K-Means Clustering - Unsupervised Learning
 Retzam Tarle
Retzam Tarle
print("Unsupervised Learning - Clustering")
Clustering in unsupervised learning is the act of grouping unlabelled data. This is the core of unsupervised learning as we learned in the previous chapter: Unsupervised Learning.
In unsupervised learning, we implement clustering using the technique/model called K-Means Clustering.
K-Means Clustering
K-Means clustering computes clusters of unlabelled data. This computes K(This is any number) clusters from the data. To run K-Means clustering one would need to predefine K. For example, to create 3 groups from unlabelled data using K-Means would mean defining k=3.

Below are the steps to create a K-Means cluster:
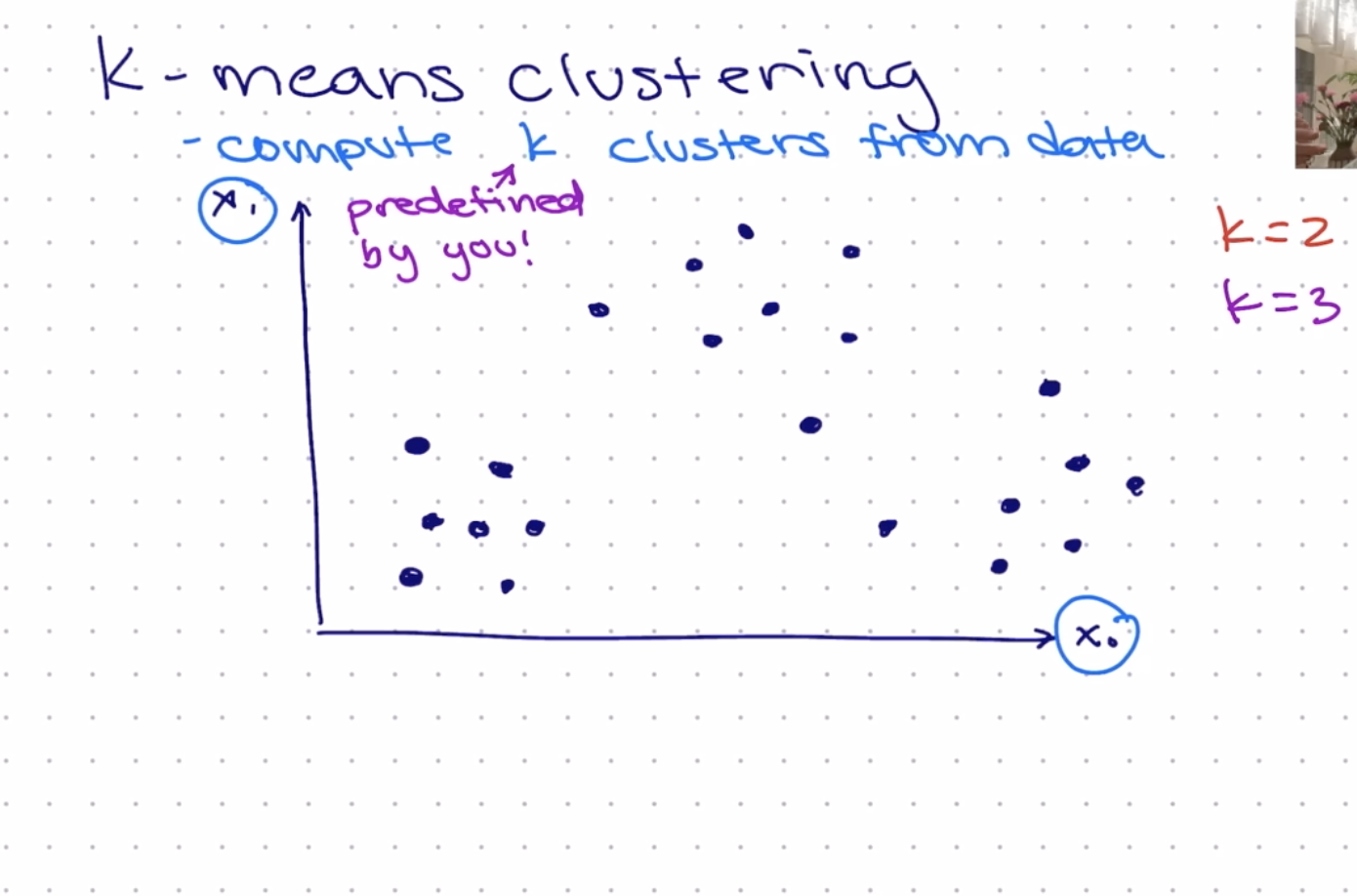
Compute K clusters: From the unlabelled data, K is predefined by the person running the clusters. Consider the 2D illustration below showing K defined as K=2 or K=3. This means we want to group this unlabelled data into two/three groups/clusters.
