Apache Hadoop - Getting Started (Understanding the Basics)
 samyak jain
samyak jainHadoop is an open-source software framework used for storing and processing Big Data in a distributed manner on large clusters of commodity hardware. Hadoop is licensed under the Apache v2 license.
Hadoop was developed, based on the paper written by Google on the MapReduce system and it applies concepts of functional programming. Hadoop is written in the Java programming language and ranks among the highest-level Apache projects. And Of Course! was developed by Doug Cutting and Michael J. Cafarella.
Hadoop-As-Solution :
Storing huge amount of data -
HDFS provides a distributed way to store Big Data. Your data is stored in blocks in DataNodes and you specify the size of each block.Hadoop follows horizontal scaling instead of vertical scaling. In horizontal scaling, you can add new nodes to HDFS cluster on the run as per requirement, instead of increasing the hardware stack present in each node.
Storing a variety of data -
Can store all kinds of data whether it is structured, semi-structured or unstructured. In HDFS, there is no pre-dumping schema validation. It also follows write once and read many models. Due to this, you can just write any kind of data once and you can read it multiple times for finding insights.
Processing Speed -
Hadoop resolved this problem by introducing the concept of “move the processing unit to data instead of moving data to the processing unit”. It means that instead of moving data from different nodes to a single master node for processing, the processing logic is sent to the nodes where data is stored so as that each node can process a part of data in parallel. Finally, all of the intermediary output produced by each node is merged together and the final response is sent back to the client.
HADOOP ARCHITECTURE -
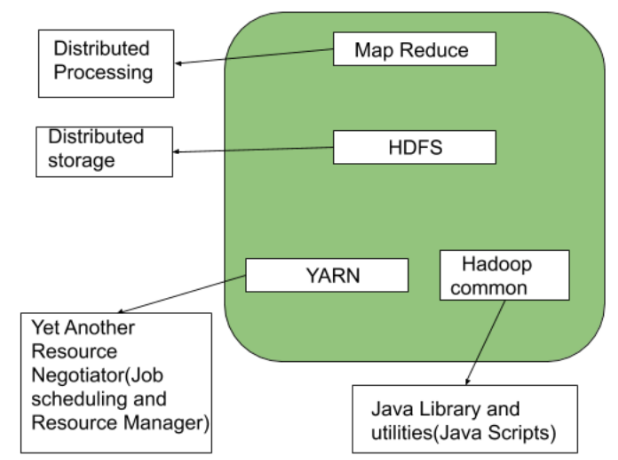
Storage Unit - HDFS (Hadoop Distributed File System)
Processing Unit - Map Reduce
Management Unit - YARN (Yet Another Resource Negotiator)
External Dependencies and libraries - Hadoop common
Background Processes - Hadoop Daemons
Lets discuss them in detail -
- HDFS - Hadoop Distributed File System , as its name suggests it is a distributed file system. That means data is stored over multiple nodes/machines providing the scalability to store data size greater than disk size of a single machine.
Key Features
a. Data Replication - Same data is replicated over multiple nodes to keep backup of data.
b. Fault Tolerant - Even if a node/machine goes down , data can be retrieved from another node having its replication
c. Data Block Size - HDFS organizes data into fixed-size blocks, with the default block size being 128 megabytes (MB). The use of fixed-size blocks simplifies data management and allows for efficient storage and retrieval.
d. Rack Awareness - HDFS ensures that data nodes having replicas of same data exists on different rack, to reduce chances of data loss in case of rack failure .
A Rack is physical storage unit having a collection of machines
It also prioritizes reading of different chunks of data from same rack nodes to reduce network traffic and read latency.
