Consistent Hashing
 Parvesh Saini
Parvesh Saini

Introduction
Ever wondered how big companies manage to keep their data organized across thousands of servers? To ensure predictable performance in such systems, it’s crucial to distribute data evenly across these servers. Think of it like trying to split a pizza evenly among your friends, except the friends are always changing.
In this blog, let me break down consistent hashing in simple terms. We'll look at how it works and why it’s essential for managing data in distributed systems. But before that, let's explore the naive way which uses Simple Hashing.
Basics of Simple Hashing
In simple hashing, we use a hash function, like MD5 or MurmurHash, to map each object's key to a range of numerical values. A good hash function distributes these values evenly across the entire range. Next, we perform a modulo operation on the hash value with the number of servers, which determines the server to which the object belongs. As long as the number of servers remains constant, each object key will always map to the same server.
However, issues arise when the cluster size changes. Adding or removing servers disrupts the balance. For example, if one server goes down and we’re left with three servers, the modulo operation now applies to a different number, leading to a significant redistribution of keys. This not only affects the keys originally stored on the now-offline server but also causes a storm of data movement across the cluster, which is highly inefficient.
Consistent Hashing for the win!
Consistent hashing is a technique designed to address this issue by ensuring that most objects stay assigned to the same server even as the number of servers changes. To implement consistent hashing, each server gets a range of hash values. Each key is hashed and assigned to the server with the closest matching hash value range. For example, if three servers have hash value ranges of 0-99, 100-199, and 200-299, and a key has a hash value of 150, it goes to the second server.
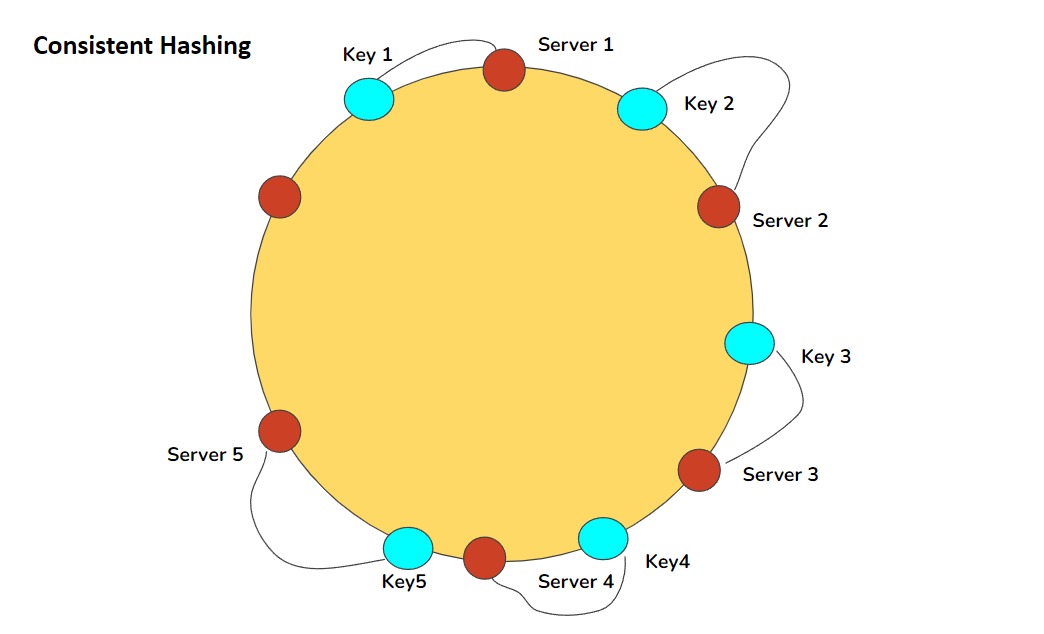
When a server is added or removed, only a portion of the keys need to be rehashed and moved. This is because the hash value ranges of the other servers shift slightly to accommodate the change, moving only the keys in the overlapping range. This keeps the distribution of keys consistent, even as servers come and go. This is handy for dynamic systems where keys and servers change frequently, ensuring even distribution without the need to rebuild the entire hash table every time a server is added or removed.
Understanding Virtual Nodes
The problem with consistent hashing is that it can lead to an uneven distribution of keys across servers. If servers are assigned large, unequal segments of the hash ring, some servers may become overloaded while others remain underutilized.
Virtual nodes solve this issue by representing each physical server with multiple virtual nodes on the hash ring. This approach breaks down the large segments into smaller, more evenly distributed ones, ensuring a balanced load across all servers. This finer granularity helps maintain performance and scalability, even when servers are added or removed from the cluster.
Real World Applications
Consistent hashing is widely used in various real-world systems to ensure efficient data distribution and scalability. Here are a few examples:
Distributed Storage Systems: Systems like Amazon S3 and Hadoop Distributed File System (HDFS) use consistent hashing to evenly distribute and manage large volumes of data across multiple storage nodes, ensuring balanced storage loads and efficient data retrieval.
Web Caching: Companies like Cloudflare use consistent hashing to distribute cached web content across their global network of edge servers, which improves access speed and reduces latency for users worldwide.
Microservices Architecture: Platforms such as Netflix use consistent hashing to route user requests to the appropriate service instances, ensuring that traffic is evenly distributed and minimizing the risk of overloading any single service.
Conclusion
Consistent hashing is a powerful tool for managing data in distributed systems, providing a way to handle dynamic changes in server configurations with minimal impact.
By understanding and applying consistent hashing, you can build more robust, efficient, and scalable systems. Whether you're dealing with databases, load balancers, or content delivery networks, consistent hashing ensures that your data stays evenly distributed and easily accessible, no matter how many servers you add or remove.
If you have any doubts or suggestions, feel free to ping me on LinkedIn. Your engagement is greatly appreciated. Happy coding :)
Subscribe to my newsletter
Read articles from Parvesh Saini directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Parvesh Saini
Parvesh Saini
Full Stack Developer with a knack for problem-solving and technical blogging.