Kubeflow: Automating ML Workflows on Kubernetes
 Code Time
Code Time
Introduction
Kubernetes has proven to be the game changer for automating and managing deployments. Complex distributed workloads are now deployed and orchestrated seamlessly using Kubernetes. With applications and workloads evolving with the rise of AI, the current digital landscape is leaning towards and gambling heavily on the same (artificial intelligence).
Managing distributed applications with AI and ML integrations is getting unimaginably complex. New tools have emerged to solve the pain points, but they often lack the capabilities to blend and excel with the Kubernetes ecosystem. However, now Kubeflow has risen to bridge the gaps and help overcome challenges with ML workflow deployments in Kubernetes. With Kubeflow, ML workflow can be deployed for portability and scalability.
Kubeflow and Its Significance
Kubeflow is a Kubernetes ecosystem that offers a suite of open-source solutions to address the most challenging ML problems at scale in every stage of the ML lifecycle. Irrespective of role and expertise, Kubeflow provides a set of modular and scalable tools to tackle development and deployment issues with scalable solutions to productionize ML applications.
Kubeflow exposes components that cater to different use cases. These components can be configured on Kubernetes standalone clusters or the Kubeflow platform. They help with the most important ML functionalities, such as model training, serving, versioning, and more. Since Kubeflow is built with Kubernetes in mind, challenging ML issues can be solved easily by applying Kubernetes troubleshooting.
Kubeflow Components
Kubernetes operates at a control plane where all the compute and network instances co-exist. For the control plane to interoperate with the machine learning domain, Kubernetes requires a set of tools and services. Kubeflow bridges the gap using components, a set of logical offerings that shape Kubeflow. From training ML models to registering them with an automated pipeline feature that connects all the dependencies with docker while delivering a robust framework is necessary. Kubeflow delivers everything essential to have the job done.
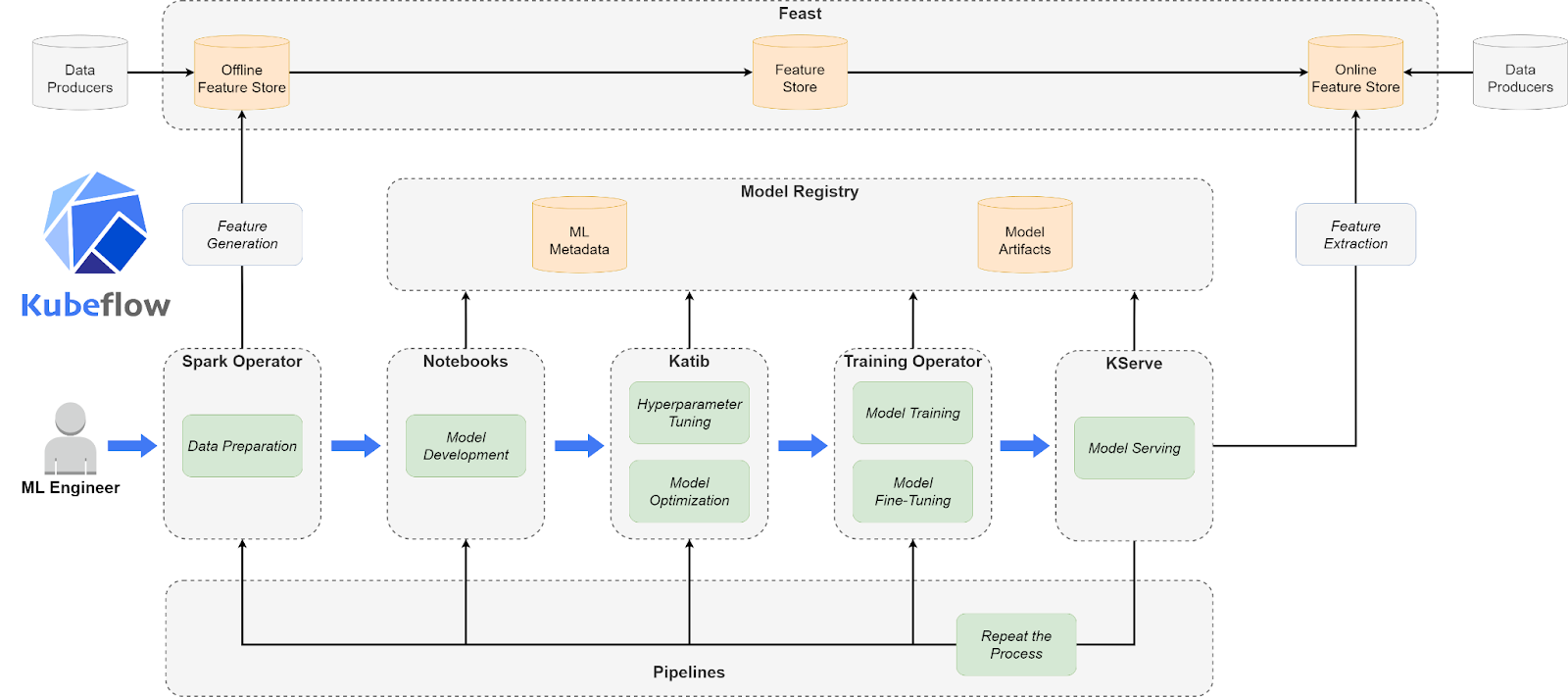
Kubeflow offers five main components that help developers thrive with distributed machine learning:
Kubeflow notebooks to develop and structure ML code.
