Automated telemetry capture via Python bytecode modification
 Jean-Mark Wright
Jean-Mark Wright
Introduction
Ever heard the expression "Don't byte off more than you can chew"? Today, I've got one of those stories about our attempt to capture telemetry automatically using Python by introducing hooks at the bytecode level. Our company has several teams managing 20+ microservices and thousands of endpoint. We have a successful manual telemetry capture pattern that significantly reduces incident investigation time by enriching and attaching telemetry to our tools like DataDog, Sentry, and Sumo. However, it's too time-consuming for widespread adoption across all teams. Our team implemented this pattern efficiently, but replicating it manually for other teams would take years! This lead us to explore and eventually abandon an overly complex automated bytecode capture approach.
Below is the story of that journey.
Motivation
Ultimately we want to increase our business uptime by reducing incident recovery time. We achieve this by enhancing our production experience through access to high quality telemetry for investigation. We're aiming to replicate a local debugger in production. Enhancing system state visibility accelerates our investigations, which reduces disruption time. If we're able to clearly see system state when looking at a trace, or an error, or log, we'll drastically reduce remediation time. High quality telemetry provides a solid base for hypotheses creation and testing.
We've had successes that confirm that this approach works too. We had an incident where we inadvertently gave free access to some premium features. We got to our root cause for that issue in less than 15 minutes thanks to the tooling improvements. In that incident, we zoomed out from an individual trace and aggregated over a suspicious property which confirmed our theory. We had another incident where we fixed a broken Kafka worker and it caused data corruption for a running migration. Again, examining traces and inspecting system state was critical for understanding issues quickly.
Step 0 - The existing, manual process
Let's take a look at what our manual process looks like. Below I'm showing the code for a SubscriptionAPI. This represents the highest component in our architecture. An API typically calls a service, then a repository for data operations. You'll see there's a Context (alias for a Python dictionary) that we start adding information to. That's us collecting telemetry. Below we're adding the input values to the Context like the api, user_id, business_id, plan_id (the subscription's plan) and eventually the serialized_subscription we generate as the API output. The Context is then passed down the hierarchy to all other calls. In this scenario, the SubscriptionAPI calls the SubscriptionService.create_subscription method. It passes the ctx to that method so we can continue to populate it.
class SubscriptionAPI:
def create_subscription(
self, ctx: Context, plan_id: UUID, user_id: UUID, business_id: UUID
):
# Start capturing telemetry (using a dictionary "ctx")
ctx["api"] = "create_subscription"
ctx["user_id"] = str(user_id)
ctx["plan_id"] = str(plan_id)
ctx["business_id"] = str(business_id)
# Call the service to create a subscription
subscription = SubscriptionService().create_subscription(
ctx, plan_id=plan_id, user_id=user_id, business_id=business_id
)
# Serialize the subscription to JSON for return
serialized_subscription = {
"id": str(subscription.id),
"plan_id": str(subscription.plan_id),
"user_id": str(subscription.user_id),
"business_id": str(subscription.business_id),
"status": subscription.status.value,
}
ctx["serialized_subscription"] = serialized_subscription
return serialized_subscription
As we populate the ctx in each layer of the application, we end up with a rich description of our current system state.
Below is an example of us invoke the SubscriptionAPI and then examining the Context.
# Declare variables (plan_id, user_id, etc...)
ctx = {}
subscription_api = SubscriptionAPI()
subscription_api.create_subscription(
ctx, plan_id, user_id, business_id)
print(ctx)
The output of the Context looks like this:
{"api": "create_subscription",
"business_id": "bc7464cc-dd17-481e-88a4-93ba5711f2a1",
"plan_id": "43a3ec11-ba1d-4fff-a958-f3945fc46a36",
"serialized_subscription": {"business_id": "bc7464cc-dd17-481e-88a4-93ba5711f2a1",
"id": "f2dc517e-5c9c-4f55-8a26-ef43dd7bc0ef",
"plan_id": "43a3ec11-ba1d-4fff-a958-f3945fc46a36",
"status": "active",
"user_id": "61346915-3c35-4ba4-87fd-7d092053c940"},
"status": "active",
"user_id": "61346915-3c35-4ba4-87fd-7d092053c940"}
This manual capture approach works well when you're starting fresh and you establish this as a team practice. However, when you've got thousands of endpoints scattered across multiple services without the pattern, we need an automated approach.
