Employee Promotion Prediction using Decision Tree & Ensemble Learning Algorithms
 Arpan Mahatra
Arpan Mahatra
One of the major problem any company faces is identifying the right employees for promotion. So, I looked for a human resource dataset with several input features and a boolean output feature on promotion. My final objective was to create a binary classification model by comparing decision tree & 5 ensemble learning algorithms.
I started with downloading this Kaggle dataset: https://www.kaggle.com/datasets/arashnic/hr-ana
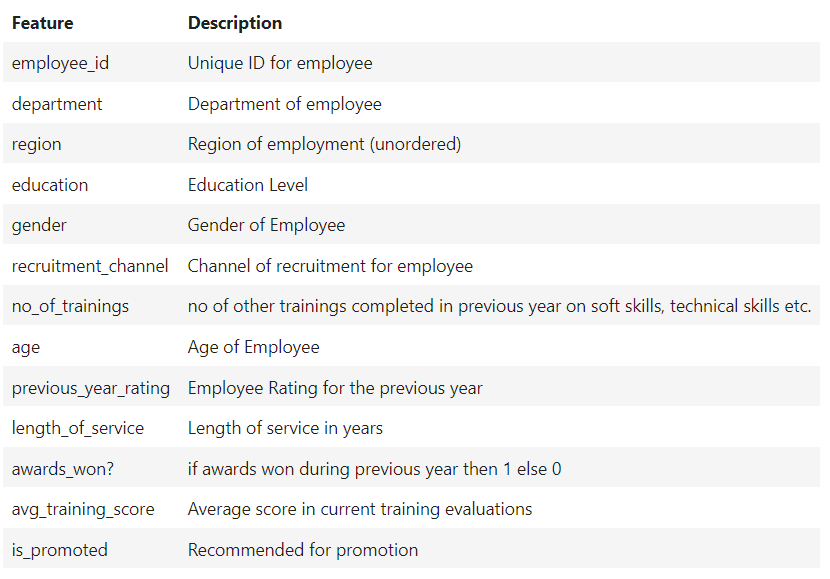
Here is the description about all features.
Then, I started coding in Jupyter notebook first by importing all the needed libraries (numpy, pandas, sklearn, matplotlib and seaborn) and loading the dataset.
Data Preprocessing
I performed general data exploration to understand null values, datatypes and statistics of features in dataset.
Then, I found out 2 features with null values i.e. education (2409) and previous_year_rating (4124). Since both features were categorical, null values were replaced using mode.
Next, I checked for duplicates. As dataset before and after dropping duplicates were same length, duplicates removal wasn't required.
To handle outliers, I created a histograms of 4 ratio features: no_of_trainings, age, length_of_service and avg_training_score.
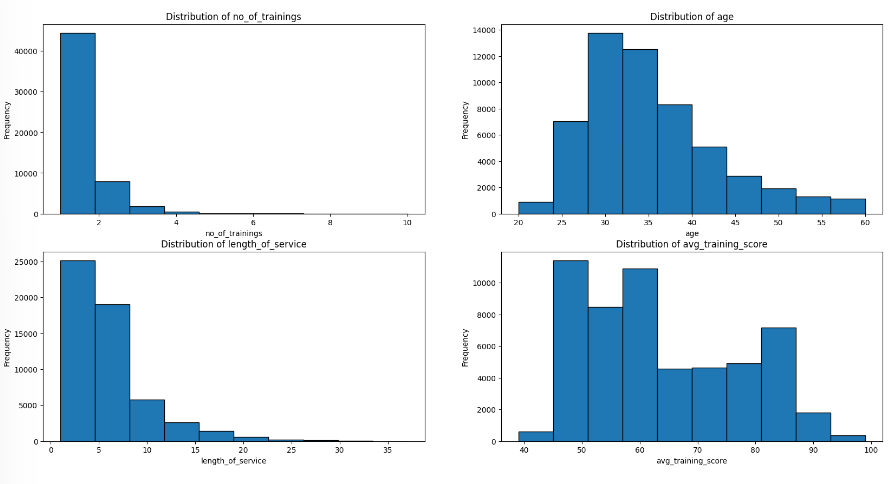
No, outliers were detected through visual analysis.
employee_id was only indexing feature in dataset which was removed.
We then checked the values in each feature and found out previous_year_rating was float64 which should be int64.

In final step of data preprocessing, previous_year_rating's datatype was converted to int64.
Exploratory Data Analysis
The preprocessed dataset looked unevenly distributed. Promoted employees were making only 8.5% of total records.
