Multimodality Has Arrived: A Game-Changing Breakthrough!
 Pablo Salvador Lopez
Pablo Salvador Lopez
Throughout my tenure in the AI and ML landscape, there have been only a handful of moments when technology truly left me in awe. The emergence of generative multimodal models stands out, dazzling with its limitless potential and possible applicability. Stick around, especially visionary business leaders and my fellow developers; I promise, the content will unlock groundbreaking ideas.

Understanding multimodality
Our minds effortlessly combine complex information from various sources, deepening our interaction with the world. Through sight, conversation, listening, and reading, we absorb and synthesize knowledge. Multimodality, in essence, strives to emulate this sophisticated cognitive capacity. It aims to equip artificial intelligence with the ability to decipher and assimilate complex data from diverse sources, thereby refining the AI’s comprehension and its capacity to interact within our world just as we do.
Multimodality helps AI to pick up on the same clues we do, to understand our world in a richer, more connected way.
Think of multimodality like getting the whole story when someone’s talking to you. It’s not all about the words but about the context. That’s what these multimodal models are learning to do as well. They’re not just reading text; they’re looking at pictures, understanding emojis, and even thinking about the timing of a message. This helps the AI get the full picture, like figuring out if someone is sharing happy news, feeling sad, or talking about a new gadget. It’s all about teaching software systems to get the message the way we do.
Discover the ‘How’: GPT-4 Turbo with Vision.
GPT-4 Turbo with Vision, like a versatile digital mind, comprehends the world in multiple dimensions.

At its core, GPT-4 Turbo with Vision is built on a large multimodal model (LMM) foundation, which allows it to process both text and images. It uses Reinforcement Learning from Human Feedback (RLHF) to refine its understanding. This means that it learns from interactions and feedback in a way that mimics how humans improve their skills through practice and guidance.
This models has been trained on diverse and very large datasets comprising images and text, enabling it to recognize patterns and make connections between visual elements and their associated descriptions. When it analyzes an image, it doesn’t just see pixels; it identifies objects, senses the mood, and contextualizes what it ‘sees’ with what it ‘knows’ from its training.
For example, when GPT-4 Turbo with Vision is presented with an image of a casual café table setting alongside a text prompt, its analysis extends beyond mere object recognition. The model doesn’t just identify the beverages on the table — it interprets the subtle cues that speak to the setting’s atmosphere. It would note the casual placement of the drinks, the type of table, and the background elements that suggest a relaxed café environment.

Context is the key— GPT-4 Turbo with Vision doesn’t merely see; it interprets. Gazing at the plastic cup, it would not only discern the contents as a beverage but might also deduce the flavor — strawberry, suggested by the hue and texture. As for the ceramic cup, the model notices the wisps of steam, suggesting a steaming hot beverage within, and deduce it could be coffee or tea. Beyond that, it would analyze the ambient light and subtle environmental cues to speculate on the time of day — be it a mid-morning respite or an afternoon refreshment. This model goes a step further, using visual indicators to anticipate subsequent activities in the scene — will the cup be picked up for a sip, or will it remain untouched as a conversation unfolds? Providing a dynamic understanding that enriches the systems perception of sequence and time.
Unleashing a New Realm of Possibilities
GPT-4 Turbo with Vision can accept various types of input, including:
A single image with text, with the option to process just the image.
Multiple images woven with text, also allowing for multiple images without accompanying text.
Therefore multimodality will transform machine learning by bringing in visual context, which makes previous complex challenges MUCH simpler and opens up a whole new world of possibilities. For example:
Imagine a real estate website providing rich, narrative descriptions of properties just from uploaded photos, enhancing listings with vivid details that capture the nuances of each home.
Envision financial analysts converting intricate market trend graphs directly into predictive algorithms, streamlining their workflow.
Picture educational platforms offering comprehensive summaries of scientific diagrams, making complex information accessible to students at a glance.
Think of e-commerce platforms using visual pointers to guide users interactively through product features, revolutionizing online shopping experiences.
Consider quality control processes where AI detects minute defects in manufacturing with precision, reducing errors and improving safety.
In the context of video indexing, imagine GPT-4 Turbo with Vision swiftly analyzing hours of traffic footage. It detects a specific incident, assesses the vehicles’ conditions, and provides a detailed report on the damage sustained during a car accident. This level of analysis could revolutionize insurance claim processes, allowing for rapid, accurate assessments that facilitate faster resolutions for all parties involved.