Let's dive into the steps we took on the journey to automated telemetry capture.
Step 1 - Capture variables in a method
The first step is understanding how we capture all the variables in a method. Once we can capture variables in one method, we can extend this approach to the rest of the architecture stack. Python provides a facility for accomplishing this. We can use inspect.stack() to get local variables from a function. The stack stores variables for each function being called. Python creates a frame for each function being called. Let's see how this works in practice.
class SubscriptionAPI:
def create_subscription(
self, ctx: Context, plan_id: UUID, user_id: UUID, business_id: UUID
):
# Call the service to create a subscription
subscription = SubscriptionService().create_subscription(
ctx, plan_id=plan_id, user_id=user_id, business_id=business_id
)
# Serialize the subscription to JSON for return
serialized_subscription = {...}
# Capture all the variables in the method
stack = inspect.stack()
local_variables = stack[0].frame.f_locals
# Capture all the local variables in the context
ctx.update(local_variables)
return serialized_subscription
Near the end of our create_subscription function, we're accessing the stack and printing the locals in the first frame (i.e. at index 0). This gives us all the local variables in the current function (i.e. create_subscription). Every time Python calls a function, it creates a frame for it and stores the locals.
If we run the create_subscription method and examine the ctx, it looks like this:
{'business_id': UUID('bbe18a98-d565-4423-a13a-1c17b38b003d'),
'plan_id': UUID('81df53ad-2159-4566-b43f-3c24d55d9d3e'),
'serialized_subscription': {'business_id': 'bbe18a98-d565-4423-a13a-1c17b38b003d',
'id': '977ac956-496f-4b54-8627-a0fd4fc3e9df',
'plan_id': '81df53ad-2159-4566-b43f-3c24d55d9d3e',
'status': 'active',
'user_id': 'ade39122-70b9-47f8-94e9-6ab4926e7398'},
'subscription': Subscription(id=UUID('977ac956-496f-4b54-8627-a0fd4fc3e9df'),
plan_id=UUID('81df53ad-2159-4566-b43f-3c24d55d9d3e'),
user_id=UUID('ade39122-70b9-47f8-94e9-6ab4926e7398'),
business_id=UUID('bbe18a98-d565-4423-a13a-1c17b38b003d'),
status=<SubscriptionStatus.ACTIVE: 'active'>),
'user_id': UUID('ade39122-70b9-47f8-94e9-6ab4926e7398')}
As you see from the output, we've captured all the fields from the create_subscription method.
Let's add a visual to concretize the concept.

When we call SubscriptionAPI.create_subscription, Python pushes a frame unto the stack. That frame contains the locals of our method.
Sounds good! We're making progress.
Step 2 - Capture the locals from functions we call
We don't only need to capture the locals from the SubscriptionAPI call, but all the other components (e.g. services, repositories, clients) it calls to satisfy our request. The SubscriptionAPI will call the SubscriptionService to create the subscription. The SubscriptionService will in turn, call the repository (SubscriptionRepository) to convince the database to create the data.
Let's look at a quick sequence diagram to concretize the picture in our minds.
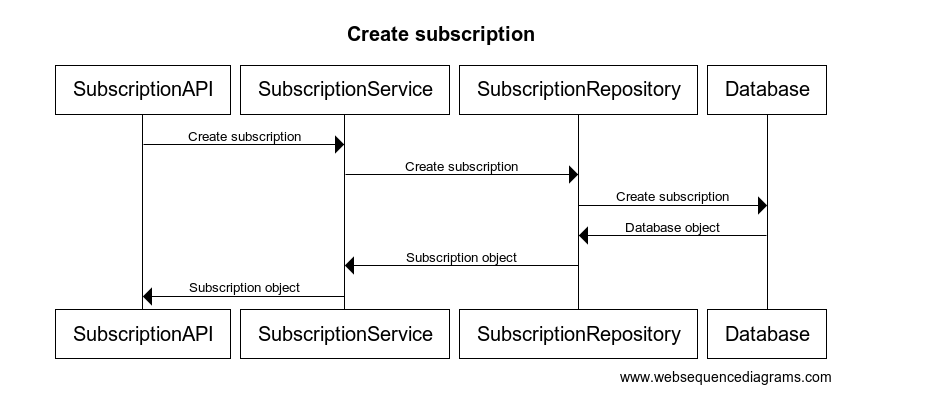
Thankfully, Python can help us here too! Python captures all the variables for all the functions that get called. We learned earlier that each time Python invokes a function, it creates a stack frame with the locals. When a function calls another function, Python creates a new stack frame for the new function and its locals. So as functions are calling other functions, Python pushes new frames unto the stack. As such, we just need to loop through each frame to capture all the variables.