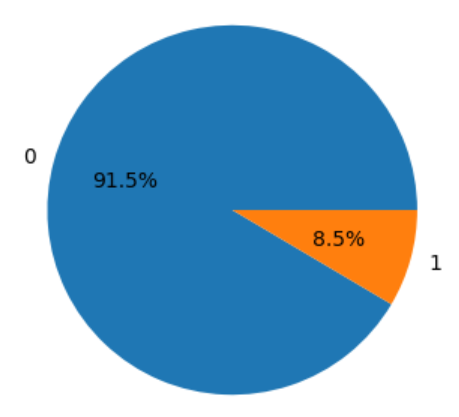
So, oversampling was needed for both binary classes making up 50-50% of dataset.
For oversampling, we divided dataset into minority and majority classes and used resampling to repeat minority class records until dataset was evenly distributed. Finally, new dataframe was created by concatenation of majority class and oversampled minority class datasets.
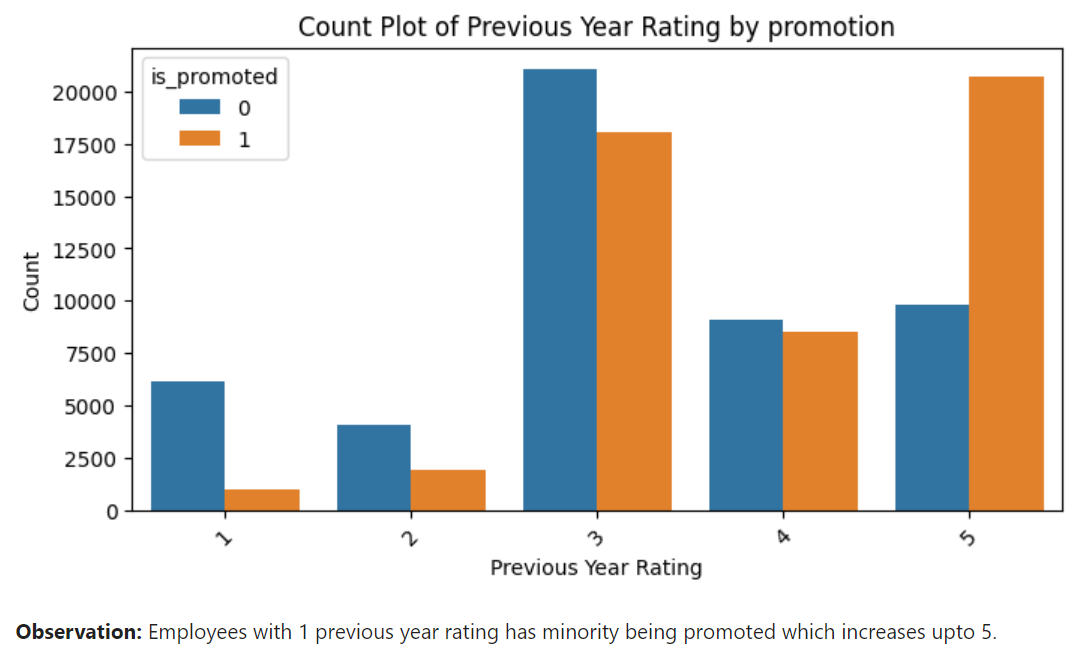
from sklearn.utils import resample minority_class = df[df['is_promoted'] == 1] majority_class = df[df['is_promoted'] == 0] oversampled_minority = resample(minority_class, replace=True, n_samples=len(majority_class), random_state=42) odf = pd.concat([majority_class, oversampled_minority])Then, we performed data visualizations for every feature in oversampled dataset and found previous_year_rating, awards_won? and avg_training_score having high relationship with output feature 'is_promoted'.