You might think, “Hey, I’ve done this before with deep learning (computer vision),” and that was my initial thought as well. However, after optimizing OCR issues and understanding how multimodality enables the integration of text prompts with contextual image recognition, I’ve found it to be distinctively different and significantly more effective.
Enhancing OCR Performance through Multimodality
At first, I always saw OCR as just another item on the to-do list for a complex end-to-end software product. But let’s be honest: diving into computer vision is like entering a maze — challenging at every turn. It’s all about spotting things and drawing boxes around them, with a big focus on pulling out information. However, stepping into the world of Context Engineering has flipped the script for me. OCR isn’t just a task anymore; it has become this fascinating challenge that is the key to develop successful RAG architectures.
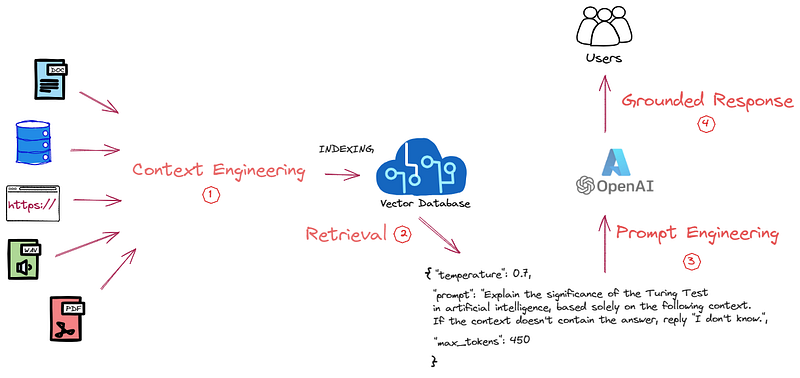
The Context Engineering Challenge
The Retrieval-Augmented Generation (RAG) architecture has unveiled a complex and fascinating landscape that necessitates the processing and engineering of vast amounts of unstructured data for integration into Vector Databases. In the industry’s prevalent RAG architecture, often referred to as “chat with your own data,” many companies frequently encounter challenges concerning “the retrieved data.” The Large Language Models (LLMs), which serve as the serving layer of the RAG systems, excel at summarizing and crafting answers when provided with the correct context. Therefore, you might consider this a “Search” problem, but services like Azure AI Search deliver state-of-the-art (SOTA) scores on retrieval. So, I don’t believe so — I’d like to take a step back, one step down the pipeline — where the majority of issues originate from “Context Engineering.” This step is crucial because customizing our data ensures it is retrieved in the most optimized manner, allowing the LLM to accurately comprehend the context.
This data may come from a variety of sources, including audio clips, PowerPoint presentations, websites, and particularly complex PDFs, making the extraction of information a daunting task.

Enhancing Context Extraction
As you can observe, loading, chunking, OCR (depending on the complexity of the data), and vectorization are key components of the context engineering pipeline. I regard this as a specialized subfield of data engineering, dedicated to extracting valuable insights from unstructured data. This step is crucial, and it’s important to note that even the most powerful LLMs cannot guarantee high-quality output if the context is provided in the wrong format, time, or context.
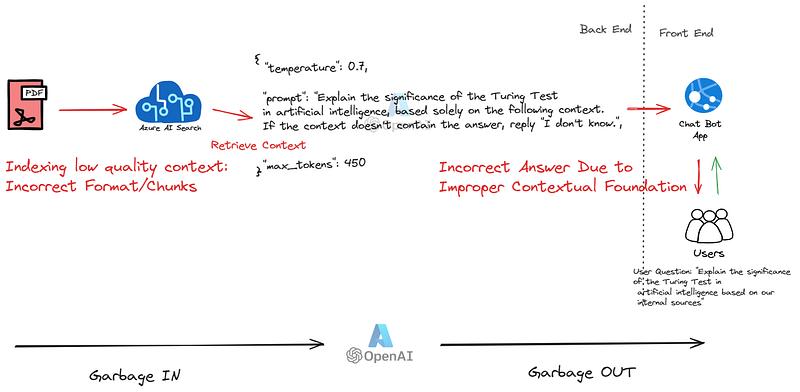
As my goal here is multimodality, I’ll focus on the OCR aspects. I would love to discuss Chunking and vectorization of data, but that would require a whole new article. Let’s concentrate on how to process very complex PDFs to improve our “Context Engineering” and enrich our own data in a way that will make it easier for our search systems to retrieve, and for our LLM to comprehend.
