Unsupervised Learning
 Retzam Tarle
Retzam Tarle
print("Unsupervised Learning")
Unsupervised Learning is a type of machine learning task that uses unlabeled input data to train a model.
Unlike in supervised learning where the data is clearly labelled and we want to use the data (feature vectors) to predict a possible outcome, in unsupervised learning the data is not labelled (unlabelled) and we want to determine what type of data it is by classifying them into groups based on their features(patterns, structures, shapes etc).
Unlabelled data is data without a label(name). This type of data does not have any identifier, so no means of identification.
Let me explain this with an illustration. Consider the image below
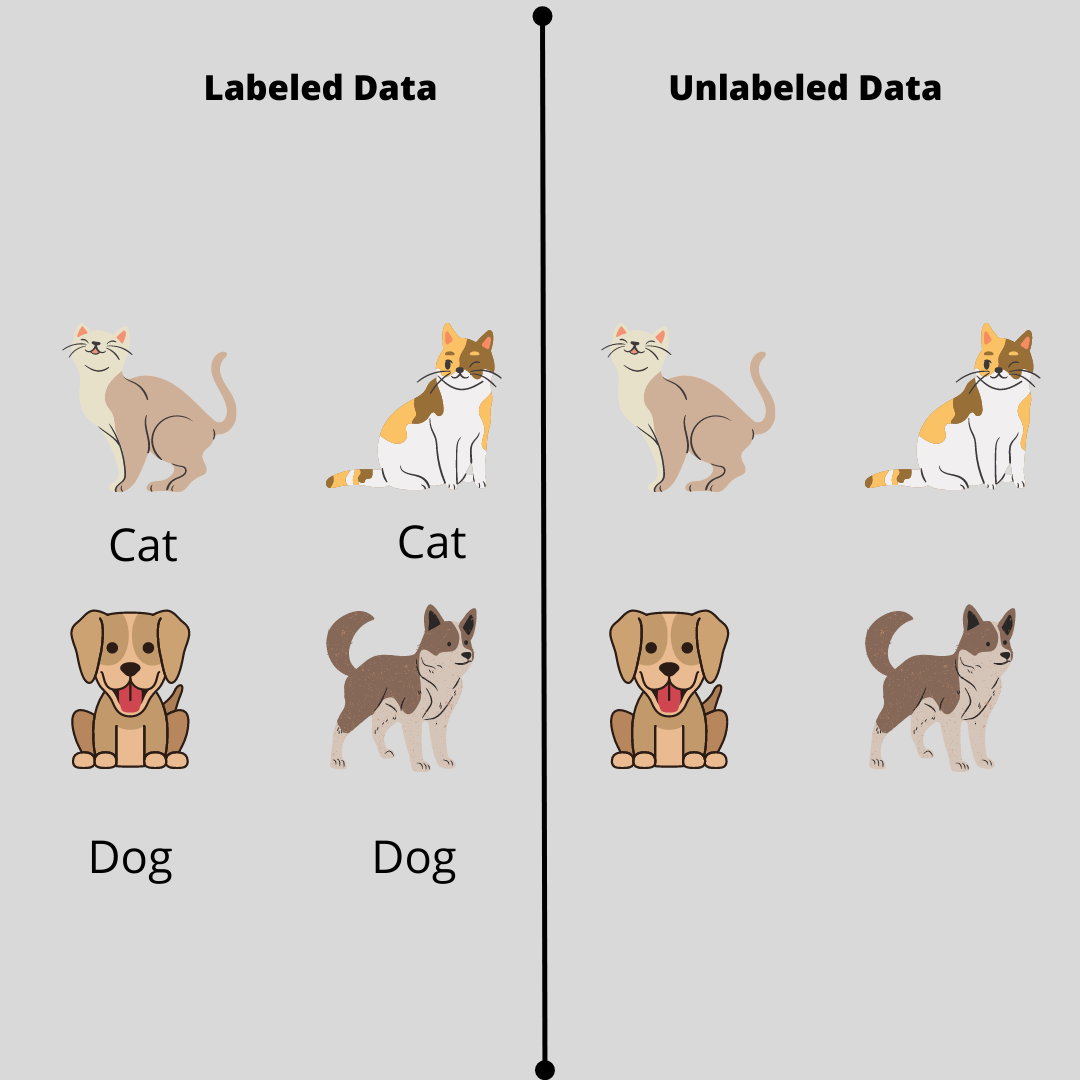
This shows the difference between labelled and unlabelled data. We can see that labelled data has a name while unlabelled data does not. In Unsupervised learning, the aim is to be able to classify the unlabelled data into groups based on their features, shapes, characteristics etc.
In simple terms unsupervised learning is used to understand data we have no idea about, while supervised learning is used on data we know to make predictions.
