Understanding Transformers in Deep Learning
 Ishika Ishani
Ishika Ishani
Introduction
In the realm of natural language processing (NLP), the transformer model has revolutionized the field. Introduced in the seminal paper "Attention Is All You Need" by Vaswani et al. in 2017, the transformer architecture has become the foundation for many state-of-the-art models like BERT, GPT, and T5. This blog will delve into the intricacies of transformers, their advantages over previous models like Recurrent Neural Networks (RNNs), and an in-depth look at the transformer architecture itself, including both the encoder and decoder components.
What is a Transformer?
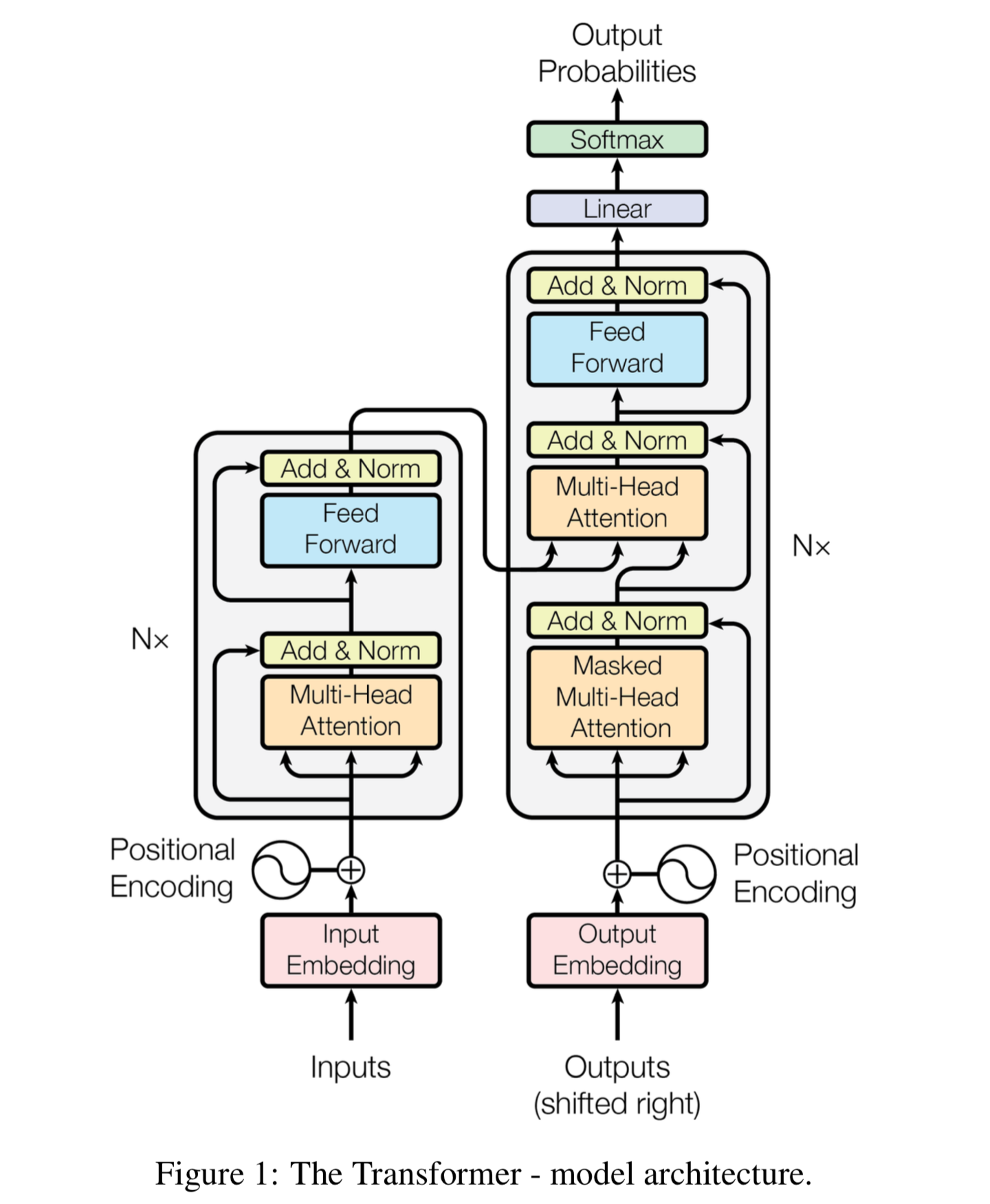
A transformer is a deep learning model designed to handle sequential data, making it especially useful for tasks like machine translation, text summarization, and more. Unlike RNNs, which process data sequentially, transformers leverage an attention mechanism that allows them to process the entire sequence of data at once, enabling greater parallelization and efficiency.