Components of HDFS -
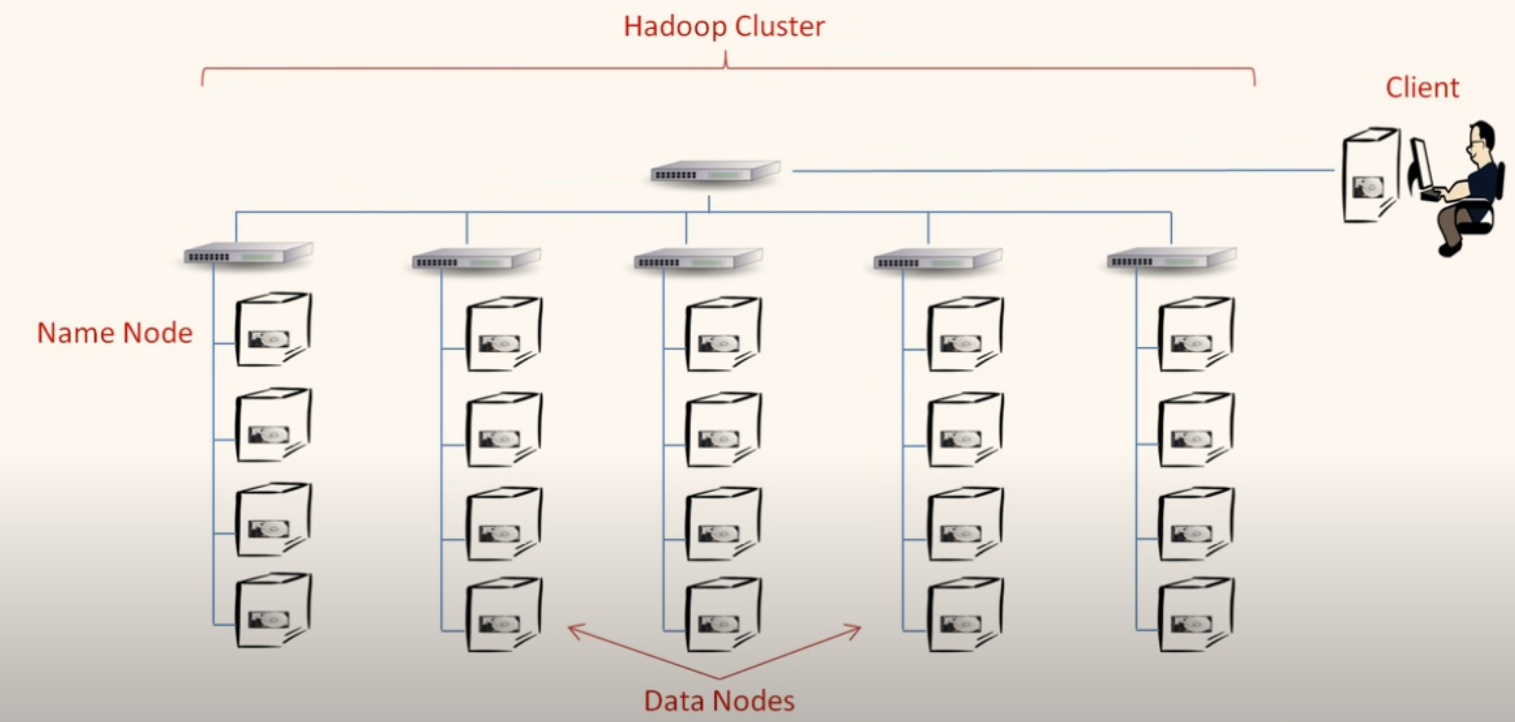
Name Node - It contains the metadata and location of each data block. It has all the mappings (namespace) to data blocks present in the cluster. Just like windows filesystem stores files with namespaces like C://Documents/Document1.pdf, it stores file namespaces like hdfs://Documents/Document1
Data Node - It contains the actual data in its disk. Name Node has its path with itself and just retrieves the data from this node when required.