Consider receiving a deck of cards to sort, now you don't know what any of the cards are called. What do you do? You group each card based on the shape of the image on the card. See the illustration below:
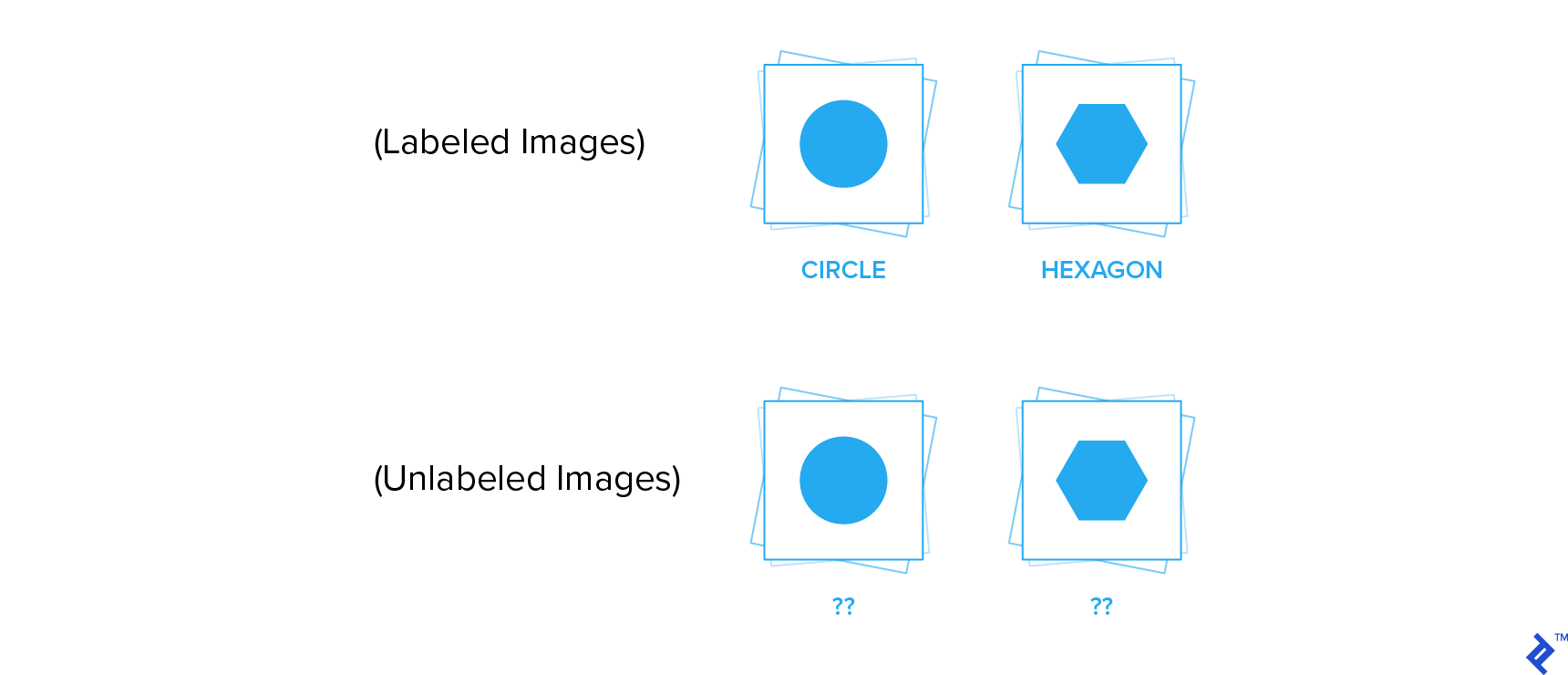
You'll group them as shown in (unlabeled images), and then you can proceed to give them a name as seen in (labelled images). So we can group cards based on the number of edges in the image, we can have two groups:
The group with 1 edge - which we can name as a circle.
Group with 6 edges - which we can name as a hexagon.
The principles of unsupervised learning can be seen in a lot of fields, like animal classes such as amphibians, mammals etc. These were grouped based on their features and given a name.
As you can see unsupervised and supervised learning are actually birds 🕊️ of the same feather 🪶, as they both complement each other. Unsupervised learning helps us label and group unknown items, supervised learning then helps us make predictions based on the grouped data.
I believe by now we clearly understand the concept of unsupervised learning.
There 2 major techniques used in unsupervised learning tasks:
Clustering: This simply means grouping similar data with similar features into groups and classes called clusters. We can see that in our card deck group illustration.
Dimensionality Reduction: This involves reducing the number of features in the dataset while retaining as much information as possible. So that complexity is reduced.
We'll talk more about these in subsequent chapters.
That'll be all for this chapter 🤖
In our next chapter, we'll talk about Clustering in Unsupervised Learning. It'll be very interesting 🤗, see ya 👽
Subscribe to my newsletter
Read articles from Retzam Tarle directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Retzam Tarle
Retzam Tarle
I am a software engineer.