Let’s consider a scenario where an engineering field team has a question about a specific arrangement documented in a manual. Imagine the documentation exists within a 100+ page manual. It’s not straightforward to comprehend or even think about searching and navigating such a vast document. Traditional OCR models based on deep learning could extract the text, but the complexity of these documents often includes detailed diagrams or complex layouts that go beyond mere text extraction.
After spending numerous days constructing my logic on top of a the OCR output models to make sense of the data, I encountered significant complexity and never reached an acceptable level of satisfaction. Therefore, I decided to embrace multimodality with GPT-4 Turbo with Vision. I crafted a prompt and attached the page as an image, aiming to translate the knowledge into a format that would firstly enhance the indexing of my data into my vector database, and secondly result in better content retrieval.
🚀 Code implementation is available! Check it out here
Prompt:
sys_message = "You are an AI assistant capable of processing and summarizing complex documents with diagrams and tables."
user_prompt = """
Please analyze this document and provide the information in the following format:
1. Summary: Provide a concise summary of the document, focusing on the main points and overall context.
2. Content: Your task is to extract all information from the document in a detailed and granular manner. Pay special attention to tables and diagrams. Ensure that no information is omitted. Avoid summarizing; instead, be explicit with all the details and cells. Take your time, as the purpose is to thoroughly record all the information from the document.
3. Category: List key categories or keywords, with a focus on main products or concepts mentioned in the document. Categories should be abstracted and listed, separated by commas, with a maximum of 10 words.
The purpose is to enable another system to read and understand this information in detail, to facilitate answering precise questions based on the document's context.
Please return the information in the following format:
#summary
<summary text>
#content
<content text>
#category
[<category 1>, <category 2>, <category 3>, ...]
"""
Result:
#summary
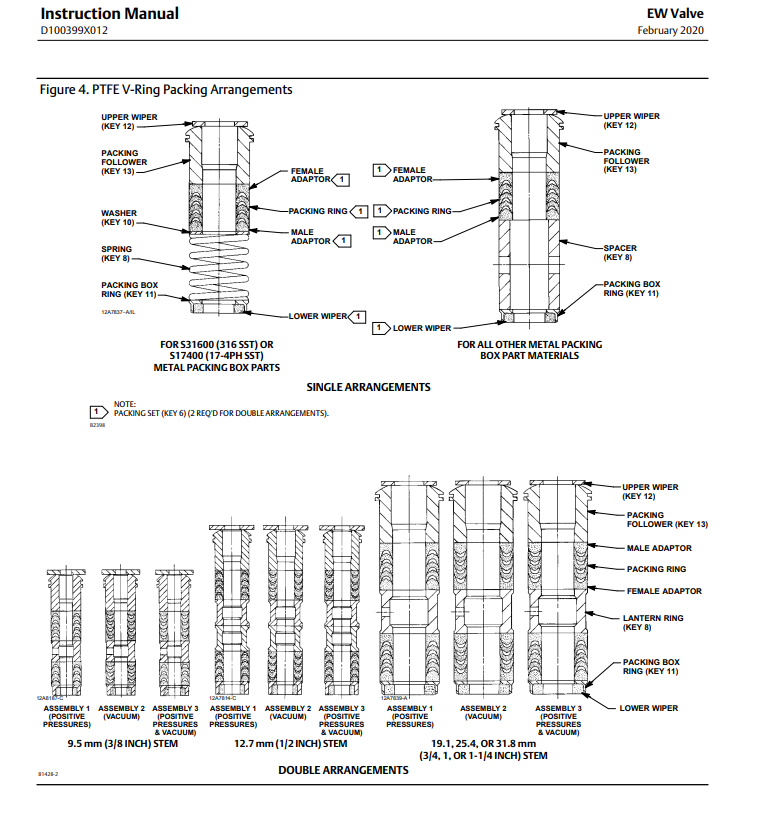
The document is an instruction manual for EW Valve, specifically detailing the PTFE V-Ring Packing Arrangements. It includes diagrams showing the configuration of components for single and double arrangements based on various stem sizes and pressure conditions. The manual identifies each part by a key number and notes the requirement for a packing set for double arrangements.
#content
- The document title is "Instruction Manual" for the "EW Valve," with a reference number "D100399X012," dated February 2020.
- Figure 4 illustrates the "PTFE V-Ring Packing Arrangements."
- The diagram shows the following components for a single arrangement:
- Upper Wiper (Key 12)
- Packing Follower (Key 13)
- Female Adaptor
- Packing Ring
- Male Adaptor
- Washer (Key 10)
- Spring (Key 8)
- Packing Box Ring (Key 11)
- Lower Wiper
- There is a note indicating that the Packing Set (Key 6) is required for double arrangements.