Recurrent Neural Networks (RNNs) and Their Limitations
Before diving into the transformer model, it's essential to understand the limitations of RNNs that transformers address.
Vanishing Gradient Problem: RNNs suffer from the vanishing gradient problem during backpropagation, making it difficult to train models on long sequences. Gradients tend to diminish as they are propagated back through layers, hindering the learning process.
Sequential Computation: RNNs process sequences one step at a time, which limits their ability to leverage parallel processing. This sequential nature makes RNNs computationally expensive and slow.
Handling Long Dependencies: RNNs struggle with capturing long-range dependencies in sequences. The information from earlier steps in the sequence can be lost by the time it reaches the later steps.
Scalability: Due to their sequential nature, RNNs do not scale well with increasing data size and complexity. Training large RNNs is resource-intensive and time-consuming.
Advantages of Transformers
Transformers overcome the limitations of RNNs through several key innovations:
Self-Attention: The self-attention mechanism allows transformers to consider the entire sequence of data at once. Each word (or token) in the input sequence can attend to every other word, capturing dependencies regardless of their distance in the sequence.
Positional Encoding: Since transformers process the entire sequence simultaneously, they need a way to encode the position of each word. Positional encoding adds a unique vector to each word embedding, allowing the model to understand the order and relative positions of words.
Parallel Processing: Unlike RNNs, transformers can process all elements of the input sequence simultaneously, enabling efficient parallelization and faster training.
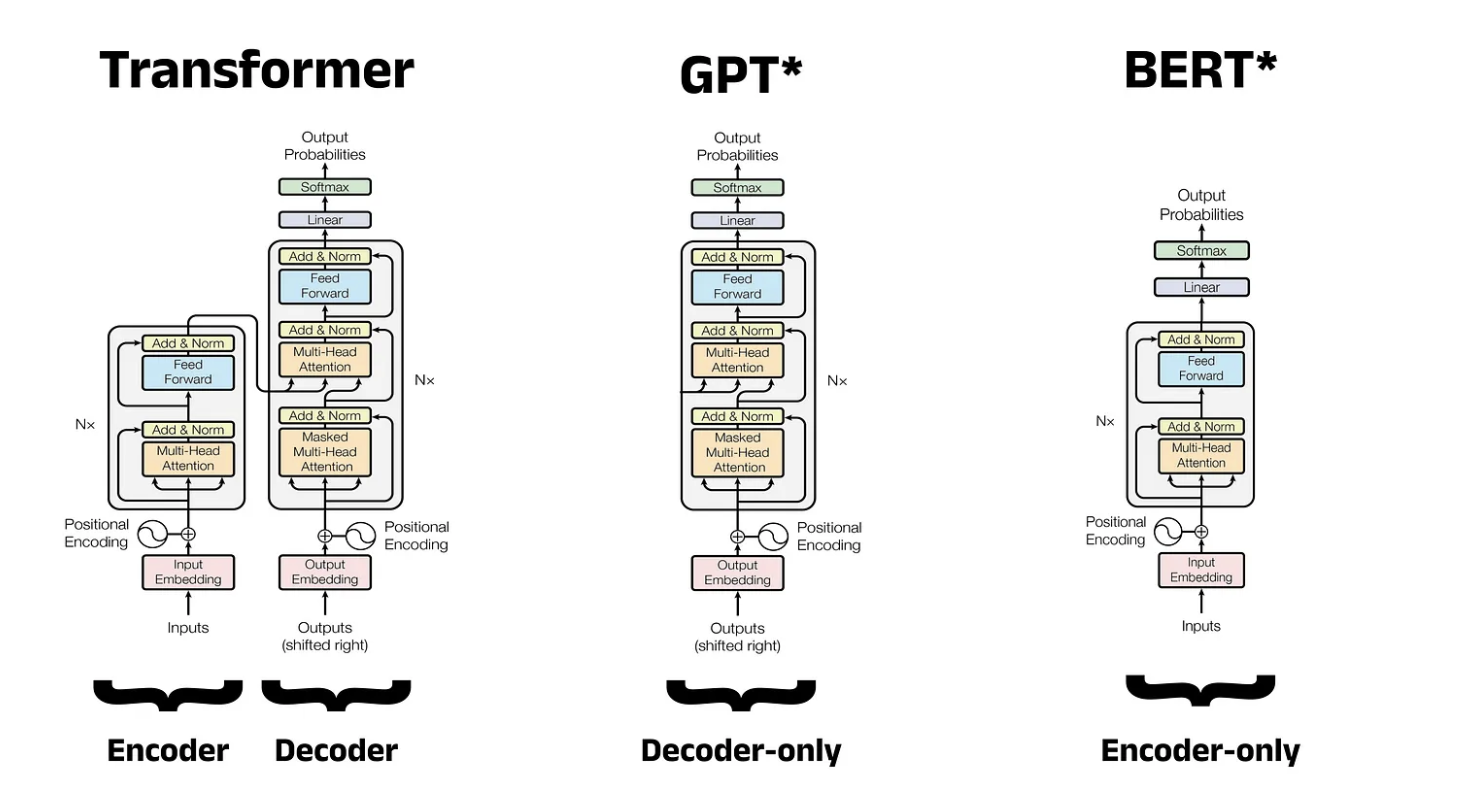
Encoder-Decoder Architecture: The transformer model uses a stacked encoder-decoder architecture. The encoder processes the input sequence, and the decoder generates the output sequence. This modular design allows transformers to be highly flexible and effective for various tasks.
Introduction to "Attention Is All You Need"
