Notes of Spring Microservices in Action (Chapter 10)
 Can Okan Taşkıran
Can Okan Taşkıran
This chapter covers spring-based microservice communication with other microservices using asynchronous messages. This concept is known as event-driven architecture (EDA) or message-driven architecture (MDA). You can build highly decoupled systems that react to changes without being tightly coupled to particular services.
Event-driven architecture lets us swiftly integrate new functionality into our application by just having the service listen to the stream of events (messages) emitted by our application.
Spring Cloud Stream simplifies the implementation of message publication and consumption without worrying about the complexities of the underlying messaging platforms.
The case for messaging, EDA, and microservices
Let's imagine that there are two services, X and y, and the X service has to call the Y service to complete the operation. However, the X service calls take an extremely long time when looking up information from the Y service. An examination of the y data usage patterns reveals that changes to the data are too rare, and the primary method of accessing data from the y is the same. So, if we could cache the reads from the Y service data without shouldering the cost of accessing a database, we could significantly improve the response time of the X service calls.
There are several considerations for implementing a caching solution:
A local cache introduces complexity. We have to guarantee our local cache is in sync with all of the other services in the cluster. Cache data have to be consistent across all instances of the services.
When the Y service changes its record via an update or delete, we want other services to recognize those changes. So, the X service should invalidate any cached data for that specific Y service and evict it from the cache.
There are two approaches to implementing these requirements:
Using a synchronous request-response model. When the Y service state changes, the X and the Y will communicate back and forth via their REST endpoints.
The second approach is that the Y service publishes an asynchronous event (message) to communicate that its data has changed. The other services listen with an intermediary (message broker or queue) to determine if an event occurred from the Y service and, if so, clear the data related to the Y service from its cache.
10.1.1 Using a synchronous request-response approach to communicate state changes
Throughout the article, Redis, a distributed key-value store, is going to be used as a cache.
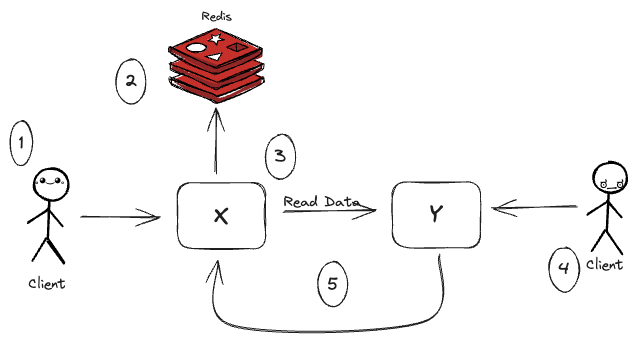
In the figure, when a client calls the X service, the X service has to look up the Y data. To do that, the X service first retrieves the required Y service data by its ID from a Redis cluster. If the X can't find the required data, it will call the Y service using a REST-based endpoint, storing the data returned in Redis.
If another client updates or deletes the Y service data using the Y service's REST endpoints, the Y service will need to call an endpoint exposed on the X service to tell the other service to invalidate the Redis cache.
There are several problems with this approach:
The services (in this example, x and y) are tightly coupled, introducing brittleness between them.
If the X service endpoint for invalidating the cache changes, the Y service has to implement changes also. This is a pretty inflexible way of developing services.
You can't introduce a new consumer of the Y service data without modifying the code on the Y service to ensure that it calls the new consumer to invalidate the cache.
Tight Coupling Between Services
The X service is dependent on the Y service to execute operations, and the Y service directly communicates back to the X service when a Y service record is updated or deleted. It introduces coupling from the Y service back to the X service.
There are two ways to invalidate data in the Redis cache. Either the X service is going to expose the endpoint to invalidate its cache by the Y service, or the Y service needs to access directly the Redis server owned by the X service to clear/update the data in it. Direct access to the data store of another service is a practice that should be strictly avoided in a microservice environment. If the Y service directly does operations to the Redis service, it can accidentally break the rules implemented by the team owning the X service.