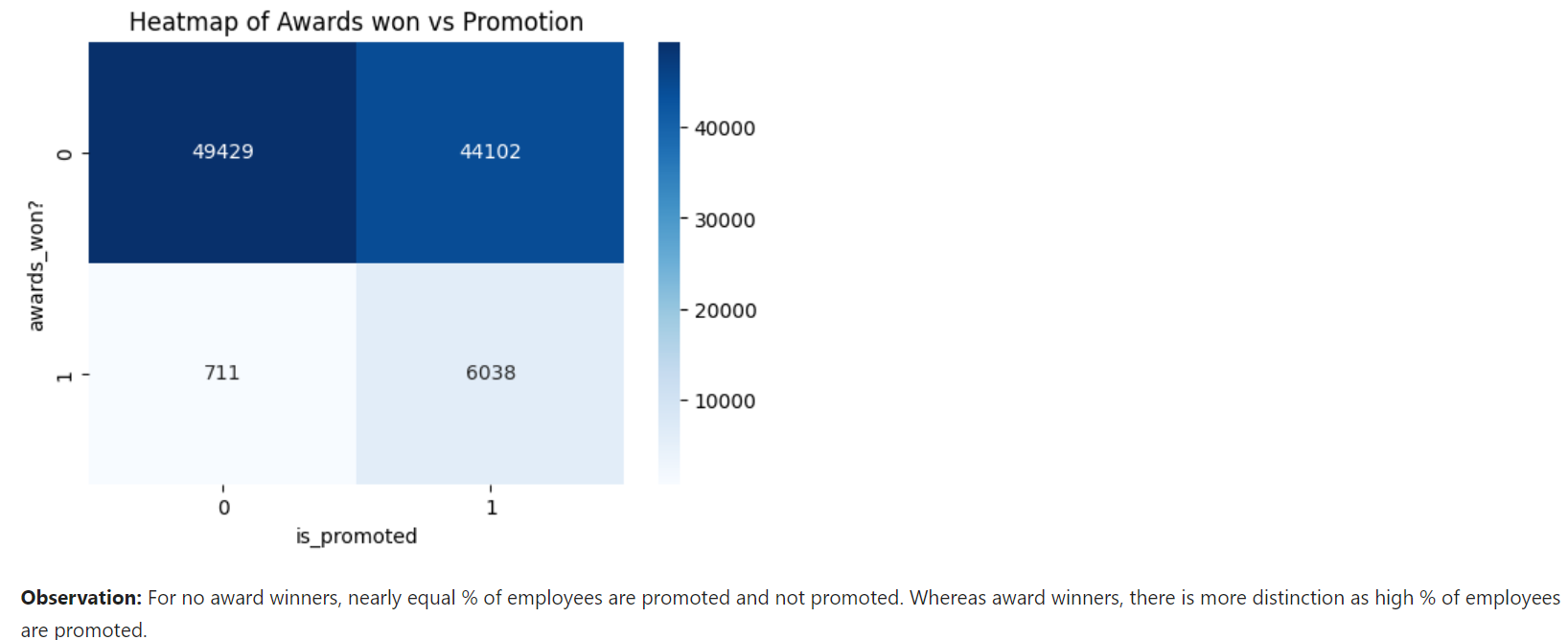
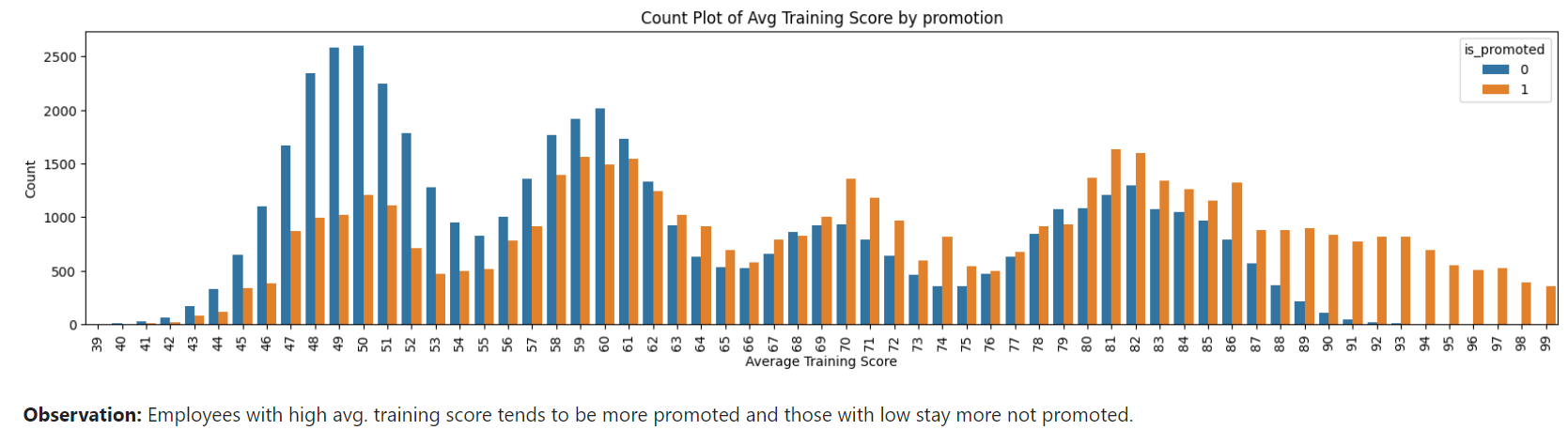
Feature Engineering
education was ordinal feature and gender was binary. So, both were label encoded.
