Multi-Region Kubernetes Deployments With ArgoCD
 Obiajulu Ezike
Obiajulu Ezike
Deploying applications on Kubernetes is hard. Doing this continuously and efficiently is even more difficult and even more so in a multi-cluster environment spanning multiple regions. This article will provide an in-depth guide to continuously deploy applications to Kubernetes clusters across multiple environments and regions.
In a previous article, I discussed how the infrastructure of this deployment was done. Check it out if you want to follow along.
Pre-requisites
Multiple Kubernetes clusters (Setup discussed in a previous article)
Git and GitHub
Kubectl
Helm
What does it take to deploy an application on Kubernetes?
Kubernetes adopts the notion of declaring the state of the cluster as yaml files. These files are then applied to the cluster by sending them to the api-server. You need to keep a couple of things in mind while deploying applications.
Authentication & Authorization:
Of course, in any real cluster, you’ll have to think about access control because you know … security reasons. You don’t want just anyone accessing your cluster willingly. In the case of multi-cluster deployments, you have to make sure all your clusters share the same state and keep track of their access configurations. For this exercise, we have made use of AWS EKS clusters. They have a neat authentication and authorization model facilitated by IAM resources.
Dependencies:
By this, I mean that certain Kubernetes resources depend on others. The state of a resource will transition to a
pendingstate orfailedstate if they are not carefully accounted for. A classic example here would be PersistentVolumeClaims (PVCs) depending on the cloud provider to provision storage volumes. Without the appropriate role mappings to grant this permission to your cluster the resources that depend on the persistent volume will malfunction at best and fail completely in worst case.Versioning and continuous deployments:
We need to be able to version our deployments. Keeping a snapshot of the previous states of the cluster enables us to roll back in cases of failures. Being able to deploy and roll back continuously and efficiently must be considered.
What is GitOps?
GitOps is the practice of versioning changes to infrastructure, managing these changes using a versioning tool like git, and having it be the source of truth when evaluating the state of the infrastructure. Ideally, nothing should exist in the infrastructure that is not first defined with IaC and versioned by git or some other version control mechanism.
Applying this idea to Kubernetes, we can store and version our cluster manifests in git and somehow continuously run checks to ensure that the state of the cluster is the same as that defined in git (Diff reconciliation using a pull or push-based model). This is GitOps.
For the Kubernetes ecosystem, there are 2 major tools used to achieve this and enhance continuous deployment with the git source as a reference for the desired state of the cluster. They are fluxCD and argoCD. In this exercise, we will be exploring ArgoCD as our GitOps tool for Kubernetes continuous deployments.
ArgoCD
ArgoCD is a graduated CNCF project which implements a pull-based GitOps model that provides a simple interface for constructing continuous deployment mechanisms on Kubernetes clusters. It provides a lot of cool functionalities like multi-cluster support, interfacing with Kustomize for applying micro-changes between clusters like region or environment-specific information, and even provisioning preview deployments.
How does it work?
ArgoCD works by watching a git repository or some other equivalent source and applying configurations found there to a cluster. In short, to function, ArgoCD needs at least one source and one cluster.
It polls the git repository constantly (every 3 minutes by default) to check for new changes and syncs the state of the cluster to match the changes in the repo. It comes with a lot of configurations which we will explore in the course of this article.
Project Description
For this article, we will be demonstrating how to deploy a 2-tier application across multiple clusters the gitops way. We’ll also look into how to handle secrets in this pipeline.
I have chosen an old project of mine for this deployment. It consists of a WebUI and corresponding API for running a genetic algorithm I developed. You can find the API here and the WebUI here.

