
Backend Engineer @Purplle