- The diagram also includes specific arrangements for different materials:
- For S31600 (316 SST) or S17400 (17-4PH SST) metal packing box parts
- For all other metal packing box part materials
- Below the single arrangement, there are three double arrangements shown for different stem sizes and conditions:
- Assembly 1 for a 9.5 mm (3/8 inch) stem under positive pressures
- Assembly 2 for a 12.7 mm (1/2 inch) stem under vacuum conditions
- Assembly 3 for 19.1, 25.4, or 31.8 mm (3/4, 1, or 1-1/4 inch) stem under positive pressures & vacuum
- Each double arrangement diagram also includes:
- Upper Wiper (Key 12)
- Packing Follower (Key 13)
- Male Adaptor
- Packing Ring
- Female Adaptor
- Lantern Ring (Key 8)
- Packing Box Ring (Key 11)
- Lower Wiper
- The diagrams for double arrangements are labeled as "Assembly 1," "Assembly 2," and "Assembly 3" with the respective conditions (Positive Pressures, Vacuum, Positive Pressures & Vacuum) indicated underneath each assembly.
#category
[Instruction Manual, EW Valve, PTFE V-Ring Packing Arrangements, Single Arrangement, Double Arrangements, Valve Components, Stem Sizes, Pressure Conditions, Keyed Parts, Diagrams]
Wow! 🤯 Just 5 minutes of playing around with prompt engineering, and I outdid 3 whole days of wrestling with OCR and cobbling together custom code to make text and images live in harmony. Who knew?
The process of indexing data has become significantly more straightforward and efficient. Now, I can precisely dictate the data’s structure and how it should be outputted, all through a simple text prompt. This newfound flexibility allows me to merge several pages at once, possibly organized by section, converting the content into text form. Most importantly, I make sure to extract this information in a way that’s contextually relevant, akin to the detailed approach a human would take, ensuring the essence, details and meaning are preserved.
How to get started
I invite you to explore my repository for a comprehensive guide on harnessing these groundbreaking OCR techniques, utilizing Azure and OpenAI’s models for secure, efficient, and innovative document processing.
Exploring OCR with Azure AI Document Intelligence (
01-ocr-document-intelligence.ipynb)Advanced OCR with GPT-4 Vision (
02-ocr-gpt4v.ipynb)Extraction of information from a wide range of invoices, significantly improving the efficiency and accuracy of processing financial documents with GPT-4 Vision (
03-ocr-invoices.ipynb)
Conclusion
Our exploration of multimodality, particularly through the lens of GPT-4 Vision, underscores a pivotal shift in how we interact with and process information. By integrating text and visual data, GPT-4 Vision not only enhances our ability to understand and contextualize content but also opens up new avenues for innovation and efficiency. This game-changing technology represents a significant leap forward, demonstrating the untapped potential of AI to mimic human-like understanding and interaction with the world around us, paving the way for advancements that were once considered beyond our reach.
Did you find it interesting? Subscribe to receive automatic alerts when I publish new articles and explore different series.
More quick how-to's in this series here: 📚🔧 Azure AI Practitioner: Tips and Hacks 💡
Explore my insights and key learnings on implementing Generative AI software systems in the world's largest enterprises. GenAI in Production 🧠
Join me to explore and analyze advancements in our industry shaping the future, from my personal corner and expertise in enterprise AI engineering. AI That Matters: My Take on New Developments 🌟
And... let's connect! We are one message away from learning from each other!
🔗 LinkedIn: Let’s get linked!
🧑🏻💻GitHub: See what I am building.
Subscribe to my newsletter
Read articles from Pablo Salvador Lopez directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pablo Salvador Lopez
Pablo Salvador Lopez
As a seasoned engineer with extensive experience in AI and machine learning, I possess a blend of skills in full-stack data science, machine learning, and software engineering, complemented by a solid foundation in mathematics. My expertise lies in designing, deploying, and monitoring GenAI & ML enterprise applications at scale, adhering to MLOps/LLMOps and best practices in software engineering. At Microsoft, as part of the AI Global Black Belt team, I empower the world's largest enterprises with cutting-edge AI and machine learning solutions. I love to write and share with the AI community in an open-source setting, believing that the best part of our work is accelerating the AI revolution and contributing to the democratization of knowledge. I'm here to contribute my two cents and share my insights on my AI journey in production environments at large scale. Thank you for reading!