Architecture
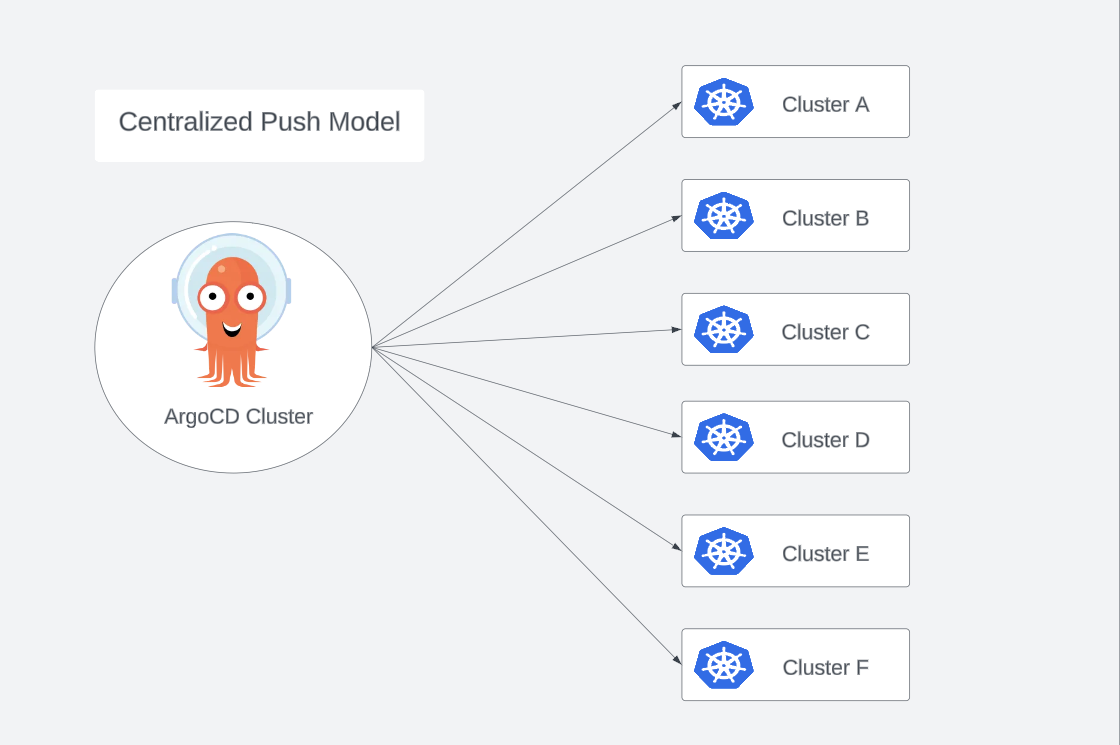
We shall be adopting a centralized push model for our architecture. Where ArgoCD runs on its own cluster and pushes changes to all other clusters when changes are made in the git repository it’s watching. The advantage of this approach is that the clusters need not be aware of argocd at all. It is also easier to monitor the state of all the clusters using just one instance of argocd as our control plane of sorts.
Implementation
The repository containing the complete project can be found here.
The first thing we want to do is define our directory structure. Getting this right is important for maintenance and utilizing some ArgoCD features.
manifests/
├── argocd/
├── base/
├── helm/
│ ├── dev
│ └── prod
├── overlays/
│ ├── dev
│ │ ├── us-east-2/
│ │ │ ├── config.json
│ │ │ ├── kustomization.yaml
│ │ └── us-west-2/
│ │ ├── config.json
│ │ ├── kustomization.yaml
│ └── prod/
└── README.md
As can be seen in the above structure, we have an argocd folder to house argocd manifest files because get this, ArgoCD can also manage itself in addition to the other cluster. We won’t be doing that in this article though. It’s just something to keep in mind.
We then have our base configuration for our application. Here, we define the deployment and service specifications for the API and WebUI. They are identified and extended in the overlay directory using Kustomize. Here we can do things like pass in region or environment-specific variables or configurations (like resource requirements, image tags, etc.).
We also have a helm folder to keep track of the helm values files for charts we will be using.
That’s pretty much it. The prod directories can be populated by the old copy-pasta trick.