3 nominal features department, region and recruitment_channel were one-hot encoded.
Columns after one-hot encoding were renamed and converted into int64 datatype.
Columns of 3 nominal features were removed as all corresponding values were columns now.
All features were scaled using min-max scaling from 0 to 1.
To select the important features related to 3 nominal features, correlation matrices were used.
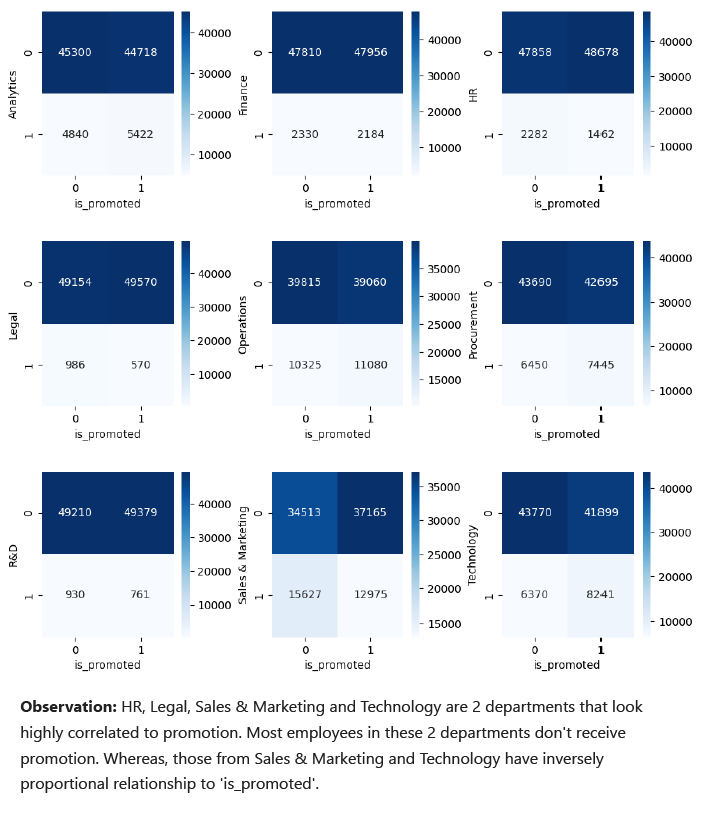

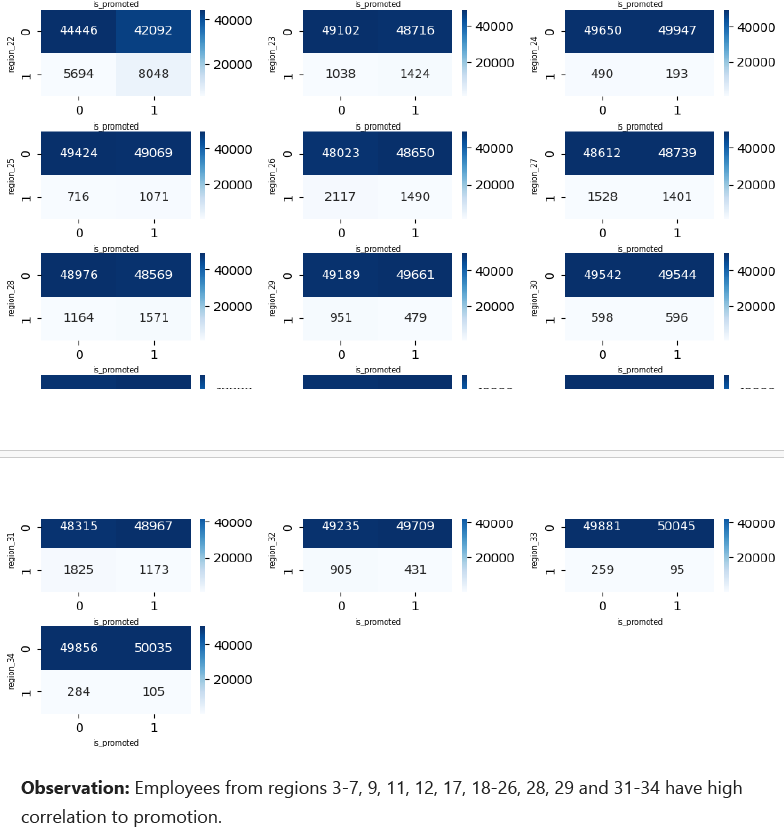
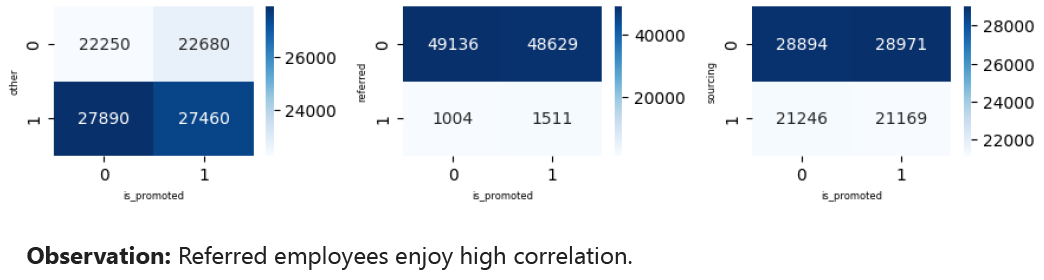
Also, correlation based heatmap of other features were created.
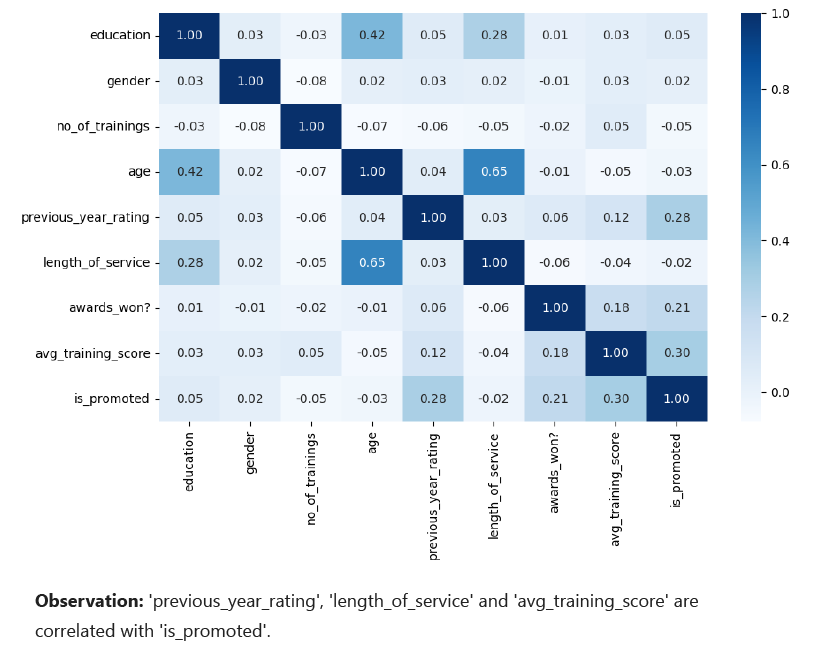
Based on these correlations, important_features were selected including HR, Legal, Sales & Marketing, Technology, region_3, region_4, region_5, region_6, region_7, region_9, region_11, region_12, region_17, region_18, region_19, region_20, region_21, region_22, region_23, region_24, region_25, region_26, region_28, region_29, region_31, region_32, region_33, region_34, referred, previous_year_rating, length_of_service and avg_training_score.
Model Building and Evaluation
I separated the dataset into X (for important_features) and y (for is_promoted) and divided training and testing dataset with stratification for y and test size of 0.3.
Model creation was separate through different imports in all 6 algorithms but model fitting and prediction always remains same. Decision Tree isn't considered ensemble because it never involves aggregation of multiple models like rest.
