Series 2/6: Understanding Large Language Models: A Game Changer in Data Extraction
 Pramod Gupta
Pramod Gupta
What are Large Language Models (LLMs) and How Do They Work?
Large Language Models (LLMs) are advanced artificial intelligence systems designed to understand and generate human-like text based on vast amounts of training data. They are built using deep learning techniques, particularly the transformer architecture, which allows them to handle complex language tasks with high efficiency and accuracy.
How LLMs Work
Training on Large Datasets: LLMs are trained on extensive datasets comprising diverse sources such as books, articles, websites, and more. This training helps the models learn the nuances of human language, including syntax, semantics, and context.
Transformer Architecture: The transformer model is the backbone of most LLMs. It uses self-attention mechanisms to process input data, allowing the model to weigh the importance of different words in a sentence and understand their relationships. This architecture enables the generation of coherent and contextually appropriate text.
Fine-Tuning: After initial training, LLMs can be fine-tuned on specific datasets to improve their performance for targeted tasks. This fine-tuning process adjusts the model to better handle the unique characteristics of the data it will encounter in real-world applications.
Advantages of Using LLMs Over Traditional Extraction Methods
Flexibility and Adaptability:
- LLMs can manage a wide variety of document formats and structures without needing predefined rules or templates, making them suitable for extracting data from diverse document types.
Contextual Understanding:
- Traditional methods often struggle with unstructured data, but LLMs excel at understanding the context and semantics of the text. This capability allows for accurate extraction of relevant information from complex or poorly structured documents.
Scalability:
- LLMs can be scaled to handle large volumes of data and numerous document types. Their ability to generalize from extensive training datasets enables them to perform well across different domains and industries.
Reduced Maintenance:
- Unlike traditional extraction methods that require frequent updates and maintenance, LLMs need less frequent retraining, significantly reducing operational burdens and costs.
Improved Accuracy:
- LLMs achieve higher accuracy in data extraction tasks due to their deep learning foundations and extensive training on diverse datasets. Their ability to capture intricate patterns and relationships in text contributes to this improved performance.
Transformer Architecture
The transformer architecture, introduced by Vaswani et al. in 2017, revolutionized NLP with its ability to process text more efficiently than previous models like RNNs and LSTMs. It consists of an encoder-decoder structure, both built using layers of self-attention mechanisms and feed-forward neural networks.
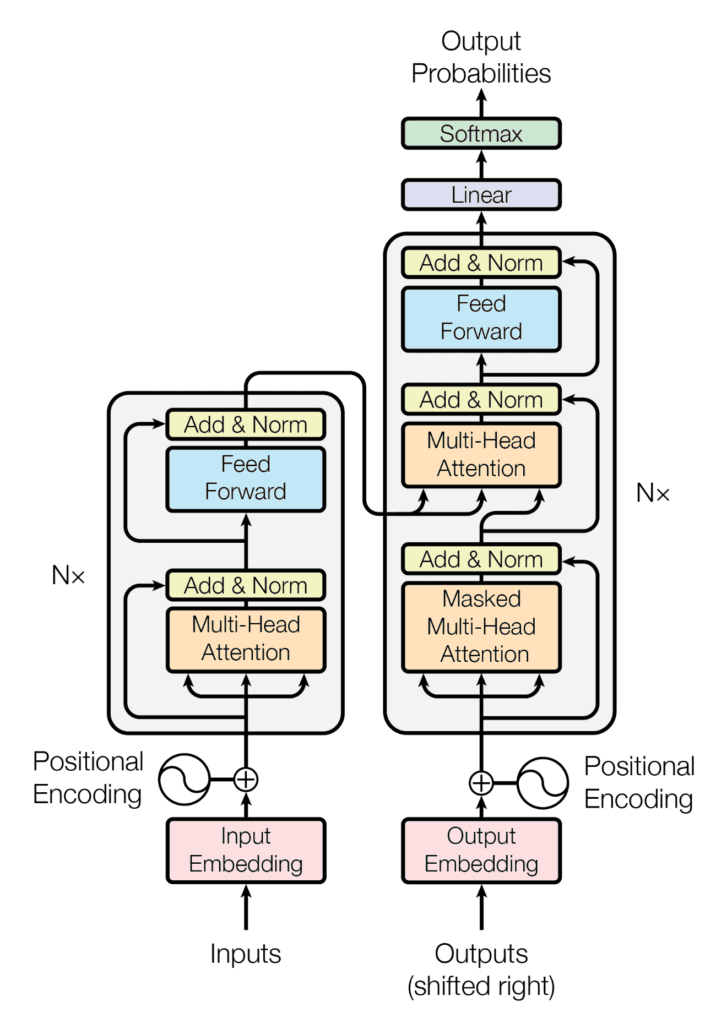
Encoder: The encoder's role is to read the input sequence and generate a set of continuous representations. It consists of multiple identical layers, each containing two main components:
Self-Attention Mechanism: This allows the encoder to consider the entire input sequence when processing each word, helping it understand the context and relationships between words. The self-attention score for each pair of words in the input sequence is calculated as:

where Q (query), K (key), and V (value) are derived from the input embeddings, and d is the dimensionality of the key vectors.