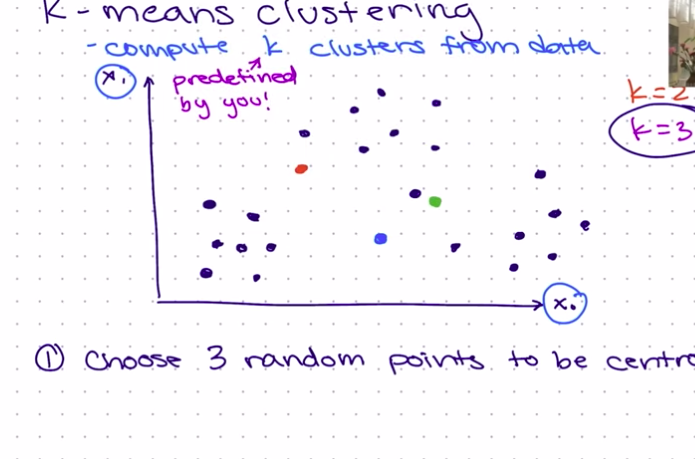
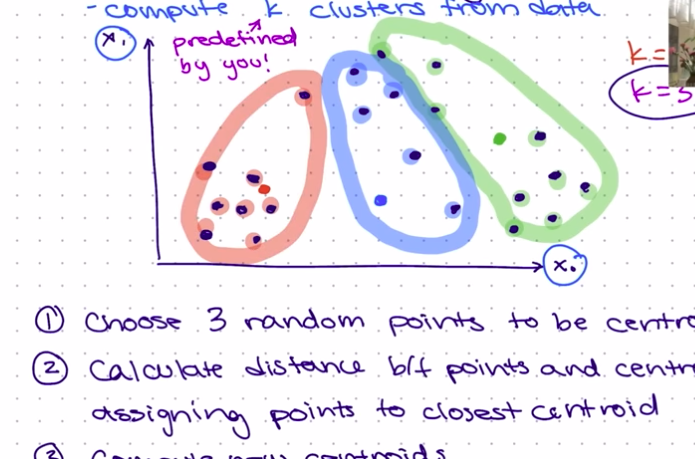
Choose K random points to be centroids: These centroids would be the center of the clusters. The illustration using K=3 below shows 3 random points selected, with red, blue, and green colors.
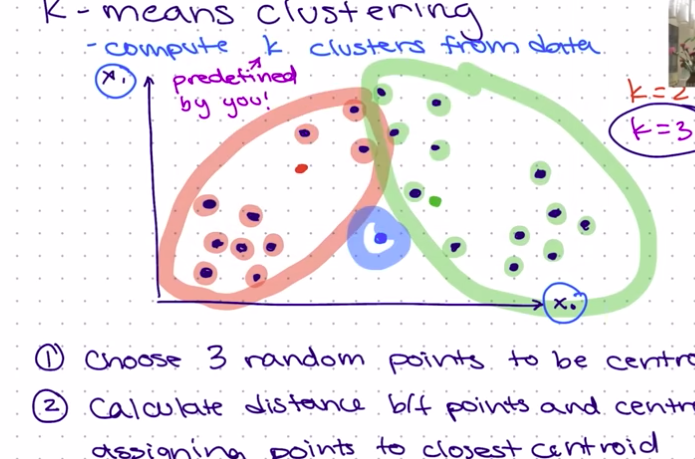
Calculate the distance between points and centroids: This step involves assigning points to the closest centroid, also known as the Expectation step. The illustration below shows this, we can see that we created 3 clusters based on each point's distance from the centroids. This is using K=3.