Decision Tree: This model splits the dataset into subsets based on input features and creates tree-like structure for making decisions.
from sklearn.tree import DecisionTreeClassifier dt_classifier = DecisionTreeClassifier(min_samples_split=10,max_depth=3) dt_classifier.fit(X_train, y_train) y_pred = dt_classifier.predict(X_test)Bagging Classifier: It involves training multiple models independently on random subsets and aggregating them through voting/averaging.
from sklearn.ensemble import BaggingClassifier bg_classifier = BaggingClassifier(DecisionTreeClassifier(min_samples_split=10,max_depth=3),max_samples=0.5,max_features=1.0,n_estimators=10)AdaBoost Classifier: This classifier iteratively trains the weak classifier on the training dataset with each successive classifier increasing weightage to the misclassified data points.
from sklearn.ensemble import AdaBoostClassifier adab_classifier = AdaBoostClassifier(DecisionTreeClassifier(max_depth=3),n_estimators=100,learning_rate=0.5)Gradient Boosting Classifier: Here, many weak learners combine into strong learners, in which each new model is trained to minimize the loss function of the previous model using gradient descent.
from sklearn.ensemble import GradientBoostingClassifier gb_classifier = GradientBoostingClassifier(n_estimators=100)Random Forest Classifier: This combines functions of multiple decision trees for final prediction.
from sklearn.ensemble import RandomForestClassifier rf_classifier = RandomForestClassifier(n_estimators=300,max_depth=3)Voting Classifier: It involves aggregation of different types of algorithms like logistic regression, multinomial naive bayes and support vector classifier below.
from sklearn.naive_bayes import MultinomialNB from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.ensemble import VotingClassifier mnb = MultinomialNB() lr = LogisticRegression(max_iter=5000) svc = SVC(max_iter=5000) vot_classifier = VotingClassifier(estimators=[('mnb', mnb),('lr', lr),('svc', svc)])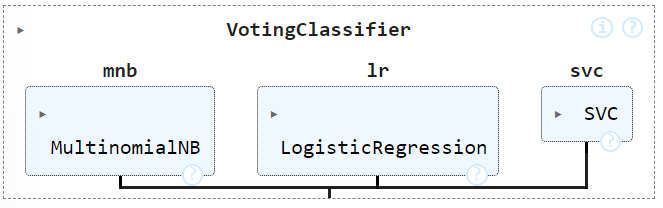
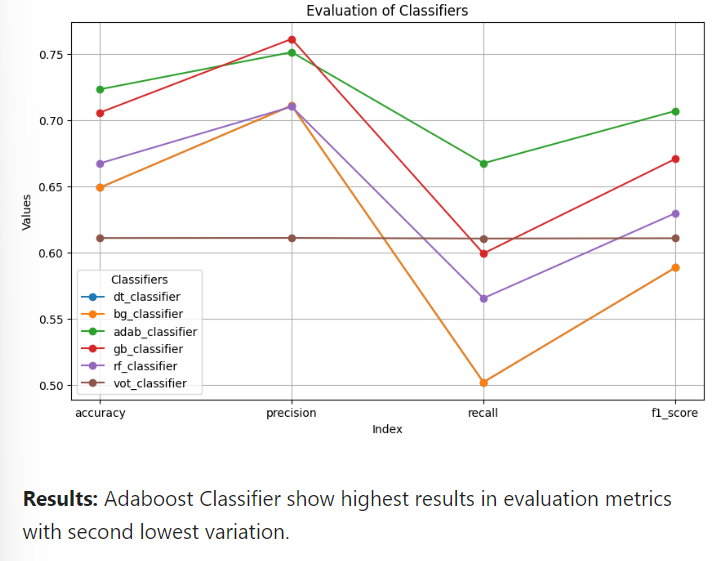
Finally, graph was created to compare between all 6 algorithms.
Model Saving
joblib library was used for exporting model as .sav file.
import joblib joblib.dump(adab_classifier, 'final_model.sav')
Result & Conclusion
To summarize, this project compared the performance of decision tree and 5 ensemble learning algorithms for binary classification problem of employee promotion prediction. Adaboost Classifier showed best evaluation with accuracy 0.723, precision 0.751, recall: 0.667 and f1-score of 0.707.
The project can be more detailly viewed and tested through github: https://github.com/ArpanMahatra1999/Employee-Promotion-Prediction
The exported .sav file was also used for streamlit web deployment: https://employee-promotion-prediction.streamlit.app/
References
“HR Analytics: Employee Promotion Data.” Www.kaggle.com, www.kaggle.com/datasets/arashnic/hr-ana.
“Implementing the AdaBoost Algorithm from Scratch.” GeeksforGeeks, 16 Mar. 2021, www.geeksforgeeks.org/implementing-the-adaboost-algorithm-from-scratch/.
GeeksForGeeks. “ML - Gradient Boosting.” GeeksforGeeks, 25 Aug. 2020, www.geeksforgeeks.org/ml-gradient-boosting/.
Subscribe to my newsletter
Read articles from Arpan Mahatra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by