A model registry to save the final inference model with hyperparameters to a registry.
Katib to apply AutoML features.
Training operator to fine-tune framework agnostic ML models for distributed training.
Kubeflow pipelines to build and deploy portable and cable ML workflows using docker containers.
ML Lifecycle Using Kubeflow Components
Considering the training time, number of experiments, and variations required to generate a model with accurate inference, general training approaches don't suffice for the current needs. Scaling and parallelizing the machine learning lifecycle is the viable choice to get better results at pace. There is no better strategy to apply than containerizing, distributing, and training the models at scale.
Kubernetes is the market leader in orchestration, and docker helps containerize the builds. The unification and Kubeflow technologies can operate at their best, eliminating bottlenecks that usually arise in the standard ML lifecycle at scale. Let us understand what Kubeflow components deliver and where they can be applied in the ML lifecycle.
Training at Scale
The Kubernetes stack is all about distribution and orchestration. When multiple compute instances communicate, share resources, and perform operations asynchronously, a perfect synergy is created. End-to-end machine learning pipeline generation can be accomplished swiftly with Kubeflow. All stages of the pipeline can be structured, streamlined, and orchestrated seamlessly.
All the stages of the ML lifecycle can be streamlined and distributed at scale to achieve exceptional performance and promising results. Distributed training using multiple nodes can help handle large volumes of data parallelly and generate complex models with low latency and improved inference.
Optimizations and Hyperparameters Tuning
Katib is the extensible and portable Kubeflow component that handles hyperparameter tuning and optimizations. With Katib, the semantic search for promising hyperparameters can be easily discovered and logged in the registry. Katib is framework agnostic, which means Katib's capabilities can be applied to any deep learning or AI framework.
The hyperfocus of Katibs existence is to enable AutoML capabilities in distributed environments. Early stopping and neural architecture search can be easily achieved using Katib. It has a vast array of performant optimization algorithms, along with multi-node and multi-GPU support.
Experiment Tracking
Kubeflow offers a centralized dashboard as one of its components. The dashboard logs model behavior, interactions, and metrics concerning different experiments. This unified dashboard allows tracking and managing ML experiments to analyze and improve configurations and data snapshots. The best part is that the dashboard can be customized, along with multi-profile and namespace support for user isolation as a security. Additionally, third-party application links can be added to the dashboard for reference.
Model Registry
The most crucial step in the ML lifecycle is to log the final output (model) for reuse or fine-tuning. Having a centralized registry helps automate model performance analysis, retraining, and automation using MLOps practices. Dev teams and stakeholders can access the most accurate model and apply status flags with enough evidence from the registry dashboard. By referring to the status flags, deployments can be initiated for the best-performing model in the registry.
The main advantage of a model registry is that teams can log and track the lineage of data and source code. This offers insights such as changing which functionality, parameters, or data points are leading to better inference. Using the model registry with Katib can help improve the base model by applying varying weights, hyperparameters, and other optimizations as part of fine-tuning. All of this can be streamlined and automated by unifying Kubeflow components.
Deployment and Serving
Machine learning models that are developed, optimized, and fine-tuned will deliver value when deployed for use. When dealing with distributed development and deployment, Kubeflow has a component up its sleeves to help address the scalability challenge. KFServing is a Kubeflow component that exists to help serve machine learning models. This component is responsible for deploying trained models for real-time inference with framework-agnostic capabilities.
When combined with Kubernetes, autoscaling to scale model service pods can easily be achieved to handle incoming requests. Multi-model serving from a single inference service can be attained for resource optimization with reduced I/O overhead. Model versioning and monitoring can be integrated with support for many storage backends and DevOps toolkits.
Conclusion
The pace at which generative AI is rising and keeping up with the trends requires comprehensive and advanced offerings. Modern requirements demand both speed and performance. Distributed and parallel processing is the way forward to achieve high-performance, scalable outcomes. Kubeflow is the rising star in the MLOps landscape, which can help achieve extreme results with the goodness of the Kubernetes ecosystem. Kubeflow and its components are key factors that can help build, fine-tune, and deploy machine learning models at scale.
Subscribe to my newsletter
Read articles from Code Time directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by