Compute new centroids: This is called the Maximization step based on the points we have. In the illustration in step 4, we can see that the third cluster does not have any point. The aim of the Maximization step is to try to balance the clusters as much as possible, using an iterative process, until each cluster is deemed well-balanced. So using the previous positions we'll adjust our K points accordingly as shown below.
We'll do this iteratively until we have something like the illustration shown below:
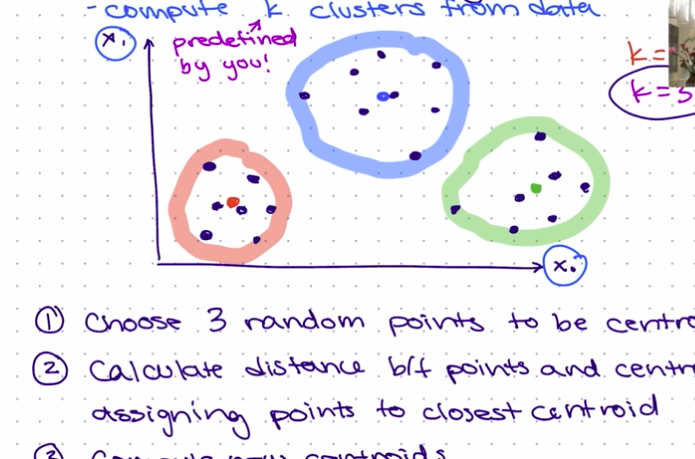
When we reach a stage where the points in each cluster are no longer changing, that is they are stable, we can conclude that we've gotten our final 3(K) clusters.
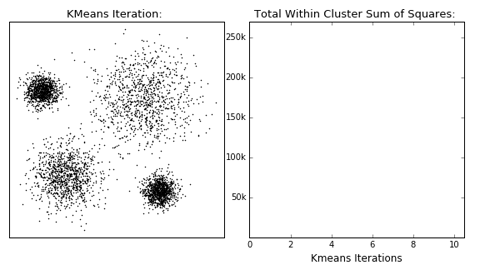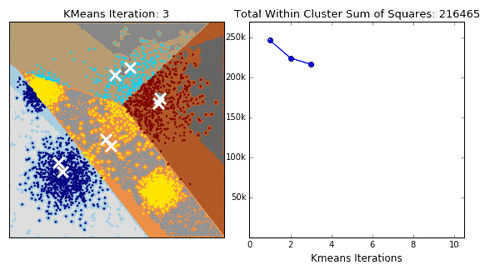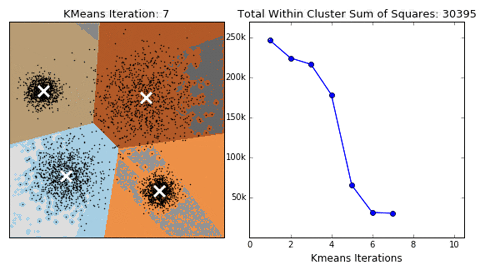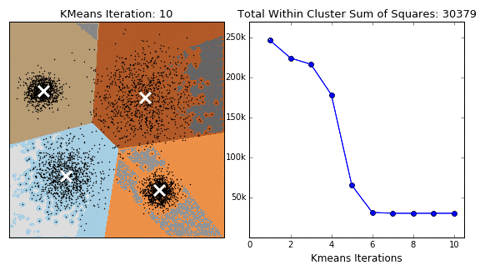
The last two points in the steps mentioned above are known as Expectation-Maximization.
You can watch this short Youtube video here, for more clarity.
With this, we have clearly explained the idea behind K-Means clustering and clustering in supervised learning tasks 🙂. We'll practically build and deploy a model based on this in a later chapter, so stay tuned! 🎮
In our next chapter, we'll talk about Dimensionality Reduction.
Till next time, au revoir 👽.
Subscribe to my newsletter
Read articles from Retzam Tarle directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Retzam Tarle
Retzam Tarle
I am a software engineer.