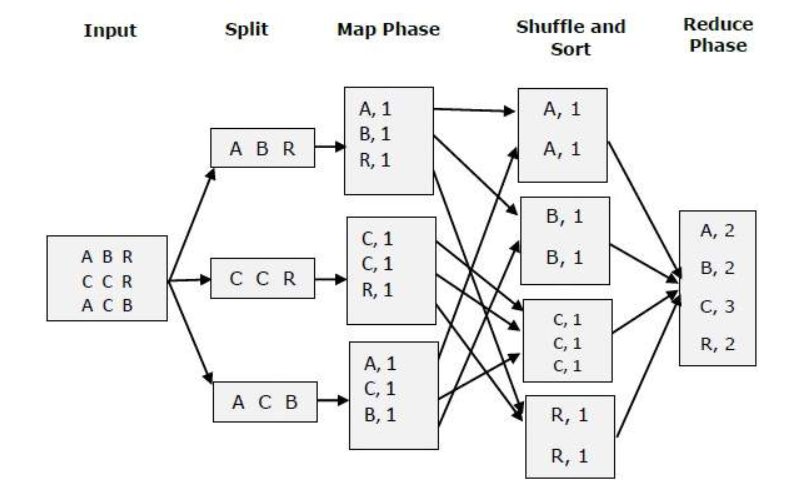
- Map Reduce -
It is the processing unit of Hadoop. It has 2 components, mapper and reducer.
Mapper is responsible for splitting and mapping the data into multiple nodes, while the reducer, for shuffling and reducing the data to get final output.
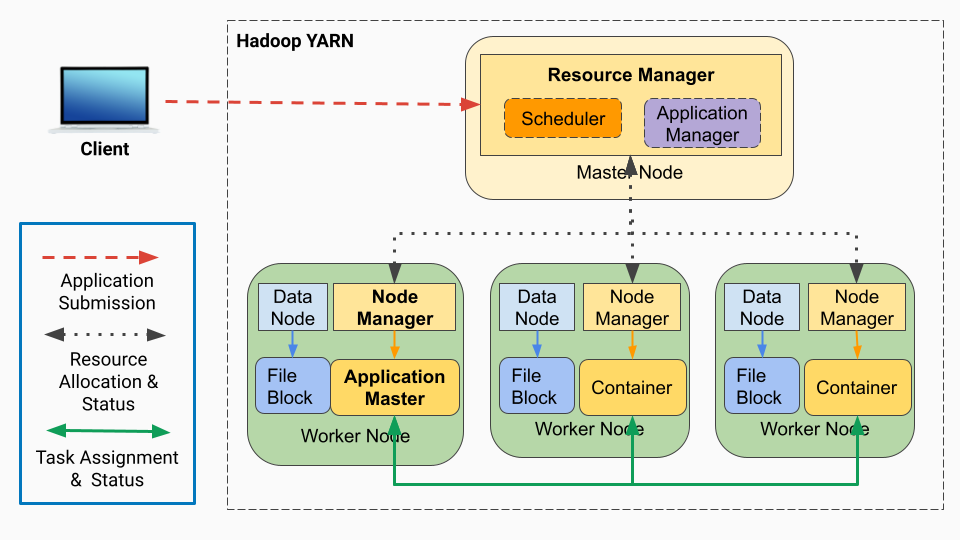
- YARN (Yet Another Resource Negotiator) -
Its name tells it all.
It acts as a resource Negotiator between Master and slave nodes. Basically it checks available resources from worker nodes and tells the master node that this worker node can be utilized to perform the required task.
Components of YARN -
Application Manager — It runs on master node for HDFS
Resource Manager — It runs on slave nodes for HDFS
Node Manager — It runs on master node for Yarn
NodeManager — It runs on slave node for Yarn
Hadoop Common -
It includes the libraries needed by Hadoop modules.
Hadoop Daemons -
Daemons are the processes that run in the background. There are mainly 4 daemons which run for Hadoop.
Hadoop Daemons
Namenode — It runs on master node for HDFS
Datanode — It runs on slave nodes for HDFS
ResourceManager — It runs on master node for Yarn
NodeManager — It runs on slave node for Yarn
Subscribe to my newsletter
Read articles from samyak jain directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
samyak jain
samyak jain
Hi there, I'm Samyak Jain , a seasoned data & analytics professional with problem solving mindset, passionate to solve challenging real world problems using data and technology.