Let's look at the code for each of the components. They're mostly passthroughs.
class SubscriptionRepository:
def create_subscription(
self,
ctx: Context,
plan_id: UUID,
user_id: UUID,
business_id: UUID,
status: SubscriptionStatus,
):
# Pretend we're calling the ORM to create the subscription
# Serialize the output as a Subcription value object
return Subscription(...)
class SubscriptionService:
def create_subscription(
self, ctx: Context, plan_id: UUID, user_id: UUID, business_id: UUID
) -> Subscription:
status = SubscriptionStatus.ACTIVE
return SubscriptionRepository().create_subscription(...)
class SubscriptionAPI:
def create_subscription(
self, ctx: Context, plan_id: UUID, user_id: UUID, business_id: UUID
):
# Call the service to create a subscription
subscription = SubscriptionService().create_subscription(...)
# Serialize the subscription to JSON for return
serialized_subscription = {...}
return serialized_subscription
If we were to look at the stack, when the SubscriptionRepository.create_subscription function is being interpreted, the stack would contain frames for the calling components (i.e. API and service).
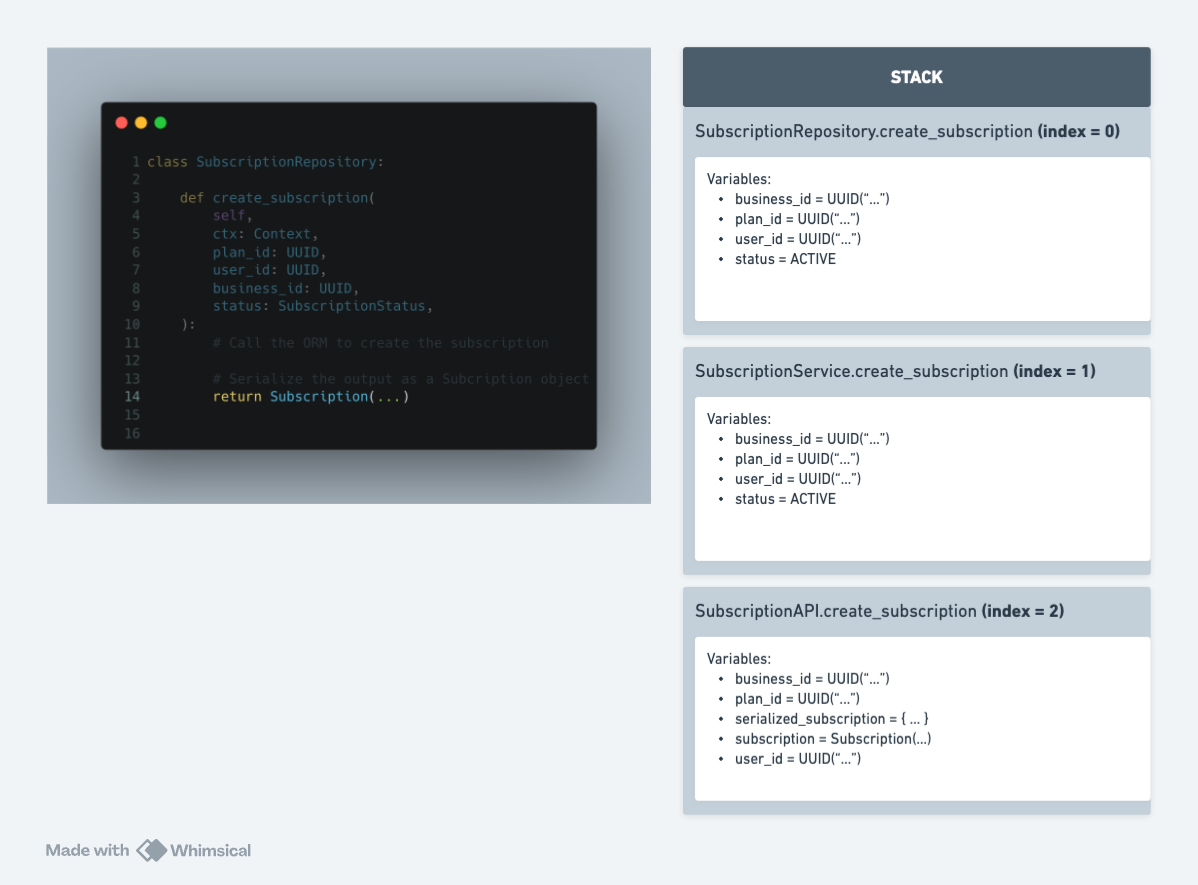
First, there's a frame for the current method (i.e. SubscriptionRepository.create_subscription) with all its variables. It was called by SubscriptionService.create_subscription, so there's a stack for that. Finally, the service was called by SubscriptionAPI.create_subscription so there's a frame for that one as well.