Deployments and services
This bit is quite straightforward. Our deployment specification creates one replica of our applications and allocates some memory and CPU for the containers. We are also adding docker login credentials using the spec.template.spec.imagePullSecrets field. The WebUI and API share similar configurations
apiVersion: apps/v1
kind: Deployment
metadata:
name: gen-algo-webui
labels:
app: gen-algo-webui
spec:
replicas: 1
selector:
matchLabels:
app: gen-algo-webui
template:
metadata:
labels:
app: gen-algo-webui
spec:
containers:
- name: frontend
image: demarauder/gen-algo-webui:latest-main
imagePullPolicy: Always
ports:
- containerPort: 8000
resources:
limits:
memory: "128Mi" # 2^20 bytes
cpu: "500m" # 0.5 cpu cores
imagePullSecrets:
- name: docker-regcred # created manually
Our service config just exposes the deployment with a clusterIP.
apiVersion: v1
kind: Service
metadata:
name: gen-algo-webui
labels:
app: gen-algo-webui
spec:
type: ClusterIP
ports:
- port: 3000
targetPort: 3000
selector:
app: gen-algo-webui
ArgoCD setup
For ArgoCD’s configuration, we are using the official documentation to install it.
kubectl create namespace argocd
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
# Get login password
kubectl exec -it argocd-server – argocd admin initial-password -n argocd
# setup clusters
Kubectl exec -it argocd-server – argocd login <argocd-server-endpoint> -n argocd
# Add cluster to your kubeconfig and get the context-name as the <cluster-name>
Kubectl exec -it argocd-server – argocd cluster add <cluster-name> --server <argocd-server-endpoint>
The above commands install argocd, get the password for the default admin user created on installation. You can then log in via console or web UI. Yes, ArgoCD has a web UI … awesome stuff.
The last command is to register a Kubernetes cluster on argocd so we can select it as a destination. You’ll need to expose the argocd-server pod installed by the previous command as a service and use the correct port to get the server endpoint.
Kubectl port-forward argocd-server 8080:8080
# The server endpoint thus becomes localhost:8080
Once you have your GitOps cluster (a cluster for argocd - it can be small since it’ll only run ArgoCD) setup, you can connect to it and run the above commands.
ArgoCD Applications & ApplicationSets
ArgoCD defines custom resources one of which is an Application. This represents a package to be deployed on Kubernetes and managed by ArgoCD. It consists of a source repository and a destination cluster. This is what actually provides ArgoCD with the information it requires to do its job.
Application sets are another class of custom resource definitions that allows you to group a lot of application deployments and manage them using one file. Instead of multiple application configurations, you’d have one ApplicationSet and work with different types of generators to dynamically create the Applications and pass custom variables when required. You can think of the ApplicationSet to be to an Application what a ReplicaSet is to a pod (Obviously it’s not a direct match but you get the idea).
To learn more about configuring applications and application sets, please visit their official docs.
In this project, we make use of ApplicationSets because they are the perfect tool for multi-cluster administration. ApplicationSets make use of generators to define the strategy for defining the Applications from the ApplicationSets. There are a bunch of them, you can read about them here
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: gen-algo
namespace: argocd
spec:
goTemplate: true
goTemplateOptions: ["missingkey=error"]
generators:
- git:
repoURL: https://github.com/de-marauder/multi-region-eks.git
revision: HEAD
files:
- path: "manifests/overlays/**/config.json"
values:
clusterName: "{{ .cluster.name }}"
server: "{{ .cluster.server }}"
region: "{{ .cluster.region }}"
environment: "{{ index .path.segments 2 }}"
template:
metadata:
name: gen-algo-{{ .values.environment }}-{{ .values.region }}
namespace: argocd
spec:
project: default
source:
repoURL: "https://github.com/de-marauder/multi-region-eks"
targetRevision: HEAD
path: "{{ .path.path }}"
destination:
server: "{{ .values.server}}"
namespace: "gen-algo-{{ .values.environment }}-{{ .values.region }}"
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=true
As can be seen above, we make use of the git generator. It allows us to specify how many Applications we’d like to create by using configurations based on a git repository. The structure of the repo should be such that every cluster (or application) is represented by a directory with a config file. This file will be used to inject Application specific configurations. In our case, we had something like this,
├── overlays
│ ├── dev
│ │ ├── us-east-2
│ │ │ ├── api-deployment-patch.yaml
│ │ │ ├── config.json
│ │ │ ├── kustomization.yaml
│ │ │ └── webui-deployment-patch.yaml
The config file was located in every region we wanted to deploy a cluster in. It contained the cluster name, region, and API-server endpoint,
{
"cluster": {
"name": "cluster-name or arn", // obtain from your kubeconfig when you setup access to your cluster.