The groundbreaking paper "Attention Is All You Need" introduced the transformer model and its attention mechanism. The key idea is that attention mechanisms, particularly self-attention, are sufficient for sequence-to-sequence tasks without the need for recurrent or convolutional layers.
The Encoder Component
The transformer encoder consists of a stack of identical layers, each with two sub-layers: a multi-head self-attention mechanism and a position-wise fully connected feed-forward network. The paper stacks six encoders, though this number can be adjusted.
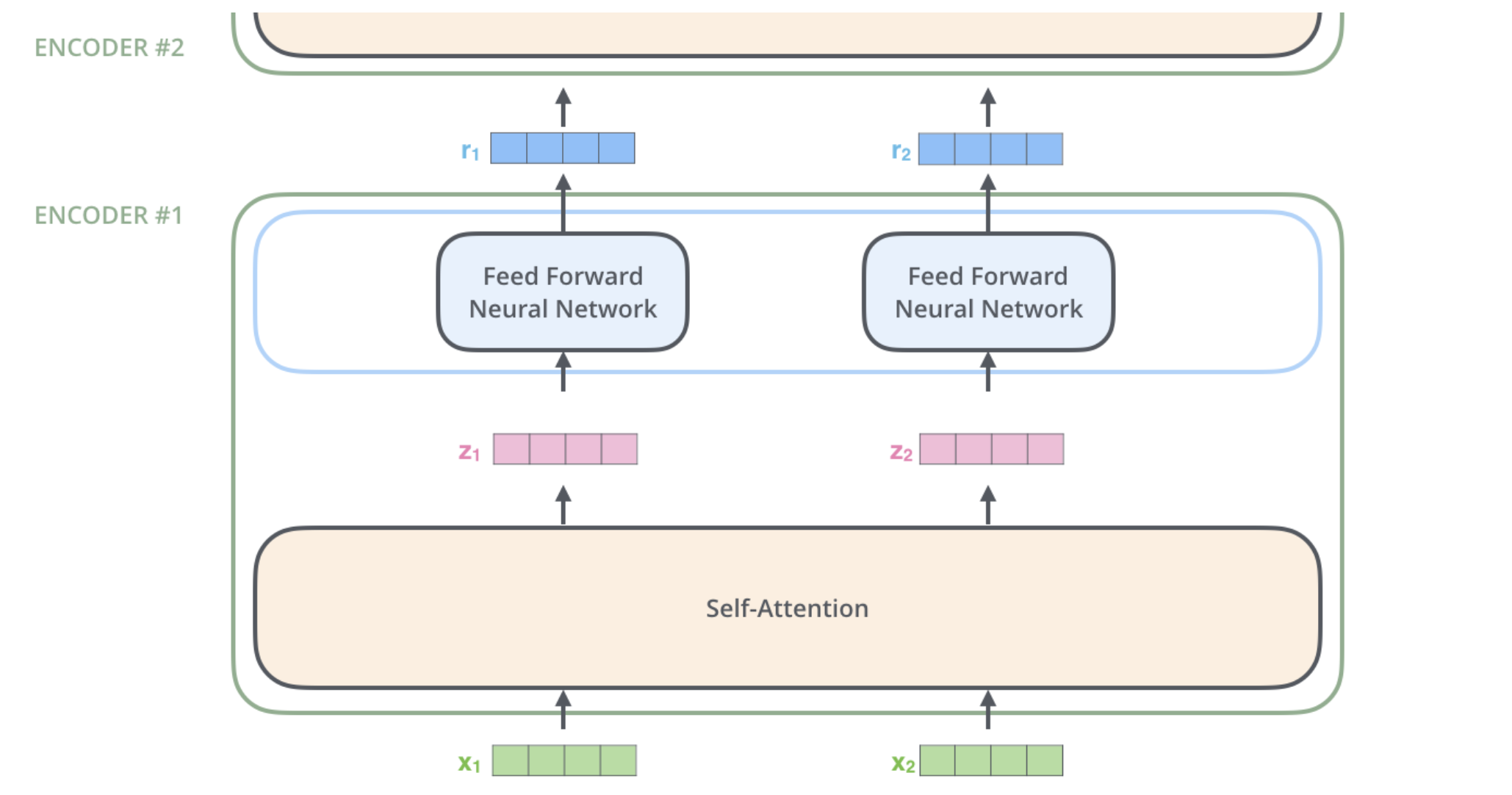
Detailed Breakdown of the Encoder
Embedding and Positional Encoding: The input sequence is first embedded into continuous vectors. Positional encoding is then added to these embeddings to retain the positional information of words.
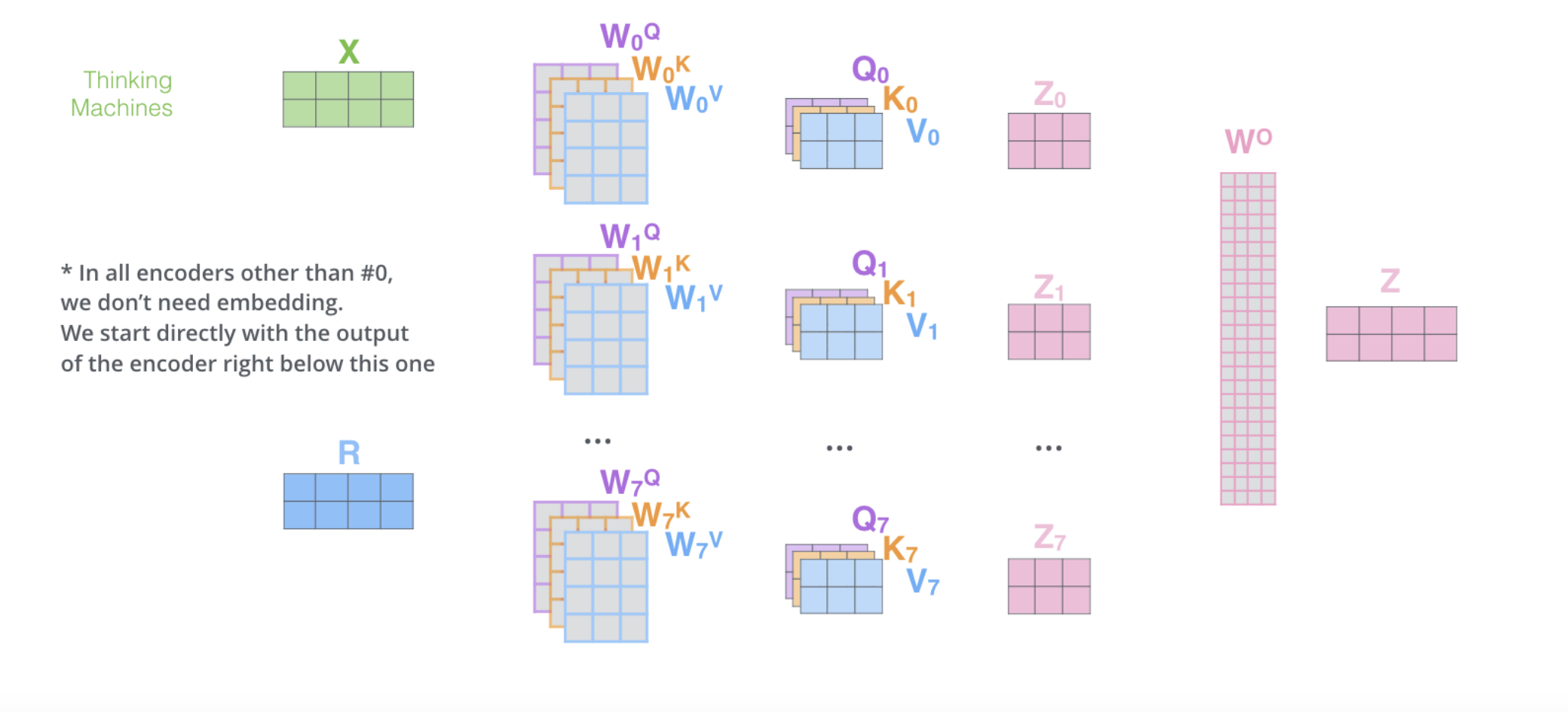
Multi-Head Self-Attention: Each word in the input sequence generates three vectors: Query (Q), Key (K), and Value (V). These vectors are used to compute attention scores, which determine how much focus each word should have on other words in the sequence. Multi-head attention allows the model to attend to information from different representation subspaces at different positions.