Let's look at how we'd achieve that.
def get_variables_from_all_calls() -> dict:
"""Get all the variables in the method that called us."""
local_variables = {}
stack = inspect.stack()
# We don't want the current frame, that's this function
all_frames_except_this_one = stack[1:]
for frame_information in all_frames_except_this_one:
frame = frame_information.frame
local_variables.update(frame.f_locals)
return local_variables
class SubscriptionRepository:
def create_subscription(
self,
ctx: Context,
plan_id: UUID,
user_id: UUID,
business_id: UUID,
status: SubscriptionStatus,
):
# Call the ORM to create the subscription
# Update the context with variables from all calls in the stack
ctx.update(get_variables_from_all_calls())
# Serialize the output as a Subcription object
return Subscription(...)
In this example, I'm introducing a helper (get_variables_from_all_calls) to move the logic outside of our main function. Since the repository will call this method, that means Python will add a frame to the stack for this helper function as well. As such, we need to get all the frames except the current one. This explains why we're only capturing frames from index 1 and beyond. Finally, in SubscriptionRepository.create_subscription we're calling get_variables_from_all_calls to get all the variables for us.
When we run the code, the ctx has the following contents:
{'business_id': UUID('3498a3df-5001-481c-b0b8-a007609fb93c'),
'plan_id': UUID('fefbbafd-0f59-49bb-9255-3c09eef38fec'),
'status': <SubscriptionStatus.ACTIVE: 'active'>,
'user_id': UUID('de19ca36-67c5-48eb-80c8-70b0db9575ac')}
If you're paying close attention, you'll notice this list is a little shorter than the last time we printed out the Context. In particular, this is missing the serialized_subscription and subscription object found in the SubscriptionAPI.create_subscription method. That happens because when we're capturing the variables, those don't exist yet.
See below if you're not convinced.
class SubscriptionAPI:
def create_subscription(
self, ctx: Context, plan_id: UUID, user_id: UUID, business_id: UUID
):
# The subscription variable is defined AFTER the call returns
subscription = SubscriptionService().create_subscription(...)
# Similarly, this is also defined AFTER the call returns
serialized_subscription = {...}
return serialized_subscription
We'll keep going! That's a small problem in the grand scheme of things. As you'll see in the next step... we've got bigger problems.
Step 3 - Don't touch the code
One of our primary goals was to enable telemetry without manual effort. If we need to be adding a bunch of get_variables_from_all_calls calls all over our code, that simply won't work. It's less work than manually adding every variable, but still too much effort. Additionally, we don't want folks to modify their code to include these calls. We want these utilities to be mostly invisible but providing all the benefits necessary.
Let's iterate and see what we can accomplish...
What if we tried capturing the stack variables after the we made the function call.
subscription_api = SubscriptionAPI()
ctx = {}
subscription_api.create_subscription(
ctx, plan_id, user_id, business_id)
# Capture all variables
get_variables_from_all_calls()
If we print out the context of the Context, we'd get the following:
{}
The Context is empty. Yeah, that's right... it's completely empty.
Here comes another important detail I omitted before...
Once a function is done executing, Python pops its frame from the stack.