"region": "us-east-2",
"server": "<cluster-endpoint>"
}
}
Once this is done, ArgoCD will automatically pull the paths you have specified in your ApplicationSets and create the necessary Applications.
ArgoCD UI

To view your changes happening visually, ArgoCD provides an intuitive web interface to view and manage what’s happening. If you are on a local setup using something like Minikube, you’ll be able to access this via localhost on port 8080. However, if you’re in production environments, you’ll need an ingress to expose this UI. An ingress gives you an application load balancer (ALB) that can route traffic into your cluster (using AWS EKS as a reference here - you can port to your cloud of choice). Preferably you’d also want to get a domain name and SSL certificate for it (the argocd service). ArgoCD blocks insecure access by default. It does this by always trying to redirect to https. This will prevent an HTTP client from loading the page by making an insecure HTTP request. You’ll have to disable this manually by editing the ArgoCD deployment manifest. It should include the following in the container specifications,
spec:
containers:
- command:
- argocd-server
- --insecure
To apply ingress, you’ll need to set up an ingress controller and apply an ingress manifest. The latter won’t work without the former. You can install an nginx ingress controller using the commands below
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.1.1/deploy/static/provider/cloud/deploy.yaml
# or with helm
kubectl create namespace ingress-nginx
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
helm install ingress-nginx ingress-nginx/ingress-nginx \
--namespace ingress \
--set controller.ingressClassResource.name=nginx
Next, we apply the ingress definitions for the ArgoCD service.
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: argocd-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.ingress.kubernetes.io/ssl-redirect: "false"
nginx.ingress.kubernetes.io/force-ssl-redirect: "false"
namespace: argocd
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: argocd-server
port:
number: 8080
Our setup uses insecure mode so we instruct the ingress controller not to enforce SSL redirects. The rule tells the controller to route all requests on the root path of the Ingress ALB to the argocd-server service.
After all this, you should be able to access the ArgoCD UI via the ALB’s endpoint. You can go ahead and create an alias record for this endpoint with your DNS provider if you want public access via a custom domain name.
Passing Secrets

We already established that everything must be in Git if we want to practice GitOps. However, we have certain types of parameters that should not be stored in repositories. These secrets should be kept secured and preferably fed to the applications requiring them at runtime.
To do this we must consider various secret manager tools from cloud-based solutions such as AWS SSM or Azure key vault to self-managed solutions such as Hashicorp vault. Kubernetes has its native secret resource. However, it provides little security as the information in it is only base64 encoded.
In this project, we make use of the Hashicorp vault to set up a secure store for our application secrets.
Vault & Consul
First, we need to install a vault. I find the helm chart to be the most convenient way to do this. Vault requires a storage backend to persist your data. By default, it’ll write to the local disk but you can configure a custom backend using tools like Raft or Consul. You could also tell it to write to a remote disk in the cloud for fault tolerance, you know … replication and all that good stuff.