Attention Calculation:
Scaled Dot-Product Attention: The attention scores are computed using the dot product of Q and K, scaled by the square root of the dimension of K. These scores are then passed through a softmax function to obtain attention weights, which are used to compute a weighted sum of the V vectors.
Concatenation and Linear Transformation: The results from multiple heads are concatenated and linearly transformed to produce the output of the self-attention layer.
Feed-Forward Network: The output from the self-attention layer is passed through a position-wise fully connected feed-forward network. This consists of two linear transformations with a ReLU activation in between.
Residual Connections and Layer Normalization: To facilitate gradient flow, residual connections are added around each sub-layer, followed by layer normalization.
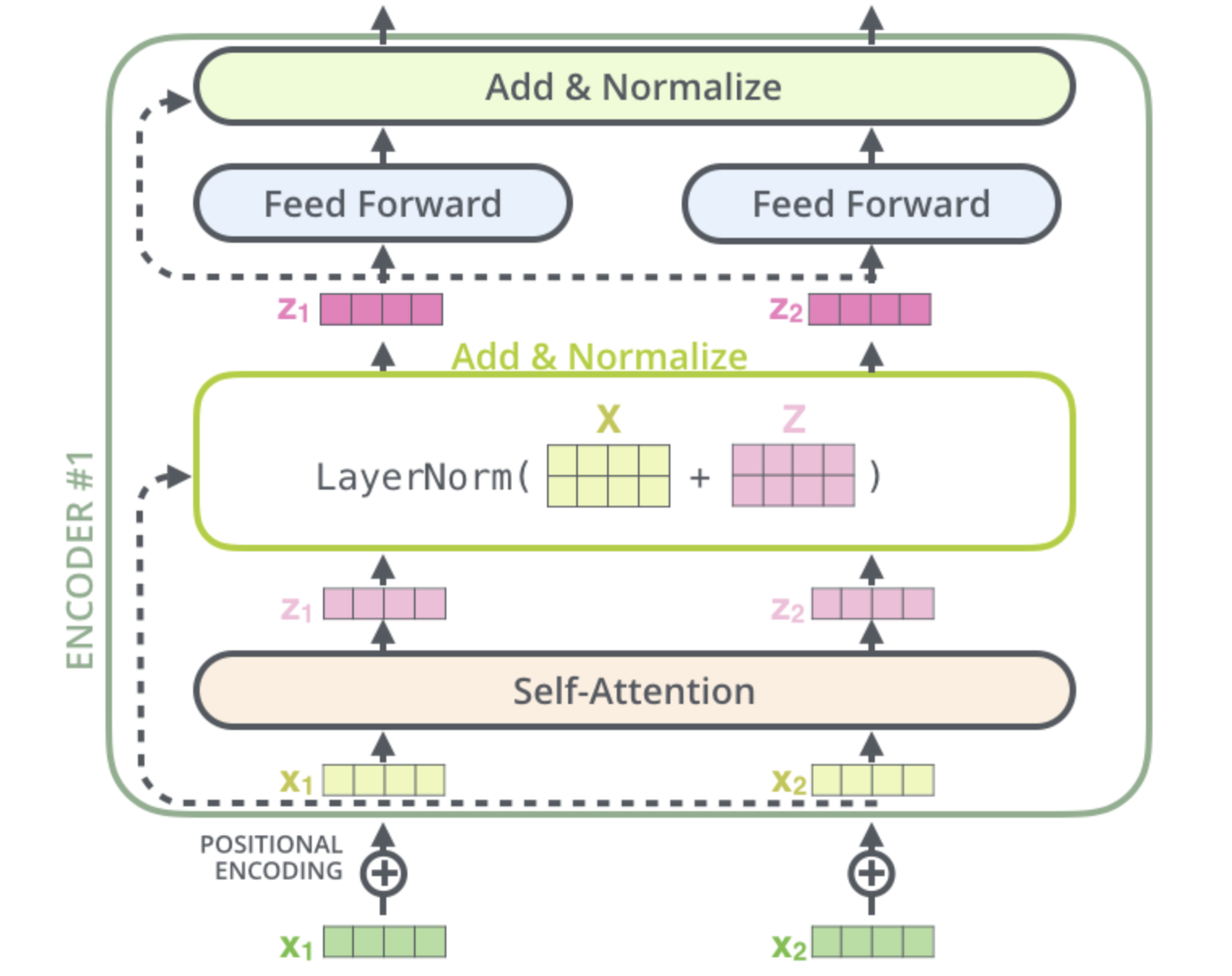
Positional Encoding
Transformers use positional encodings to inject information about the position of each word in the sequence. These encodings are added to the word embeddings, enabling the model to capture the order of the words. The positional encodings follow a specific pattern that the model learns, providing meaningful distances between embedding vectors during the attention calculation.
The Decoder Component
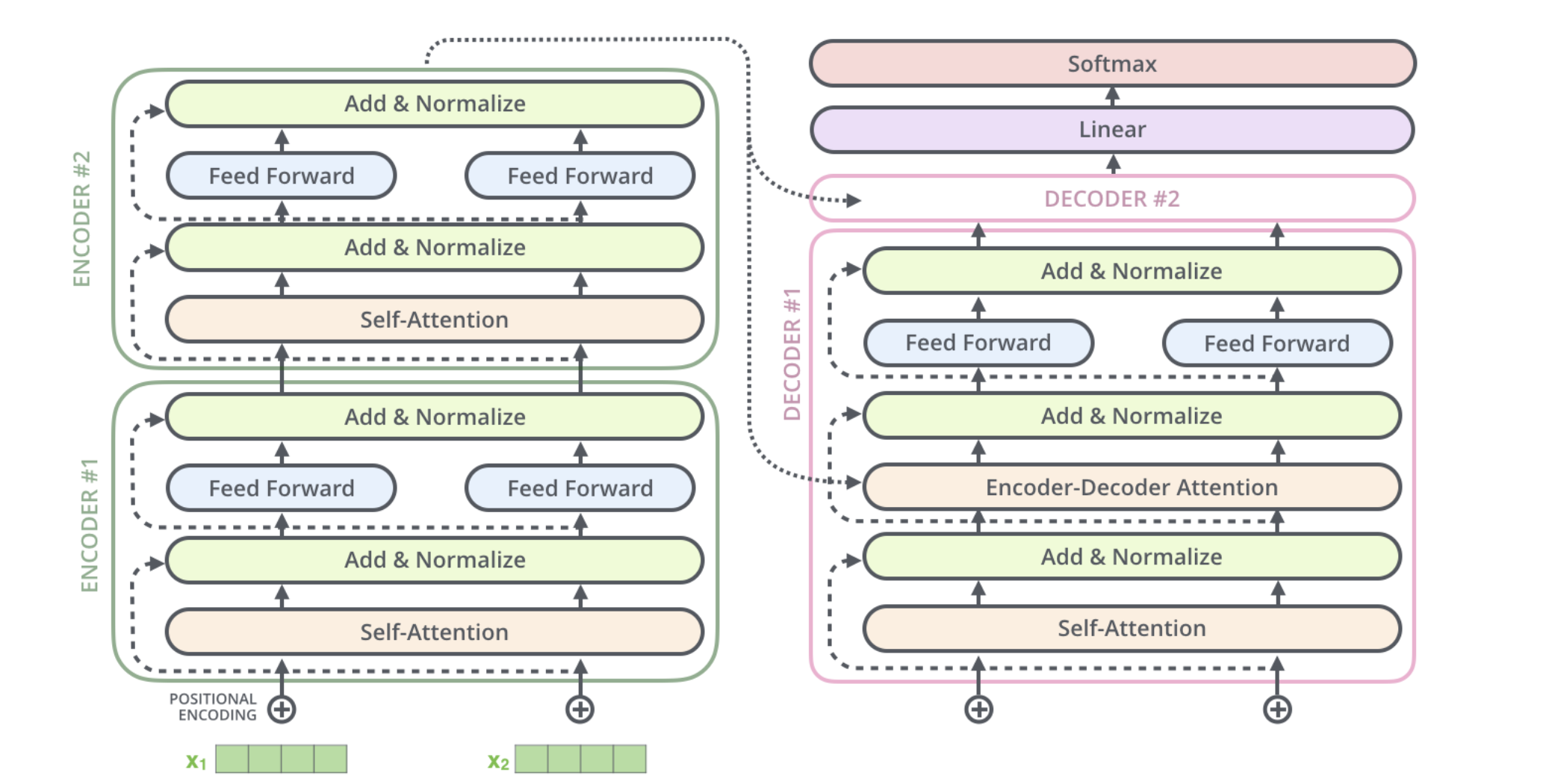
The transformer decoder is also a stack of identical layers, mirroring the encoder's structure but with additional mechanisms to handle the input from the encoder.
Detailed Breakdown of the Decoder
Masked Multi-Head Self-Attention: The decoder's self-attention layer is masked to prevent attending to future tokens, ensuring that the predictions for a particular position depend only on the known outputs at preceding positions.