So... if you were to look at the stack at this point, it'd be empty (technically there's a "module" frame, but I've omitted that for brevity). There are no other frames on the stack, because after the function calls have exited, the frames associated with each call are completely gone. All of the previous approaches worked because we were capturing variables while we were in the call stack. Once those functions have exited we're no longer in the call stack and don't have access to those variables.
So we need a different approach. We need to capture variables while the relevant frames still exist on the stack. But how...
Step 4 - Byte off more than you can chew
It turns out, there's a way we can utilize the same approach, without modifying the code folks would write. We can introduce our capturing logic, at a lower-level... much lower. When we write Python code, it gets compiled into bytecode, which is then run by the interpreter.
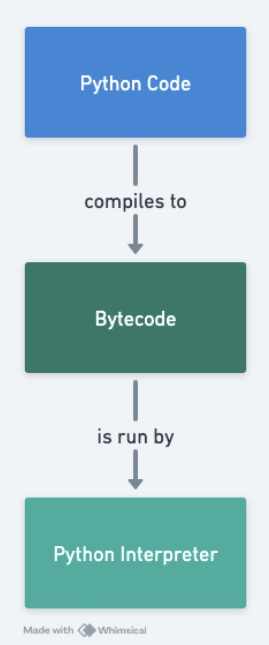
We could modify the bytecode to accomplish the same objective. Python bytecode looks very different from Python. It's a sequence of instructions for the Python virtual machine. These instructions manipulate the internal stacks that Python uses. By modifying the resulting bytecode we can inject our logic and have the compiler execute our logic and capture the variables.
To exactly replicate what we did at a higher level, we need to capture the stack just before the function returns. So, we'd need to parse the bytecode instructions, looking for a return statement and then inject our logic right before that. We'd insert our logic to call the get_variables_from_all_calls function which would extract the variables from the stack. Then finally we'd relace the function's bytecode with our patched version. Sounds simple enough, right?
There are lots of different bytecode instructions. The following are the ones we're interested in:
LOAD_GLOBAL- this instruction enables us to make our function available for calling. This instruction tells Python to look up an object in the global namespace and place it on the evaluation stack. We'll use this to make our function ready for calling.LOAD_FAST- this instruction enables us to provide arguments for a function call. This pushes a variable unto the stack for evaluation.CALL_FUNCTION- this instruction is used to execute our function call. With this instruction we can also provide a number of positional arguments that should be popped and passed to the function.POP_TOP- this instruction allows us to remove our function from the stack to continue the flow of the program. We'll use this to pop our function after we've called it.
Next, I need to explain an idiosyncrasy we have to be familiar with to make this all work. Sometimes instructions spans multiple lines. We only need to add our patching instructions once. As such, we need to keep track of whether we've patched a line already so we don't do it multiple times.
Armed with that knowledge let's examine the function that does the patching.
def patch_function_to_capture_stack_variables(func):
# Get the bytecode that we plan to patch
code = func.__code__
bytecode = Bytecode.from_code(code)
# Get a list of all line numbers for return instructions
# Recall instructions can span multiple lines
return_line_numbers = [
instruction.lineno
for instruction in bytecode
if instruction.name == "RETURN_VALUE"
]
# For each return instruction, we want to insert a call to capture_stack
for return_line_number in return_line_numbers:
# construct the instructions we need
# Add our function to the stack
add_capture_stack_function_to_the_stack = Instr("LOAD_GLOBAL", "get_variables_from_all_calls")
# Add the ctx as an argument for the function
add_ctx_as_an_argument = Instr("LOAD_FAST", "ctx")
# Call our function and pop 1 arguemnt (ctx) to be passed to the function
call_the_capture_stack_function = Instr("CALL_FUNCTION", 1)
# Remove our function to continue normal processing
remove_the_capture_stack_function_from_the_stack = Instr("POP_TOP")
# Put the instructions all together
catpure_stack_instructions = [
add_capture_stack_function_to_the_stack,
add_ctx_as_an_argument,
call_the_capture_stack_function,
remove_the_capture_stack_function_from_the_stack,
]
for i, instruction in enumerate(bytecode):
if instruction.lineno == return_line_number:
bytecode[i:i] = catpure_stack_instructions
# There could be other instructions on the same line
# We don't want to insert the new instructions multiple times
# So break out of the loop
break
updated_code = bytecode.to_code()
func.__code__ = updated_code
As shown in the code above, we're getting the bytecode, adding instructions to call our function and then applying the patch. We start by getting the __code__ object of the function. That's the bytecode! We're using the bytecode library to simplify going to and from bytecode and construction of instructions. Next, we find all the lines that have return instructions. Finally, we construct our new instructions and add them to the bytecode.