Feed-Forward Neural Network: After the self-attention mechanism, a fully connected feed-forward network processes each position independently and identically, adding non-linearity to the model.
Decoder: The decoder generates the output sequence by predicting one word at a time, using the encoded input and previously generated outputs. It also consists of multiple identical layers, each with three main components:
Masked Self-Attention Mechanism: Similar to the encoder's self-attention but with masking to prevent the decoder from attending to future positions in the sequence, ensuring the model only considers past and present words.
Encoder-Decoder Attention: This mechanism allows the decoder to focus on relevant parts of the input sequence by attending to the encoder's output, facilitating the transfer of contextual information.
Feed-Forward Neural Network: As in the encoder, this network processes each position independently, adding non-linearity to the model's predictions.
Key Players in LLM Research: GPT-3.5, LLAMA, and Google BARD
GPT-3.5:
- Developed by OpenAI, GPT-3.5 is one of the most advanced LLMs. It has been trained on a vast dataset that includes a wide range of text sources, enabling it to generate high-quality text and perform various NLP tasks with remarkable accuracy. GPT-3.5's versatility and robustness make it an excellent choice for data extraction applications.
LLAMA:
- LLAMA (Large Language Model Architecture) is another prominent LLM that has shown significant potential in natural language processing tasks. Utilizing a transformer architecture similar to GPT-3.5, LLAMA excels at understanding and generating text effectively. Its performance in data extraction tasks has been impressive, making it a valuable tool for this research.
Google BARD:
- Google BARD (Bidirectional and Auto-Regressive Transformers) is an LLM developed by Google that combines the strengths of bidirectional and autoregressive models. This hybrid approach allows BARD to excel in understanding context and generating accurate text. Its application in data extraction tasks has demonstrated its capability to handle complex document structures and extract relevant information efficiently.
Example Use Case: Document Data Extraction with LLM
Imagine an organization needing to extract data from various tax forms, such as W-2, W-8, and W-9. Traditional methods would require creating specific rules or templates for each form type, which is labor-intensive and prone to errors. By using GPT-3.5, the organization can leverage the model's contextual understanding and flexibility to extract relevant information efficiently.
Process:
Input: The raw text or scanned images of the tax forms are preprocessed and fed into GPT-3.5.
Encoding: GPT-3.5's encoder processes the input, understanding the context and structure of the document.
Extraction: The model generates structured data outputs by identifying and extracting key fields such as names, addresses, tax identification numbers, and financial details.
Benefits:
Accuracy: GPT-3.5 can accurately extract data even from poorly structured or varying document formats.
Efficiency: The model automates the extraction process, reducing the need for manual data entry and validation.
Scalability: GPT-3.5 can handle large volumes of documents, making it suitable for organizations with significant data processing needs.
Conclusion
Large Language Models (LLMs) represent a groundbreaking advancement in the field of document data extraction. Their ability to understand context, adapt to various document formats, and scale effectively makes them far superior to traditional extraction methods. By leveraging advanced models like GPT-3.5, LLAMA, and Google BARD, organizations can achieve higher accuracy and efficiency in their data extraction processes, ultimately transforming how they handle and process information.
Coming Up Next
Stay tuned for more insights in our upcoming blog posts, where we delve deeper into the methodologies and performance of these models in real-world data extraction scenarios.
Blog Post 3: Practical Applications and Case Studies of LLM-Based Data Extraction
Real-World Applications of LLMs in Document Data Extraction
Case Studies Highlighting the Success and Challenges
Future Prospects and Innovations in LLM Research
For a more detailed exploration of this topic, including methodologies, data sets, and further analysis, please refer to my Master's Thesis and Thesis Presentation.
LinkedIn link - https://www.linkedin.com/in/pramod-gupta-b1027361/
Subscribe to my newsletter
Read articles from Pramod Gupta directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Pramod Gupta
Pramod Gupta
As a Technical Lead specializing in the financial industry, I specialize in developing cutting-edge solutions leveraging machine learning, deep learning, computer vision, and the Azure cloud. My journey with this global leader in banking and finance began in December 2021, following a successful tenure as an AI Lead Engineer at Future Generali India Life Insurance for over three years. My academic foundation includes a bachelor's degree in computer engineering and ongoing pursuit of a master's degree in machine learning and AI from Liverpool John Moores University. Complementing these, I hold multiple certifications in Python, Java, and data science, underscoring my commitment to staying at the forefront of technological advancements. Throughout my career, I've delivered impactful projects in the insurance and banking sectors, applying AI technologies such as Angular, NoSQL, and XML. Notably, I've been recognized with two CEO awards for my contributions to the IVR project and the customer retention initiative, achieving a remarkable 40% increase in response rates and 25% improvement in retention rates. Driven by a passion for solving complex challenges, I continually seek opportunities to expand my skills, embrace new tools and techniques, and collaborate effectively within diverse teams. My overarching goal is to leverage my expertise to drive innovation and create substantial value for both my organization and society at large.