Encoder-Decoder Attention: This layer performs attention over the output of the encoder stack, allowing the decoder to focus on relevant parts of the input sequence.
Feed-Forward Network and Residual Connections: Similar to the encoder, the decoder has a position-wise feed-forward network and residual connections with layer normalization.
Positional Encoding: As with the encoder, positional encoding is added to the input embeddings of the decoder to provide positional information.
Decoder Workflow
The encoder processes the input sequence and produces a set of attention vectors K and V. The decoder uses these vectors in its encoder-decoder attention layer to focus on appropriate places in the input sequence. The output of each decoder step is fed to the next step, continuing until a special symbol indicating completion is reached.
BERT: Bidirectional Encoder Representations from Transformers
BERT (Bidirectional Encoder Representations from Transformers) is one of the most well-known models built on the transformer architecture. BERT uses only the encoder part of the transformer and is pre-trained on large corpora using two tasks: masked language modeling and next sentence prediction.
Pre-training BERT
Masked Language Modeling (MLM): In this task, some percentage of the input tokens are masked, and the model is trained to predict the masked tokens based on their context. This allows BERT to learn bidirectional representations.
Next Sentence Prediction (NSP): BERT is trained to predict whether a given pair of sentences is continuous or not, helping it understand sentence relationships and improving performance on tasks like question answering.
Fine-Tuning BERT