Consul is being used in this project as a storage backend. It is also built and maintained by Hashicorp. Before we install Consul, if you’re running on the cloud, you’ll need to make sure your cluster has permission to provision a cloud storage backend. For example, Consul detects when it’s deployed on EKS and tries to create an EBS backend by default. Your installation will remain in a pending state without the permission to perform this operation. Since Consul will be a dependency of Vault and Vault will be a dependency of our application, if the consul remains in a pending state nothing will work. The setup for this permission is included in the infrastructure setup discussed in the previous article.
Once Consul is up, you can configure Vault and populate it with your secret data. This can be automated using tools like Ansible. To set consul and vault here’s a checklist:
#######################################################
## SETUP CONSUL ##
#######################################################
# write values file to configure helm chart
cat <<EOF >manifests/helm-consul-values.yml
global:
datacenter: gen-algo
client:
enabled: true
server:
replicas: 1
bootstrapExpect: 1
disruptionBudget:
maxUnavailable: 0
EOF
# install helm chart
helm repo add hashicorp https://helm.releases.hashicorp.com
helm repo update
helm install consul hashicorp/consul --values manifests/helm-consul-values.yml
#######################################################
## SETUP SECRETS ON VAULT ##
#######################################################
# Install Vault
cat <<EOF >manifests/helm-vault-values.yml
server:
affinity: ""
ha:
enabled: true
EOF
helm repo add hashicorp https://helm.releases.hashicorp.com
helm repo update
helm install vault hashicorp/vault --values manifests/helm-vault-values.yml
## Unseal and initialize vault
kubectl exec vault-0 -- vault operator init -key-shares=1 -key-threshold=1 -format=json > cluster-keys.json
# Get unseal key
cat cluster-keys.json | jq -r ".unseal_keys_b64[]"
VAULT_UNSEAL_KEY=$(cat cluster-keys.json | jq -r ".unseal_keys_b64[]")
# unseal all vault pods
kubectl exec vault-0 -- vault operator unseal $VAULT_UNSEAL_KEY
kubectl exec vault-1 -- vault operator unseal $VAULT_UNSEAL_KEY
kubectl exec vault-2 -- vault operator unseal $VAULT_UNSEAL_KEY
## Set Secrets
# login
ROOT_TOKEN=$(cat cluster-keys.json | jq -r ".root_token")
kubectl exec --stdin=true --tty=true vault-0 -- /bin/sh
vault login # use ROOT_TOKEN
# Enable KV secrets engine
vault secrets enable -path=secret kv-v2
# Store api secrets
vault kv put secret/api/env \
DB_URL=<secret> \
JWT_SECRET=<secret>
# Store webui secrets
vault kv put secret/webui/env-local \
NEXT_PUBLIC_API_URL=<secret> \
NEXT_PUBLIC_FCM_API_KEY=<secret>
# Enable Kubernetes auth
vault auth enable kubernetes
vault write auth/kubernetes/config \
kubernetes_host="https://$KUBERNETES_PORT_443_TCP_ADDR:443"
# Create api policy
vault policy write gen-algo-api-policy - <<EOF
path "secret/data/api/env" {
capabilities = ["read"]
}
EOF
# Create webui policy
vault policy write gen-algo-webui-policy - <<EOF
path "secret/data/webui/env-local" {
capabilities = ["read"]
}
EOF
# Create api role mapping policies to service accounts and namespaces
vault write auth/kubernetes/role/gen-algo-api-role \
bound_service_account_names=gen-algo-sa \
bound_service_account_namespaces=gen-algo \
policies=gen-algo-api-policy \
ttl=24h
# Create webui role mapping policies to service accounts and namespaces
vault write auth/kubernetes/role/gen-algo-webui-role \
bound_service_account_names=gen-algo-sa \
bound_service_account_namespaces=gen-algo \
policies=gen-algo-webui-policy \
ttl=24h
We’ll run Consul with just one replica and run Vault in high availability mode (3 replicas). Vault works by using a decentralized lock to ensure the integrity of your data. The idea is that you can seal the vault and the seal has multiple keys (the number is configurable). To unseal the vault you would need to pass a certain number of the keys. In practice, these keys can be shared among different personnel or secure servers and when access to the vault is required all the keys must assemble or give consent. Think of these keys as nuclear warhead launch codes. No single person ever holds all codes required to release a nuclear warhead.