Brittleness Between The Service
The tight coupling between services also introduces brittleness. Scenarios when the X service is down or running slowly can impact the Y service. Again, if the Y service directly accesses the X service's Redis data store, we create a dependency between the organization service and Redis. In this situation, any problem with the shared Redis server now has the potential to take down both services.
10.1.1 Using messaging to communicate state changes between services
We are implementing a messaging system (topic) between the X service and the Y service. The primary purpose of this messaging system is not to read data directly from the Y service. Instead, it will be used exclusively by the Y service to publish any state changes within the data it manages.
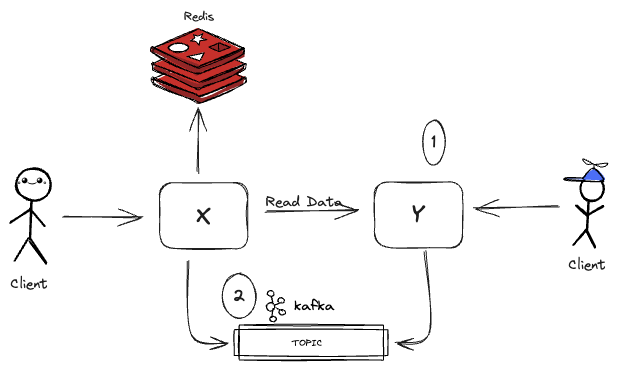
When Y service data changes, the Y service publishes a message to a topic. The X service monitors the topic for messages, and when a message arrives, it clears the appropriate Y record from the Redis cache. The message queue works as an intermediary between the X and Y service. This method provides four benefits: loose coupling, durability, scalability, and flexibility.
Loose Coupling
We experienced that the synchronous design proposed a hard dependence between the X and Y services. A messaging approach lets us decouple these two services because both services are unaware of each other when it comes to exchanging information about state changes. When the Y service needs to notify a state change, it publishes a message to a queue. The X service only knows that it gets a message; it doesn't know who published it.
Durability
The presence of the messaging broker guarantees that a message will be delivered even if the service's consumer is down. The messages are stored in the queue and stay there until the X service becomes available. Moreover, if the Y service is down, the X service can degrade gracefully because at least part of the Y data will be stored in its cache.
Scalability
The message publisher doesn't have to wait for a response from the consumer because published messages are stored in a queue. If the consumer can't process messages quickly enough, more consumers can be added to handle the load, providing scalability. This approach fits well with the microservices model, where deploying new service instances to consume messages is easy. Unlike traditional scaling mechanisms that scale by increasing the number of threads (limited by CPU capacity), the microservice model scales by adding more machines hosting the service, avoiding CPU limitations and enabling horizontal scaling.
Flexibility
We can add new consumers to a queue with little effort and without impacting the original publisher service because the publisher of a message is irrelevant to the consumer. A new consumer can listen to published events and react to them accordingly its logic.
However, there are trade-offs to consider in a message-based architecture.
Message-Handling Semantics
A message-driven system requires analyzing how the application will behave based on the order in which messages are consumed and the impact of processing messages in the out of order. When using messaging to enforce strict state transitions, designing applications to handle exceptions and out-of-order messages is crucial. Critical scenarios to consider include deciding whether to retry failed messages or let them fail and determining how to manage future messages related to a customer if one of their messages fails. These are essential issues to address in the application design.
Message-Handling Semantics
In the asynchronous messaging environment, messages may not be received or processed immediately after being published or consumed due to their asynchronous nature. Additionally, having unique identifiers like correlation IDs to track users' transactions across service calls and messages is essential for understanding and debugging the application's behavior.
Message Choreography
Message-driven applications are complex to cover because their business logic isn't processed in a linear manner like in a simple request-response model. Debugging these applications requires examining logs from multiple services, where a transaction can be executed out of order and at different times.
References
[1]Spring Microservices in Action, 2nd Edition, John Carnell.
https://www.manning.com/books/spring-microservices-in-action-second-edition
[2] "Event Sourcing Pattern" on Microservices.io
https://microservices.io/patterns/data/event-sourcing.html
Subscribe to my newsletter
Read articles from Can Okan Taşkıran directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by