After pre-training, BERT can be fine-tuned on specific tasks with additional layers added for task-specific outputs. This process involves training the model on labeled data for the desired task, allowing it to adapt its learned representations to the particular requirements of the task.
Conclusion
Transformers have transformed the landscape of NLP with their innovative use of self-attention and parallel processing capabilities. By addressing the limitations of RNNs, transformers enable more efficient and scalable models. From the initial "Attention Is All You Need" paper to powerful models like BERT, the transformer architecture continues to drive advancements in understanding and generating human language.
Whether you're developing machine translation systems, text summarization tools, or other NLP applications, understanding the workings of transformers and their components will be invaluable in leveraging their full potential.
Resources:
https://jalammar.github.io/illustrated-transformer/
Disclaimer
The images used in this blog are sourced from various online resources. For specific image credits and sources, please refer to the respective links provided below each image. If you are the owner of any image and have any concerns regarding its use, please contact us, and we will address the issue promptly.
Subscribe to my newsletter
Read articles from Ishika Ishani directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ishika Ishani
Ishika Ishani
I am a versatile developer skilled in web development and data science. My expertise includes HTML, CSS, JavaScript, TypeScript, React, Python, Django, Machine Learning, and Data Analysis. I am currently expanding my knowledge in Java and its applications in software development and data science. My diverse skill set enables me to create dynamic web applications and extract meaningful insights from data, driving innovative solutions.