Big Data Processing - How it All Started
 samyak jain
samyak jainIt started with an interesting thought of making the whole internet searchable. Mike Cafarella and Doug Cutting who started working on development of an open source web search engine. A search engine that can index billions of pages, back then project was named as Apache Nutch Project.
Apache Nutch project was basically a program that “crawls” the Internet, going from page to page, by following URLs between them.
For testing they deployed Nutch on a single machine of single-core processor, 1GB of RAM, RAID level 1 on eight hard drives, amounting to 1TB, they managed to achieve indexing rate of around 100 pages per second.
BUT !!!
After their research, they estimated that such a system will cost around half a million dollars in hardware, with a monthly running cost of $30,000, which is quite expensive.
They soon realized that their architecture will not be capable enough to work around with billions of pages on the web.
. . .
Now the destiny dives in.
In 2003 they came across a paper published by Google describing their distributed file system called GFS (Google File System), which was being used in production at that time.
They quickly realized that it could solve their problems of storing very large files that are generated as a part of the web crawl and indexing process.
Main Challenges Faced -
Fault-tolerance - To handle Hard disk failures , concept of replication of data was introduced.
Durability - Data should never be lost once written to disk.
Automated Rebalancing - So that all disk space are utilized equally
Data Locality - Data was stored on the same nodes where it will be processed, reducing network overhead and improving performance.
Streaming Data - HDFS is optimized for high-throughput sequential data access patterns, making it suitable for applications like batch processing and data warehousing.
HDFS borrowed several key concepts from GFS, including the idea of splitting files into blocks (typically 128 MB in HDFS) and distributing those blocks across multiple nodes in the cluster. This distributed storage approach allows HDFS to achieve scalability, fault tolerance, and high throughput.
Later , with improvements and modification they developed their file system NDFS later called HDFS (Hadoop Distributed File System).
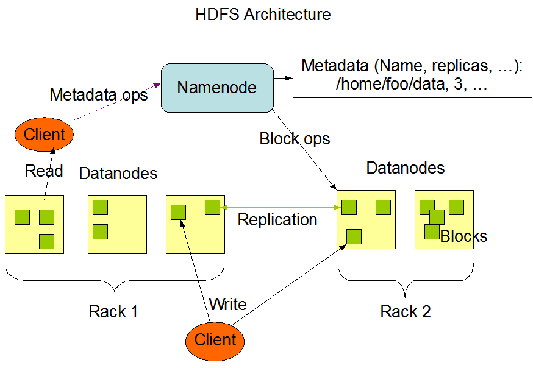
Now they were mostly sorted with the storage part, but what is the use of storing the data if you can't process it to the required format.
Now their quest continued on developing various algorithms to process the distributed data stored in their file systems.
And again , by luck,
In December 2004, Google publishes a paper written by Jeffrey Dean and Sanjay Ghemawat , named - "MapReduce: Simplified Data Processing on Large Clusters."
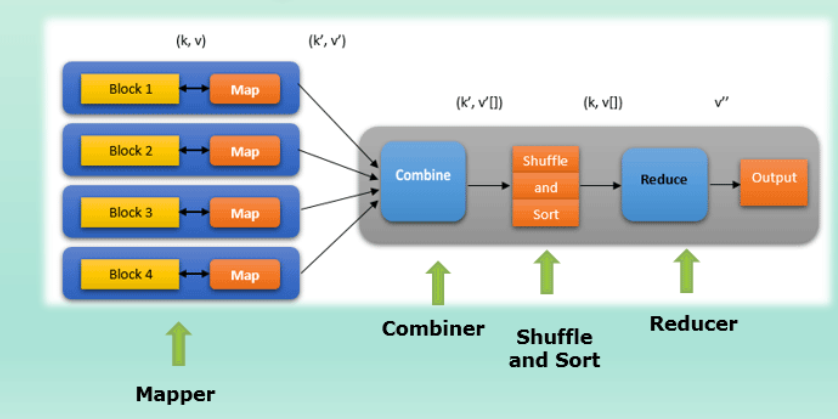
Problems Solved by Map-Reduce :
Parallelism - MapReduce is based on Divide and Conquer paradigm which helps us to process the data using different nodes parallely at the same time. As the data is processed by multiple machines instead of a single machine in parallel, the time taken to process the data gets reduced by a significant amount.
Distribution - Overall Job is distributed into multiple tasks, which are further assigned to multiple nodes. Each node executes the given task , which is further accumulated (reduced) by the reducer to give final output.
Fault-Tolerance- Every single map and reduce task are executed independently, and if one task fails, it is automatically retried for a few times without causing the entire job to fail.
Next Steps -
Apache Hadoop - Getting Started (Understanding the Basics)
https://dataskills.hashnode.dev/apache-hadoop-getting-started-understanding-the-basics
Subscribe to my newsletter
Read articles from samyak jain directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
samyak jain
samyak jain
Hi there, I'm Samyak Jain , a seasoned data & analytics professional with problem solving mindset, passionate to solve challenging real world problems using data and technology.