For this reason, the first thing we have to do is initialize and unseal Vault using the keys obtained after initialization. Then we have to log in to every server using the login token and create the paths to store our secrets as well as setup access control rules (roles and policies).
Vault offers a lot of functionality which we cannot discuss in this article. To learn more I strongly suggest checking out their tutorials.
Deployments & Vault
So we have our secrets set up. How do we tell our applications? I mean, sure … it’s a secret. But my deployments still need to know about it.
The vault helm chart comes with a controller, the “vault agent injector controller”. Its job is to read the annotations of pods and run sidecars that mount a shared volume containing the secrets requested in the pod's annotations. The pod annotations look like this,
template:
metadata:
annotations:
vault.hashicorp.com/agent-inject: "true"
vault.hashicorp.com/agent-inject-status: "update" # update secret in pods dynamically without pod restart
vault.hashicorp.com/role: "gen-algo-api-role"
vault.hashicorp.com/agent-inject-secret-env: "secret/data/api/env"
vault.hashicorp.com/agent-inject-file-env: ".env"
vault.hashicorp.com/agent-inject-template-env: |
{{- with secret "secret/api/env" -}}
DB_URL={{ .Data.data.DB_URL }}
JWT_SECRET={{ .Data.data.JWT_SECRET }}
{{- end }}
Here we first tell the controller to mark this pod as an injectable. Then we let it know to update the secrets dynamically whenever they change in vault (otherwise you’ll have to restart the pods to see the changes). We also specify the role to use to access the secrets. This works in hand with the service account used to identify the pod and needs to have been defined during the vault setup. Next is to specify the path to find the secret in vault and then the file path to write them to in the shared volume. The final annotation uses a template to build out a file. In this case, it’s the .env file for our application.
This file is mounted to the volume at /vault/secrets/.env so we have to move it to where our application expects it to be before running our app (using a symbolic link will allow the changes to be reflected immediately since the new file is just a pointer to the original).
spec:
serviceAccountName: gen-algo-sa
containers:
- name: backend
image: demarauder/gen-algo-api:latest-main
imagePullPolicy: Always
command:
- /bin/sh
- -c
- |
ln -s /vault/secrets/.env /app/.env
node /app/build/server.js
The same ideas apply to the webui also. To access our running services, we’ll also need ingresses just like with the GitOps cluster. This is because our infrastructure is private (NodePorts are not accessible to the public).
To make this simpler to deploy and maintain, we fall back to our old friend ArgoCD and add vault, consul, and the ingress controllers as ApplicationSets to run on all clusters. Incase you were wondering, yes, ArgoCD allows you to specify a helm chart as a source of an Application. All you have to do is point to the helm repo and set the chart name and version.
spec:
template:
spec:
project: default
source:
- repoURL: "https://helm.releases.hashicorp.com"
chart: vault
targetRevision: 0.28.0
helm:
valueFiles:
- $values/manifests/helm/{{ .values.environment }}/vault-values.yaml
Just like that, we’ve successfully deployed our application to multiple clusters in multiple regions.
Conclusion
In this article, we explored the requirements to deploy an application to multi-region clusters using a GitOps approach. We talked about what GitOps is and how it’s important for continuous delivery. We also showed how ArgoCD can be set up to manage multiple cluster applications across regions. Lastly, we discussed how to handle secrets in an ArgoCD pipeline by using Hashicorp Vault and Consul.
This was an interesting project for me and I encourage everyone to check out the documentation of these projects.
Till we meet again.
Subscribe to my newsletter
Read articles from Obiajulu Ezike directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Obiajulu Ezike
Obiajulu Ezike
Software Engineer || Part-time Otaku I like finding simple ways to explain complicated concepts