Finally, we patch the SubscriptionRepository.create_subscription function so it'll call our function.
patch_function_to_capture_stack_variables(
SubscriptionRepository.create_subscription)
subscription_api = SubscriptionAPI()
subscription_api.create_subscription(
ctx, plan_id, user_id, business_id)
print(ctx)
Running this code, gets us the following output:
{'business_id': UUID('276dac6c-68ad-48bf-8a55-ac7ee6df64a5'),
'plan_id': UUID('e72b5c80-63d7-4c5a-a2a9-d4b5eef937e0'),
'status': <SubscriptionStatus.ACTIVE: 'active'>,
'user_id': UUID('946bf774-e95a-488d-b5b5-55a255aa5d2a')}
Success! Without asking anyone to modify their code, we were able to capture the local variables from the stack! This provides significant gains as we're able to reduce the manual effort involved. It's leaps and bounds further than where we started.
You'll notice though that it's the same output as step 3. It still has the shortcoming where it doesn't capture variables that haven't been defined yet. There are ways to overcome this that don't take too much effort and don't re-introduce manual effort. Anyway... that's a story for another time.
Step 5 - Choke
I've had to acknowledge that despite the energy rush this investigation brought, its complexity is well beyond our company's maintenance capacity. None of us are experts in the topic of bytecode. Theoretically, we're not doing much -- we're simply hooking into the code at a lower level. We wanted to avoid folks littering their code with our hooking logic, so we moved down an abstraction layer or two. That descent was unfortunately dangerously close to 6 feet under. Writing our Observability tooling hooks in bytecode would be suicidal for our tooling's life.
What's worse, is that the implementation I've described thus far is woefully inadequate. We'd need to make several improvements and additions to begin the journey to production. We'd need some more bytecode instructions to import our library from elsewhere (in the script it's defined in the same file). Discover and account for additional idiosyncrasies of bytecode. We haven't addressed the multiple ways that functions can exit (e.g. early returns, unexpected exceptions and try-catch scenarios). Additionally, we would want to make our code more robust. We don't want failures in our library to cascade to the rest of the application. We'd probably need to catch all failures in our calls and properly log them (e.g. Sentry, SumoLogic, DataDog, etc...), or capture with metrics. Then, finally, we haven't thought about optimization or security. Who knows what challenges lie in that space!
And so, we've started investigating alternatives. We've got some basic ideas we're toying around. One idea is to reduce the complexity, by only capturing function inputs and outputs. We could use a decorator-based approach to wrap public methods of all our components and capture the variables. We can implement our wrapping logic in a metaclass that we use to initialize our different components (e.g. services, repositories, clients, etc...). It's early days and we're still exploring things. I'll return to blog about our success (let's hope!) once we've found a working solution.
Conclusion
In our attempt to automate telemetry capture using Python, we explored the ambitious idea of introducing hooks at the bytecode level to automate this process. While our manual approach of enriching telemetry within our services has proven effective in reducing incident investigation time, scaling this across multiple teams and microservices was impractical. Our journey involved understanding Python's stack and bytecode intricacies to capture local variables across function calls. Despite the surge and adrenaline of this approach, the unavoidable complexity and maintenance challenges, lead us to abandon this method. We're now considering simpler, more maintainable alternatives like using decorators to capture function inputs and outputs.
Thanks for reading! If you've got thoughts on this topic, I'd love to hear it! Feel free to reach out to me on Twitter or LinkedIn!
Also, many thanks to the DataDog library I reverse-engineered to get an idea of how this could be accomplished.
Here are a few resources that were helpful, if you're looking to learn more about bytecode.
Subscribe to my newsletter
Read articles from Jean-Mark Wright directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jean-Mark Wright
Jean-Mark Wright
Jean-Mark is an articulate, customer-focused, visionary with extensive industry experience encompassing front and back end development in all phases of software development. He lives "outside the box" in pursuit of architectural elegance and relevant, tangible solutions. He is a strong believer that team empowerment fosters genius and is versed at working solo.